本节我们还来讲nlp的相关的东西,我们刚刚讲解了如何将word转化为一个vector,其实我们还是没有对语序做一个很好的应用,例如 我给你一个苹果和你给我一个苹果,意义上完全不同,但是识别的时候可能关键词十分相似。所以我们正好讲讲doc2vec的算法,如何充分利用语序信息的。谷歌的工程师提出了DM模型和DBOW模型,其实就是对应咱们word2vec中的CBOW和Skip-gram模型
DM(Distribute memory)
DM模型视图预测上下文某个单词的出现概率,只不过DM模型的上下文不仅仅包含上下文,还包括段落信息。为了对照学习我们先来回顾下CBOW模型。
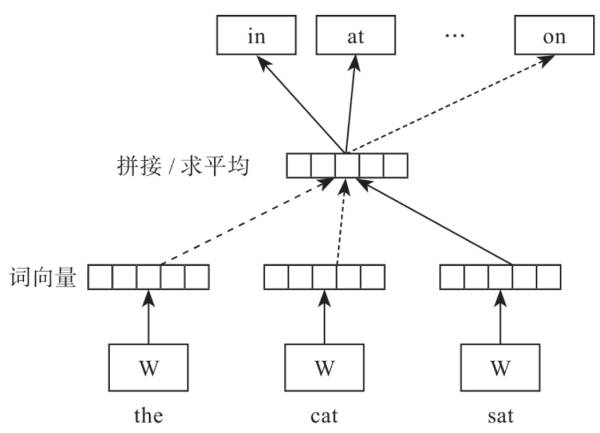
然后我们对照来看看,语CBOW算法相比,DM模型添加了一个和词向量等长的的句向量,也就是说DM模型是结合词向量和句向量一起来学习的,如图所示,能够看出在前面链接一个句向量。
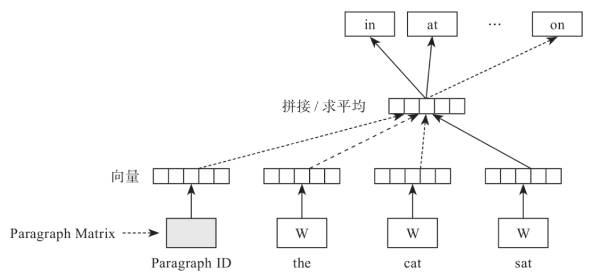
DM模型的训练过程就是,每次从一句话中滑动采样固定长度的词,取其中一个词作预测词,其他的作输入词。输入词对应的词向量word vector和本句话对应的句子向量Paragraph vector作为输入层的输入,将本句话的向量和本次采样的词向量相加求平均或者累加构成一个新的向量X,进而使用这个向量X预测此次窗口内的预测词。
DBOW模型
DBOW模型和doc2vec模型也是比较类似的,只不过DBOW模型中,输入只有句向量就可以啦。
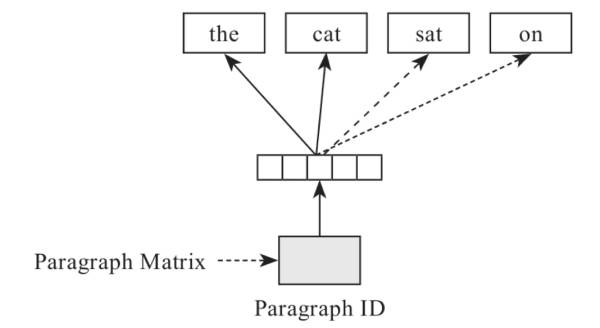
也就是一句话中的其他词向量都作为输入,只有目标词是输出,然后根据这样的概率分布学习词向量的表达。