本文将介绍命名实体识别的一些方法,在自然语言中使用十分广泛。首先我们要介绍一下背景,什么是命名实体识别呢? 咱们举个例子,比较喜欢自然语言方向的东西就是举例子比较好列举,哈哈。 我爱北京天安门,中华人民共和国万岁,这句话进行一个简单的标注。
我/O爱/O北京/O天安门/O中华/B人民/M共和国/E万岁/O
B表示实体的开头,M表示实 体的中间,E表示实体的结尾,S表示单一实体,O表示非实体部分。很明显中华人民共和国就是一个实体,不知道你培养出实体的感觉了没有。然后所谓的命名实体识别就是将预料中所有实体抽取出来。抽取出来的形式就是我们在新的语料中能够打上这样的标签,是不是就完成了命名实体识别呢?下面就来介绍业界常用的两个方法。
条件随机场(CRF)
首先我们就介绍CRF的方式进行命名实体识别,CRF与HMM模型十分相似,如果不了解HMM模型的可以看看我之前的一个讲分词的文章。自然语言处理之分词。
概率有向图
概率有向图又称为贝叶斯网络,概率无向图又称为马尔科夫网络。 最重要的目前是如何求P(Y)联合概率。对于概率有向图来讲比较简单的是用条件概率表示,例如对于下面这个有向图。
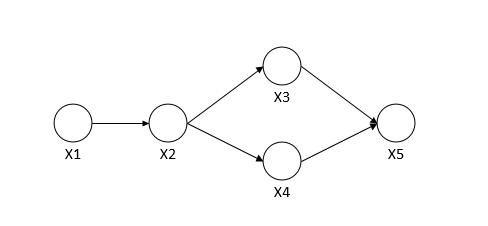
P(x1,...,xn)=P(x1)∗P(x2∣x1)∗P(x3∣x2)∗P(x4∣x2)∗P(x5∣x3,x4)
概率无向图
对于概率无向图中(如下图),无向图G=(V,E),V是节点,E是边, 图G中每个节点v上都有一个随机变量y,边e表示相邻节点的变量存在一定依赖关系。图G上的随机变量Y满足马尔科夫性,即两个不相邻的节点上的随机变量yi,yj条件独立,就称此联合概率分布为概率无向图模型,又叫马尔科夫随机场(MRF).马尔科夫随机场的成对、局部、全局马尔可夫性是等价的,都是表达一个意思,即边不连接的节点之间相互独立。
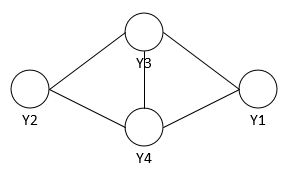
对于概率无向图的联合概率的定义为为其最大团上的随机变量的函数的乘积形式的操作,称为概率无向图模型的因子分解(factorization)。这里需要知道下面两个概念。
团:无向图中任何两个节点均有边连接的节点子集。
最大团:若C为无向图G中的一个团,并且不能再加进任何一个G的节点时其成为一个更大的团,则称此团为最大团。上图中{Y2,Y3,Y4}和{Y1,Y3,Y4}都是最大团。
概率无向图模型的联合概率分布P(Y)可以表示为如下形式:
P(Y)=Z1C∏σ(YC)Z=Y∑C∏σ(YC)
线性链CRF
你可能会有疑问,我就想知道怎么分词,你和我讲这么多干嘛。在nlp领域中词与词之间的关系就是最大团的概念,所以它能够完美的应用上面的理论。对于分词这一业务场景X就是整个句子的**上下文(非条件概率考虑)**也就是观测变量,Y就是因变量,也就是每个位置的标签,NLP中一般使用B,M,E,S。它的形式化如下
P(Y∣X)=Z1∏σ(Yi,Yi+1∣X)
进一步表示为
P(Y∣X)=Z(x)1exp(i,k∑λktk(yi−1,yi,x,i)+i,l∑μlsl(yix,i))
t和s都是特征函数,一个是转移特征,一个状态特征.注意一个细节,特征函数里面的观测变量为x,而不是xi,这也就是说你可以前后随意看观测变量,所以特征模板里面可以随意定义前后要看几个观测值。
CRF处理和训练
说到这里就要介绍下一般训练CRF的时候都要做一个特征模板实际上就是定义这个转移关系和状态关系的。
一条分词标注长成什么样子呢?
