标签提取在评论挖掘中经常被使用到,如何快速的挖掘众多评论中一些关键词,包括积极地或者消极的。本文将要介绍标签提取一些常用方法,从而丰富我们的技术场景。在介绍新的方法之前,这类问题最朴素的想法应该是通过TF-ID算法对评论进行词频等特征的统计,获取那些重要度高的词语。接下来咱们来介绍两个解决这类问题的方法。
TextRank是通过pagerank衍生出来的一类无监督算法,对于pagerank不了解的观众,可以看下这篇文章。PageRank算法,PageRank早期是解决网络检索召回文章质量不高的问题,对应本文说的标签挖掘,就是找到重要度高的一些词语。
其实TextRank算法的思路十分简单,甚至都不需要过多的介绍。
通过词之间的相邻关系构建网络,然后用PageRank迭代计算每个节点的rank值,排序rank值即可得到关键词。唯一不同点是它的迭代公式如下。
WS(Vi)=(1−d)+d×Vi∈In(Vi)∑∑Vk∈Out(Vj)wjkWjiWS(Vj)
d是阻尼指数,就是0到1之间的一个权重,代表从计算单元中的某个特定的单元指向其他单元的概率值,对于NLP来讲就是同时出现的概率。In(Vi表示图的某单元的入度,Out(Vj)表示图的某单元的出度。该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度。最后能够从大量的评论中获取如下的词云。

TextRank是一种无监督算法,它的却低也是显而易见的,对于评论没有出现过的词,这种方法也是万万不能挖出来的。
基于深度的标签提取方法
一种比较常用的方式是通过CNN进行学习,这里你可能会有一个疑问,这东西不是进行图像学习的吗,咋搞到NLP了吗。其实各种模型都有它擅长的处理数据的方式,其实CNN它的标签不是图像领域,而是在空间数据的学习上。在标签提取中,输入格式是文本和标注两个文件,每个文件只包含一个评论文本。每行包含一个标签,且标签数目不定,有多少标签就是多少行。 然后经过大量的数据标注,这里可以通过主题模型进行一部分半自动化标注。最后就是通过CNN对评论进行端到端的学习,每个评论有一个不同标签的概率。
标签情感分析
提取了这么多的标签,怎么使用呢? 这里就是一个新的情况,标签情感分析,如果我们能快速的分析数当前这个评论或是标签表达的情感,是不是可以对用户心里进行归因,从而修正目前的各种问题,甚至避免一些舆情的发生。
基于深度学习的TextCNN
TextCNN常用与情感分类的模型中,是卷积神经网络应用在文本分类上的一个最简单的方法。下图是TextCNN的一个基本结构,基本和CNN区别不大。主要是将文本以图像的形式呈现出来,通过卷积神经元获取关键的上下文特征。
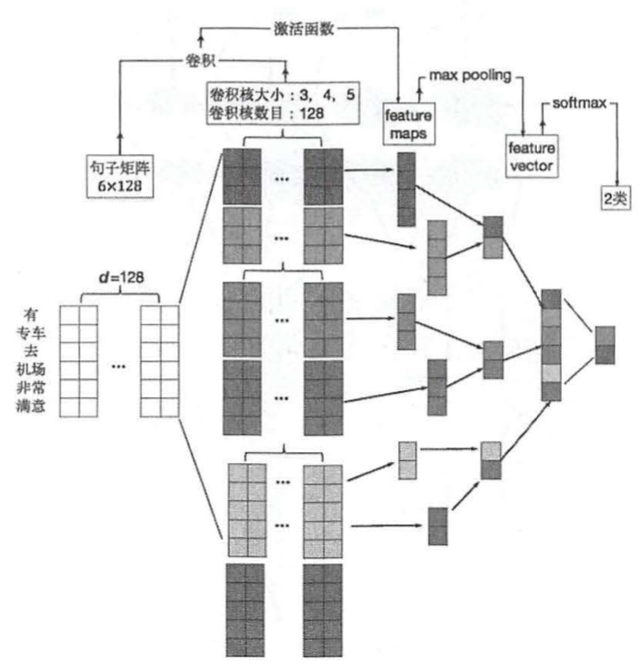
TextRNN
还有一种方法就是TextRNN,基本结构如下图所示, TextRNN和TextCNN最大的不同是,循环神经网络弥补啦卷积神经网络中卷积核固定大小的问题,使得卷积神经网络无法抽取到与当前词距离更长的信息表达。
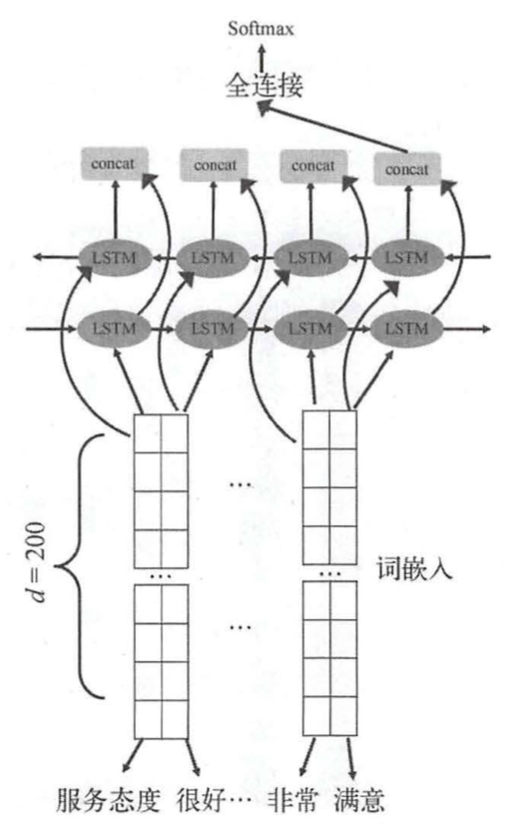
该结构直接将表示层作为双向LSTM的输入,将输出进行拼接,进一步增加全连接的特征维度,最后给出概率值。