seq2seq处理人工翻译的时候会有一个问题,就是当句子特别长的时候问你会发现翻译的效果并不是特别好,至于原因呢就是seq2seq学习的时候对信息遗忘严重,为了解决这个问题,就有研究者提出了加入Attention的机制来解决这个问题,核心就是我们在解决一个问题的时候只关注某些关键信息就够了,并不要全部都关注,这样反而容易遗忘。
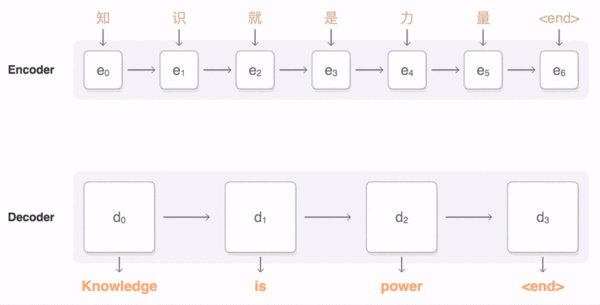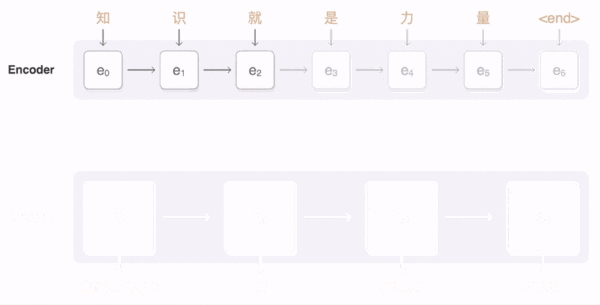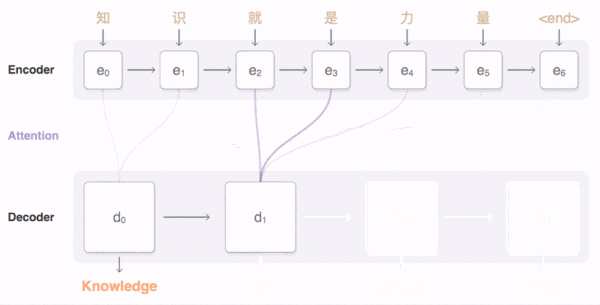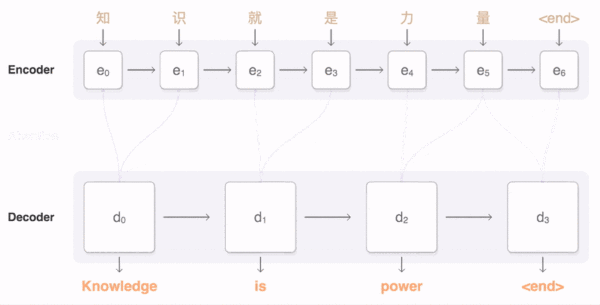
上面这个动图十分形象的展示了seq2seq+Attention机制的原理。接下来我们看看实际的过程。
我们使用更加直接的意图图来看看经过decoder的数据到底是哪些数据组成。
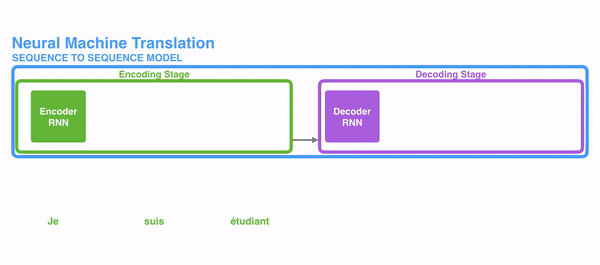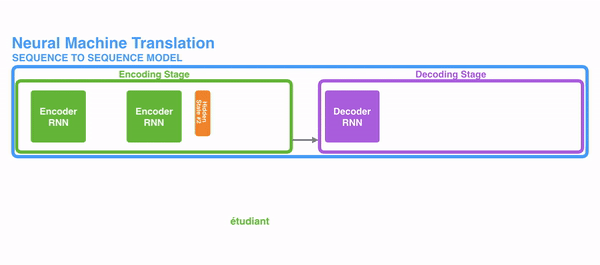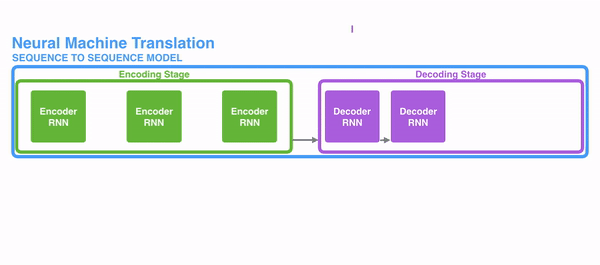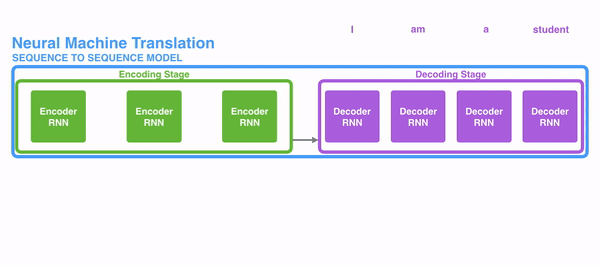
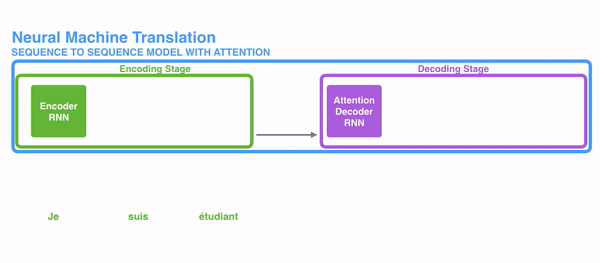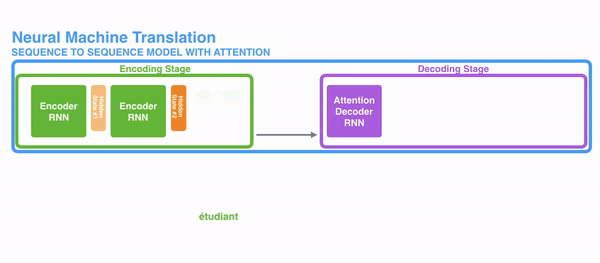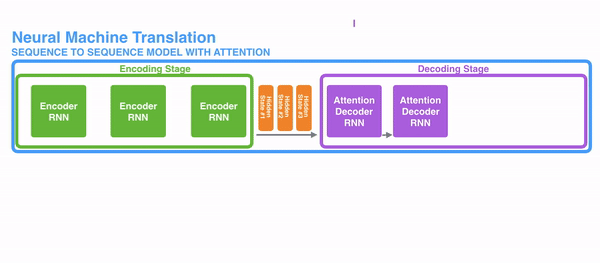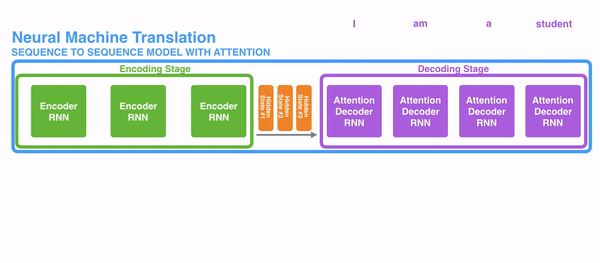
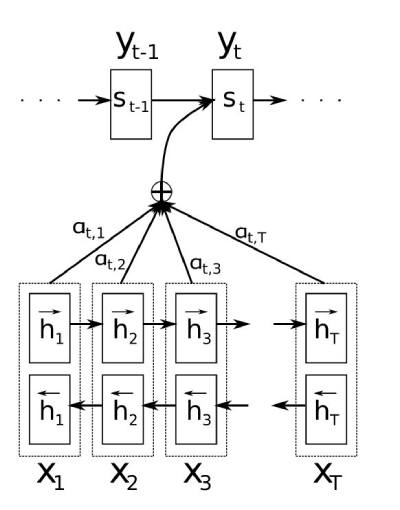
- 首先我们利用RNN结构得到encoder中的hidden state (h1,h2,...,hn)
