今天抽点时间讲讲环境的问题,对于算法工程师而言,开发环境往往都是最容易被轻视,但是最容易被拖后腿的东西,这个文章主要讲讲如何依据spark环境搭建jupyter的算法开发环境。
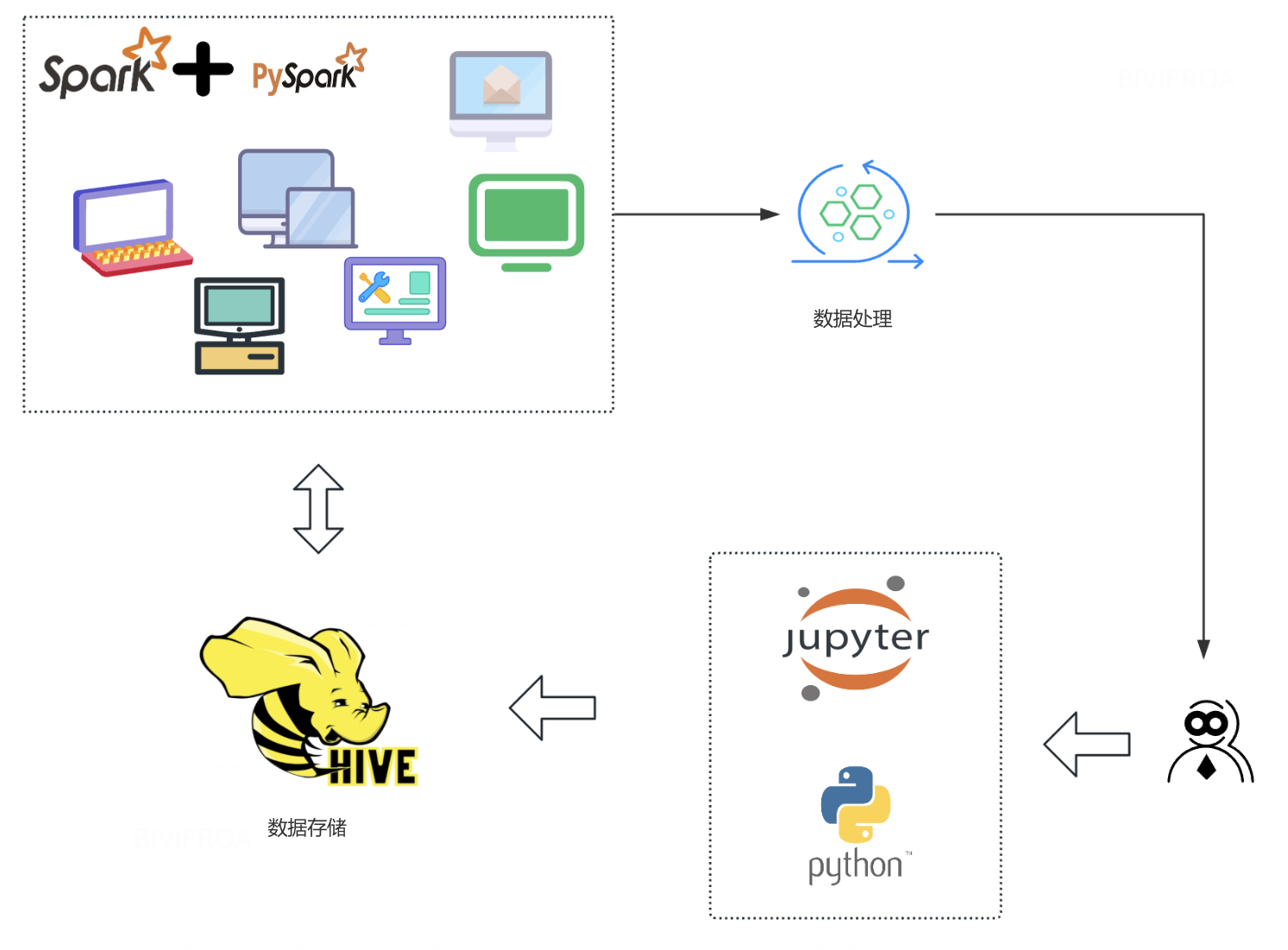
上图基本呈现了一个业务算法比较常用的开发框架, 通过spark+pyspark进行数据处理, 然后在强悍的物理机上进行算法的开发,当然一些简单的算法也可以在spark环境进行学习。 那么作为一个算法工程师, 你知道怎么搭建这么一套环境么?
安装过程
需要在客户端安装python环境, 并且这个python环境要上传到spark集群中, 因为当你开发udf的时候, 要保持python版本的一致才能比较好的开发。
围绕这个安装目标, 然后就来一步一步的推进啦。
本地编译python环境
这里可以找到你想要的python版本(https://www.python.org/downloads/),不过这里有个提醒, 不要选择过新或者过旧的版本,否则后患无穷。假设你已经下载了你心仪的python版本。下面就要找个地方编译安装了。
tar -xvf python3.10.17.tgz
cd python3.10.17
./configure --prefix=/path/to/python3.10.17 --with-openssl=/usr/local/openssl
–with-openssl=/usr/local/openssl这个选项十分重要, 要不会导致你的pip不好用, 访问不了https。
养兵千日
这个python可是个宝贝,我们不仅要本地用,一会儿还要上传到hdfs目录给集群用呢,所以这一步就要养这个环境。
/python3.10.17/bin/pip3 install xgboost -t /python3.10.17/lib/python3.10/site-packages
这一步可以先升级一下pip环境。
出去历练
养好这个python环境,就要把它弄到hdfs上去, 这样集群就都能使用这个python环境啦。
cd python3.10.17
tar -zcf python3.10.17.tgz *
hdfs dfs -put python3.10.17.tgz hdfs://path/share/dir
用兵一时
设置conf/spark-defaults.conf
spark.yarn.dist.archive hdfs://path/share/dir/python3.10.17.tgz#python310
spark.executorEnv.LD_LIBRARY_PATH /usr/local/hadoop-current/lib/native:./python310/lib:$LD_LIBRARY_PATH
spark.yarn.appMasterEnv.PYSPARK_PYTHON=./python310/bin/python3.10
这个python310是给这个环境起的别名,方便后续使用。
配置conf/spark-env.sh
export PYSPARK_DRIVER_PYTHON=/home/lxxx/python-3.10.17/bin/python3.10
export PYSPARK_PYTHON=./python310/bin/python3.10
启动命令
配置到这里,环境应该是可以使用的,这个时候我们需要一个命令启动jupyter,并让jupyter后面的环境能够连接到spark进行数据处理的任务。
nohup pyspark --conf spark.sql.repl.eagerEval.enabled=True --conf spark.yarn.dist.archives=hdfs://DClusterUS1/user/prod_soda_delivery_strategy/taojiucheng/python3.10.17.tgz#python310 --conf spark.pyspark.driver.python=jupyter-notebook --conf Spark.url=http://usrm.intra.xiaojukeji.com/cluster --conf spark.driver.host=1.2.2.3 --conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./python310/bin/python3.10 --queue=root.soda_delivery_strategy_dev_prod > /dev/null 2>&1 &
这个命令比较全的把配置给出来,很多还是我们刚刚配置的, 这里主要想说明的是多个方式都能让这环境被使用。