基于值的深度强化学习算法
平均值DQN
平均值DQN是基于传统的DQN的一个简单但是非常有效的一个改进,它基于对先前学习过程中的Q值估计进行平均,通过减少目标价值函数中的近似误差方差,使得训练过程更加稳定,并提高性能。至于网络结构上是完全一致的。
算法分析
平均值DQN主要关注传统DQN学习过程中存在的误差,并想办法减少这些误差。
Q(s,a;θi)表示第i次迭代的值函数,
Δi=Q(s,a;θi)−Q∗(s,a)=Q(s,a;θi)−ys,ai+ys,ai−y^s,ai+y^s,ai−Q∗(s,a)
其中ys,ai表示估计值,y^s,ai表示真实值。
Zs,ai=Q(s,a;θi)−ys,ai表示目标近似误差
Rs,ai=ys,ai−y^s,ai表示过估计误差
y^s,ai−Q∗(s,a)最优差值。
ys,ai=E[r+γmaxa′Q(s′,a′;θt−1)∣s,a]y^s,ai=E[[r+γmaxa′(ys′,a′i−1∣s,a)]
由于传统的DQN总是选取目标价值最大的动作执行,因此容易导致过估计。Zs,ai是在最小化DQN损失以后Q值和估计值ys,ai的一个误差。Zs,ai可能有多个原因造成。
- 由于不精确的最小化导致的参数θ不准
- 由于经验池复用的大小限制泛化误差
而这个误差有是影响比较大的问题。每次迭代都依赖这个值的预测准确性。我们假设Zs,ai是一个随机过程,E[Zs,ai]=0,Var=Zs,ai=σ2。 那么对于均值DQN就能过得到
Qi=Zi+γPK1k=1∑KQi−k
P表示转移矩阵,S×S, K表示最近K步的平均,进一步将模型转化为M状态的单项MDP。
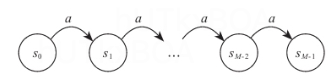
那么下面方差的变化就是
VAR[QiA(s0,a)]=m=0∑M−1Dk,mγ2mσsm2
其中
Dk,m=N1∑n=1n∣Un/K∣2(m+1),并且U=(Un)n=0n−1表示矩形脉冲是离散傅里叶变换,,∣Un/K∣<=1,Dk,m<K1.
因此意味着平均值DQN理论上能够有效的减少近似误差并且至少比普通的DQN好K倍。
伪代码

试用场景
传统的DQN在学习过程中可能出现学习过程中不稳定的问题,而平均值DQN通过计算之前学习的估计值的平均值生成了当前的动作价值估计,很好的解决了学习过程不稳定的问题,并且调高了DQN的学习性能。其实简单思考平均值DQN实际上是对值函数的一个平滑,进而减少估计误差。
基于动作排除的DQN
当我们面对动作空间很大情况下,这个时候我们经常使用逆向思维,通过一个模型学习最不可能的下一步动作,从而在最可能得动作中选择最好的值函数方法,这样既能加快学习的速度,还可以提升学习的质量。这个算法就是AE-DQN算法,本文就不过多介绍,感兴趣的可以通过论文阅读。
AE-DQN