- 假设当前decoder的hidden state 是st−1,我们可以计算每一个输入位置j与当前输出位置的关联性,eij=a(st−1,hj),eij=(a(st−1,h1),a(st−1,hT)),e 是一种相关性的算符的运算,常见的就是点乘,et=st−1h
- 对于et进行softmax操作将其normalize得到attention的分布,at=softmax(et).
- at就可以理解成我们的context,也就是上下文。ct=∑j=1Tatjhj
- 我们可以计算decoder的下一个hidden state,st=f(st−1,yt−1,ct)以及该位置输出的p(yt∣y1,..,yt−1,x)=g(yi−1,si,ci)
这里关键的操作是计算encoder与decoder state之间的关联性的权重,得到Attention分布,从而对于当前输出位置得到比较重要的输入位置的权重,在预测输出时相应的会占较大的比重。
通过Attention机制的引入,我们打破了只能利用encoder最终单一向量结果的限制,从而使模型可以集中在所有对于下一个目标单词重要的输入信息上,使模型效果得到极大的改善。还有一个优点是,我们通过观察attention 权重矩阵的变化,可以更好地知道哪部分翻译对应哪部分源文字,有助于更好的理解模型工作机制,如下图所示。
进一步理解
咱们再以attention的视角尝试解释一下上面的例子, 对于"知识就是量的"例子, 当翻译到“力量”的时候, 这个时候不知“力量”对应哪个英文单词,那么需要用attention用解码器中上一个已经被翻译出来的“is”的隐含层输出作为query,去attention pooling中查询编码器 中上一个已经被翻译出来的“就是”的RNN的隐含层输出,找到“就是”后把它附件的词的相似度收集起来,作为一个分数,将该分数作为attention的输出和下一个单词的嵌入合并输入到下一个RNN中。