山西/B 相立/M 山泉/M 饮品/M 开发/M 有限公司/E 生产/O 的/O 桶装/O 饮用水/O 检出/O 铜绿/O 假/O 单胞菌/O
B:实体的开头
M:实体的中间部分
E:实体的结束
W:单独成实体
O:句子的其它成分
当我们训练的时候会把数据处理成如下的形式
宁夏 ns 0 isloc notend B
物美 nz 0 notloc notend M
超市 v 1 notloc notend M
有限公司 n 1 notloc notend M
森林公园 n 0 notloc notend M
店 n 1 notloc isend E
第一列为词本身,第二列为特征①,第三列为特征②,第四列为特征③,第五列为特征④,第六列列为正确标注。
特征模板
CRF模型的训练,需要一个特征模板,以便能够自动在训练文本中提取特征函数,特征模板的定义直接决定了最后的识别效果。
Unigram
U01:%x[-2,0]
U02:%x[-1,0]
U03:%x[0,0]
U04:%x[1,0]
U05:%x[2,0]
U06:%x[-2,0]/%x[-1,0]/%x[0,0]
U07:%x[-1,0]/%x[0,0]/%x[1,0]
U08:%x[0,0]/%x[1,0]/%x[2,0]
U09:%x[-1,0]/%x[0,0]
U10:%x[0,0]/%x[1,0]
U11:%x[-1,1]/%x[0,1]/%x[1,1]
U12:%x[-1,1]/%x[0,1]
U13:%x[0,1]/%x[1,1]
U14:%x[0,1]/%x[0,2]
U15:%x[-1,1]/%x[0,2]
U16:%x[-2,1]/%x[-1,1]/%x[0,2]
U17:%x[-1,1]/%x[0,2]/%x[1,1]
U18:%x[0,2]/%x[1,1]/%x[2,1]
U19:%x[0,0]/%x[0,2]
U20:%x[-1,0]/%x[0,2]
U21:%x[-2,0]/%x[-1,0]/%x[0,2]
U22:%x[-1,0]/%x[0,2]/%x[1,0]
U23:%x[0,2]/%x[1,0]/%x[2,0]
Bigram
B
上面中Unigram格式中每一行%x[#,#]生成一个CRFs中的状态(state)函数: f(s, o), 其中s为t时刻的标签(output),o为t时刻的上下文以及特征信息。Bigram类型中每一行%x[#,#]生成一个CRFs中的边(Edge)函数:f(s’, s, o), 其中s’为t – 1时刻的标签.也就是说,Bigram类型与Unigram大致机同,只是还要考虑到t – 1时刻的标签.这里只写一个B,默认生成f(s’, s).
然后我们来具体看看这个目标到底是啥意思?
对于%x[-2,0]而言,%x是指找到的字符;[-2,0]是定位信息,其中中括号里面的-2是指当前词的前两个词,0是指第0列。后面用/连接的是多个特征的组合。
