马尔可夫决策过程提供了基本的理论框架,几乎所有的马尔可夫学习问题都可以使用MDP的决策过程建模。
而本节讲的贝尔曼方程是马尔可夫决策过程用到最基础的方程。贝尔曼方程方程也被称为动态规划方程,贝尔曼方程表达了当前值函数(或行为值函数)和它后继值函数的关系,以及值函数与行为函数之间的关系。而贝尔曼最优方程表达的是当前最优值函数和它后继最优值函数的关系,以及最优值函数和最优行为值函数之间的关系。听起来十分绕,不过咱们慢慢往下讲就可以了解这些内容。
最优策略策略的表示
状态-值函数(有何期望)
状态-值函数是表达每个状态下的值函数,物理含义是当处于状态S下,未来的预期收益应该是多少?
\begin{align*}\label{2}
& V_{\pi}(s)=E_{\pi}[G_t|S_t=s] \\
& =E_{\pi}[R_{t+1} + \gamma R_{t+2}+...|S_{t}=s] \\
& =E_{\pi}[R_{t+1}+\gamma(R_{t+2}+\gamma R_{t+3})|S_{t}=s] \\
& =E_{\pi}[R_{t+1}+\gamma G_{t+1}|S_{t}=s] \\
& =E_{\pi}[R_{t+1} + \gamma V(S_{t+1})|S_{t}=s] \\
\end{align*}
除了上面的表达,还可以有另一种表达
Vπ(s)=a∈A∑π(a∣s)s′,r∑p(s′,r∣s,a)[r+γvπ(s′)](1.1)
π表示一种策略,给定状态s,就给出动作a,p表示给定状态s和a,转移到s’获得收益r的概率,r表示即时收益,γvπ(s′)表示未来收益的加权和。
这里的状态-值函数通常被称为值函数。
动作-值函数(这样做,有何期望)
需要经常考虑的一个关键问题不仅仅是值函数问题,另一个描述的方式是当处在状态s的情况下选择动作的值函数的大小决定在当前状态下采取什么动作。
通过比较同一个策略下的不同动作,就可以选择更好的动作,从而改进策略。当我们关心改进策略的时候,我们就需要动作-值函数。可以进一步思考一下,对于值函数的学习,更多是静态环境的捕捉,但是对于相对的动调环境,就需要 动作-值函数捕捉环境的动态,进而改进策略。动作值函数的表达如下公式1.2
qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[Rt+γGt+1∣St=s,At=a]=s′,r∑p(s′,r∣s,a)[r+γvπ(s′)](1.2)
公式1.2的最后一行也是动作-值函数的贝尔曼方程的定义。
动作优势函数(如果这样做,有什么进步)
另一种值函数是有前两种值函数演变过来的。又称为优势函数,使用aπ(s,a),是指动作a在状态s中的动作-值函数与策略π下的状态s的状态值函数之差。
aπ(s,a)=qπ(s,a)−vπ(s)(1.3)
状态转换
接下来我们来看看状态值函数和动作值函数之间的关系。
基于状态s,采取动作a求Vπ(s)
在遵循策略π的情况下,状态s的值函数体现在该状态下采取所有可能行为值函数Q(s,a)为行为发生概率π(a∣s)的乘积之和。
Vπ(s)=a∈A∑π(a∣s)Qπ(s,a)(2.2)
采取行动a,状态转换为s’,求取Qπ(s,a)
Qπ(s,a)=Rsa+γa∈A∑Pss′aVπ(s′)(2.3)
基于状态s,采取行动a,转为状态s’,求取Vπ(s)
Vπ(s)=a∈A∑π(a∣s)(Rsa+γs′∈S∑Pss′aVπ(s′))(2.4)
采取行为a,状态转变为s‘,采取行动a’,求Qπ(s,a)
Qπ(s,a)=Rsa+γs′∈S∑Pss′aa∈A∑π(a′∣s′)Qπ(s′,a′)(2.5)
是不是太复杂啦,咱们还是举个例子来看看在实际的转移关系中怎么来算这些值。
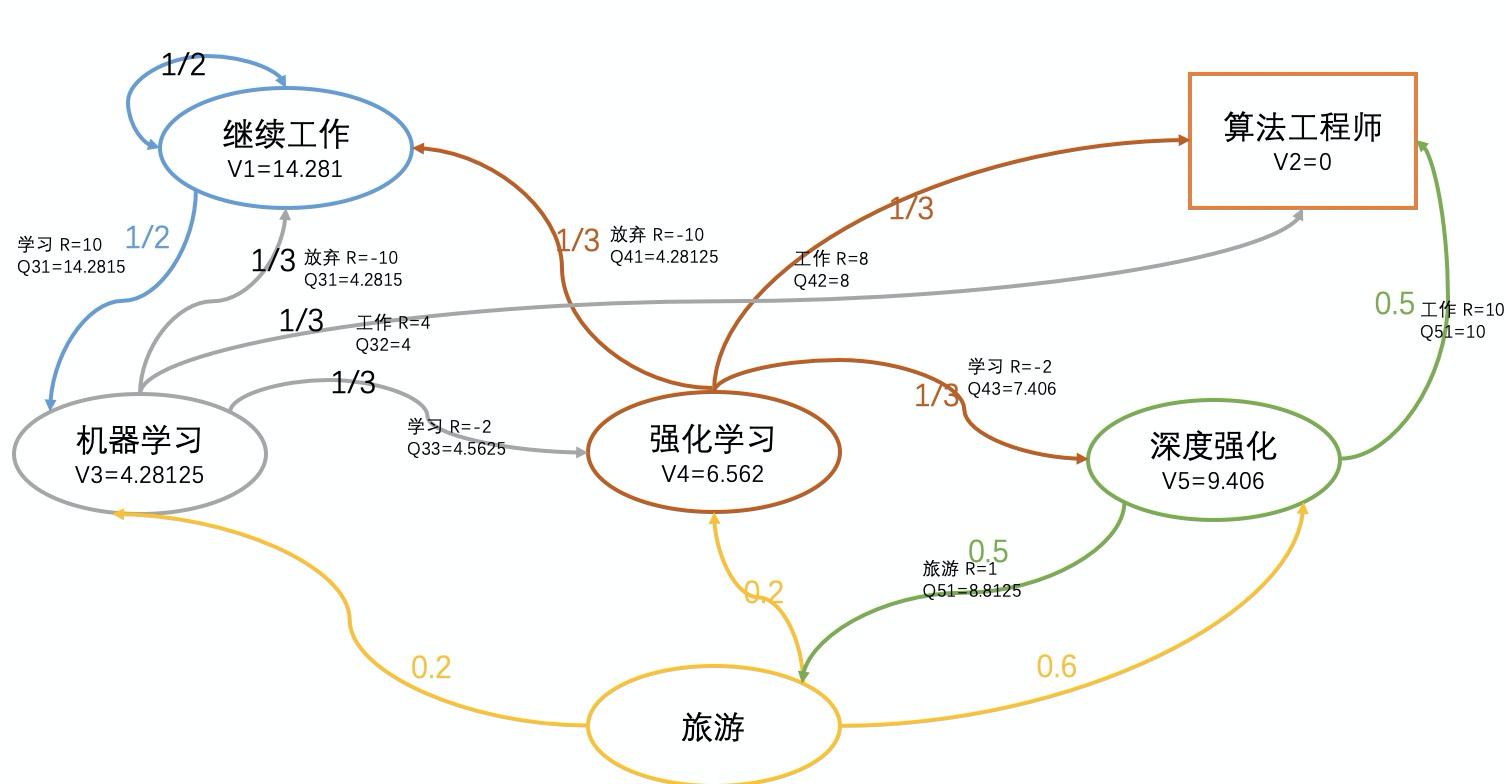
我们先来看看Vπ(s)和Vπ(s‘)的关系,假设选择强化学习,那么对应值函数V4表示当前状态值函数,V4的后继值函数分别是V1,V2,V5。已知V1,V2,V5
V4=31[(−10+1×1×V1)+(8+1×1×V2)+(−2+1×1×V5)]=6.56
上面公式可以对应公式2.4的 ′\gamma′和′P_{ss’}^{a}′.类似的大家可以验证以下其他的关系。
贝尔曼最优方程
贝尔曼最优方程表达是当前状态的最优值函数和后继的最优值函数的关系。
V∗(s)=max Vπ(s)(2.6)
Q∗(s,a)=max Qπ(s,a)(2.7)
基于状态s采取行动a,求V∗(s)
当前状态的值函数V∗(s)等于从该状态s出发,采取所有行动中对应的那个最大行为值函数
V∗(s)=max Q∗(s,a)(2.8)
采取行动a,状态转变为s‘,求取Q∗(s,a)
在某个状态下,采取某个行为的最优价值Q∗(s,a)有两部分构成,一部分是离开状态s立即回报Rsa,另一个部分是能够到达s’的最优状态价值V∗(s)出现概率的总和。
Q∗(s,a)=Rsa+γs′∈S∑Pss′aV∗(s′)(2.9)
基于状态s,采取行动a,状态转变为s‘,求V∗(s)
V∗(s)=max Rsa+γs′∈S∑Pss′aV∗(s′)(2.10)
采取行动a,状态转变s’,采取行动a‘,求Q∗(s,a)
Q∗(s,a)=Rsa+γs′∈S∑Pss′amaxQ∗(s′,a′)(2.11)
最优策略
讲到这里,强化学习的基本理论就差不多啦,我们来回头看看强化学习的形式化描述。M=<S,A,P,R,γ>,这里我们就不一一介绍啦,之前应该都介绍过每个符号的意义。这里介绍两个新的概念。T为总的时间步,τ叫做轨迹序列,τ=(s0,a0,r0,s1,a1,r1....),对应的累积回报为R=∑t=0Tγkrt。那么强化学习的目标就是找到最优的策略π,该策略累积回报期望最大。说着这么大一堆,是不是了解强化学习要解决个什么问题呢?
求解最优策略
当值函数最优的时候,采取的策略也是最优的,反过来策略最优的时候值函数也是最优的,这个叫做策略最优定理,所以可以通过求解最优的值函数V∗,Q∗来求解最优策略。
一旦我们知道了V∗,基于每个状态s,做一步搜索,搜索以后出现的最优的行为将会是最优的。
同理我们如果有最优的值函数Q∗,求解最优策略就更好了,只要找到最优的状态就可以啦。
综上所述
我们来总结一下,本节主要讲的就是贝尔曼方程,以及最优策略,最优值函数等。