当token=”超市“的啥时候,%x[-2,0]/%x[-1,0]/%x[0,0]对应识别出来的文本为宁夏/物美/超市,第一位的数字表示行偏移量,第二位是使用上面特征序号①。也就是列偏移量。
不知道大家理清楚了没有,最后我们实际上根据当前的位置和内容,学习相应位置的标签数据。最终我们获取一个句子的时候是看什么样的标签在下文中的转移概率最大,给整个句子打上类似标注的标签。这类方法和之前的写的路网匹配算法十分相似,可以搜索本站 ”路网匹配算法“
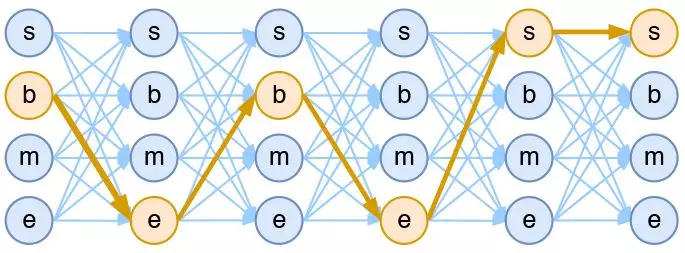
CRF整体训练流程
(1)训练文本预处理
1)清理文本中的乱字符,统一文本格式。
2)对待训练文本进行中文分词。
3)确定序列标注集合,对训练文本进行标注。
(2)训练CRF模型
1)制作CRF特征模板。
2)输入标注好的预处理训练文本。
3)使用CRF++工具进行训练,生成CRF模型。
BiLSTM命名实体识别
自从深度学习诞生后,人们开始考虑如何利用深度学习的自动提 取特征功能,以便更加有效地提取特征,提高NER模型识别的准确率和 召回率。但是,深度学习预测出来的标签有可能是无效的,因为其是 对每个token单独的标签预测,没有联系上下文信息。深度学习模型需 要CRF提供更多的标签之间的转移概率,即上下文信息。举个例子
我/O爱/O北京/O天安门/O中华/B人民/M共和国/E万岁/O
O表示普通分割
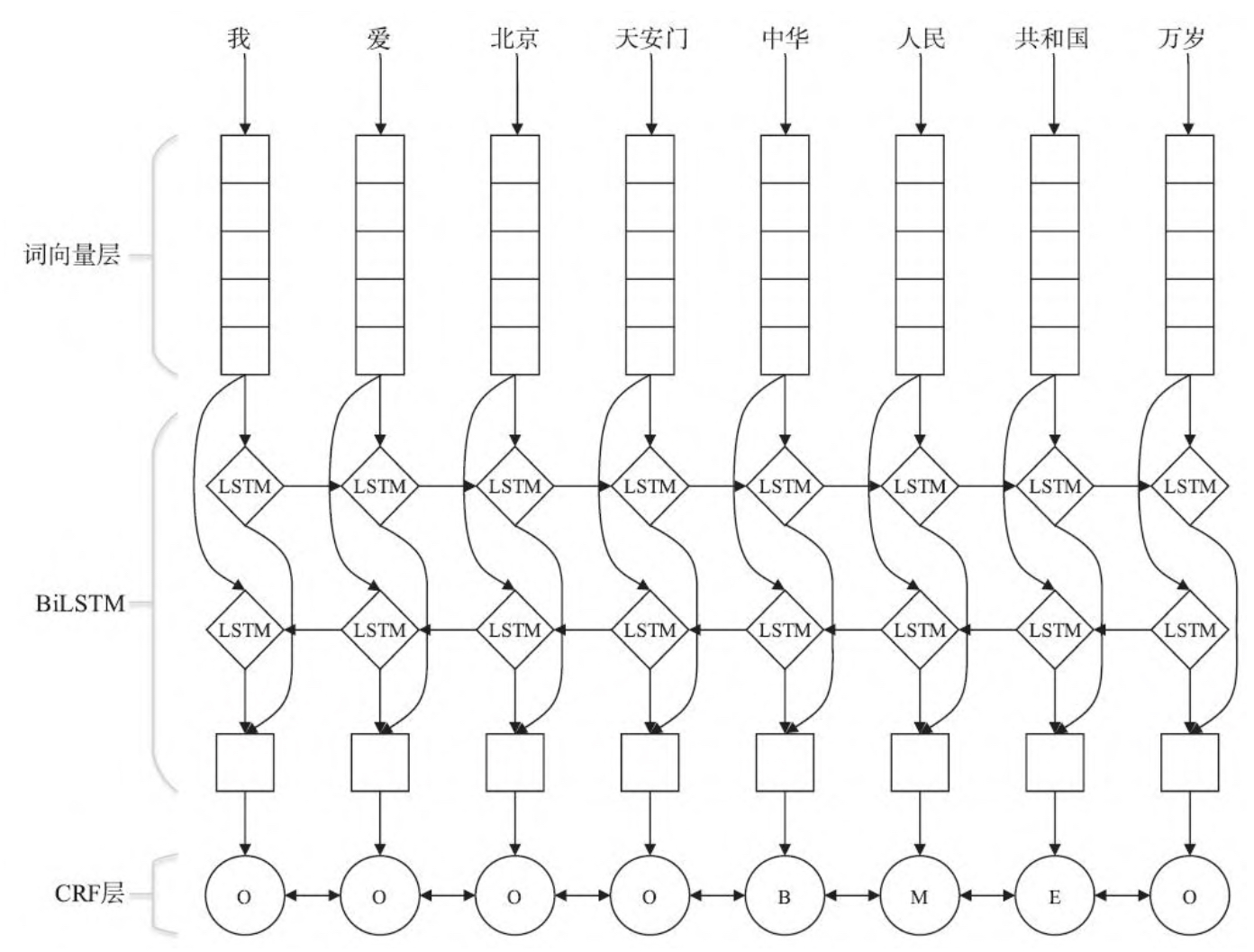
首先将句子做一个转换,x=[x1,..,xn],其中xn表示表示第n个词的one-hot结果,也可以是词袋模型。
然后通过word2vec将词语向量化。
BiLstm进行学习。
词向量层后面接着BiLSTM层。输入为词向量序列W=[w1,w2,..,wn], 前向隐藏层输出为h=[h1,...,hn],后向隐层同理,然后按照原始位置进行拼接H=[hi,hj].
线性层
然后将上面的输入数据进行线性层进行回归,目标就是标注的标签。例如下图我们能拟合出一个标签的分布概率出来。
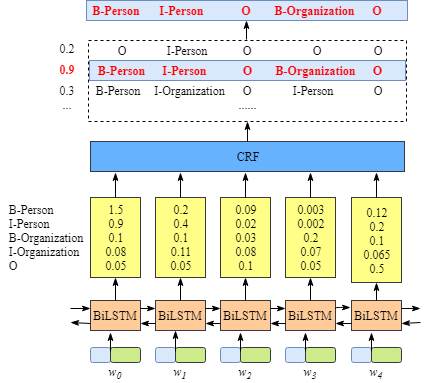
CRF层
最后一层是CRF层,BiLSTM预测出来的概率分布怎么使用到CRF中呢?我还记得jinxingCRF学习的时候,有两个特征,一个是转移特征,一个状态特征。 对于当前的模型架构下。就转化成状态得分和转移得分啦。 那么我们通过BiLstm学习到的概率分布实际上就是状态得分。从一个标签转移到另一个标签的得分由CRF决定。最终的得分经过一个归一化处理即可。最后仍然使用维可比算法进行整体句子的标签预测。
这里可能会有个小问题就是,直接通过BiLstm是不一样直接就能够标注,不通过CRF可以吗。当时然可以的,但是我们通过CRF学习是想过滤掉一些无效标签,否则仅仅依赖BiLstm学习出来的标签分布会产生无效标签,例如 EE同时出现的例子。