本章咱们就不介绍一篇论文这么枯燥啦,由于元学习和AutoML学习经常会被弄混,所以本章主要就聊聊这两种学习方式的异同点。早期的时候这两种学习方式确实是比较相近的,甚至有一些争议,最近的研究中这这两种学习方式也开始越来越清晰。元学习是解决对于未知类别的识别上,而AutoML的目标是如何自动化的构建网络参数和网络形状等等。所以二者的目标已经被却分好啦。元学习之前咱们已经介绍了两个算法啦,下面咱们就好好看看AutoML是咋回事。
超参数优化
常用的神经网络超参数优化的方法有随机搜索、遗传演化算法、强化学习、元学习和贝叶斯方法。这些方法都有哪些异同呢?
- 随机搜索一定是能接近最优解的,但是计算量巨大,所以容易被使用
- 遗传演化也是同样的问题
- 强化学习这里可以解释一样,强化学习用于参数的调整实际上是把将超参数的选择当成了动作,模型的实际结果当成了回报,通过这样的交互从而优化出最优的神经网络
- 元学习的核心能力是借用比较很少的数据集就能给出一个比较好的结果,所以元学习使用在参数选择上是借用少量训练后的数据,根据以往的经验决定某些参数是否需要开始一个训练,从而大量减少搜索空间。
- 贝叶斯方式是在一些参数依赖的任务中有比较好的表现。
元学习和AutoML的结合
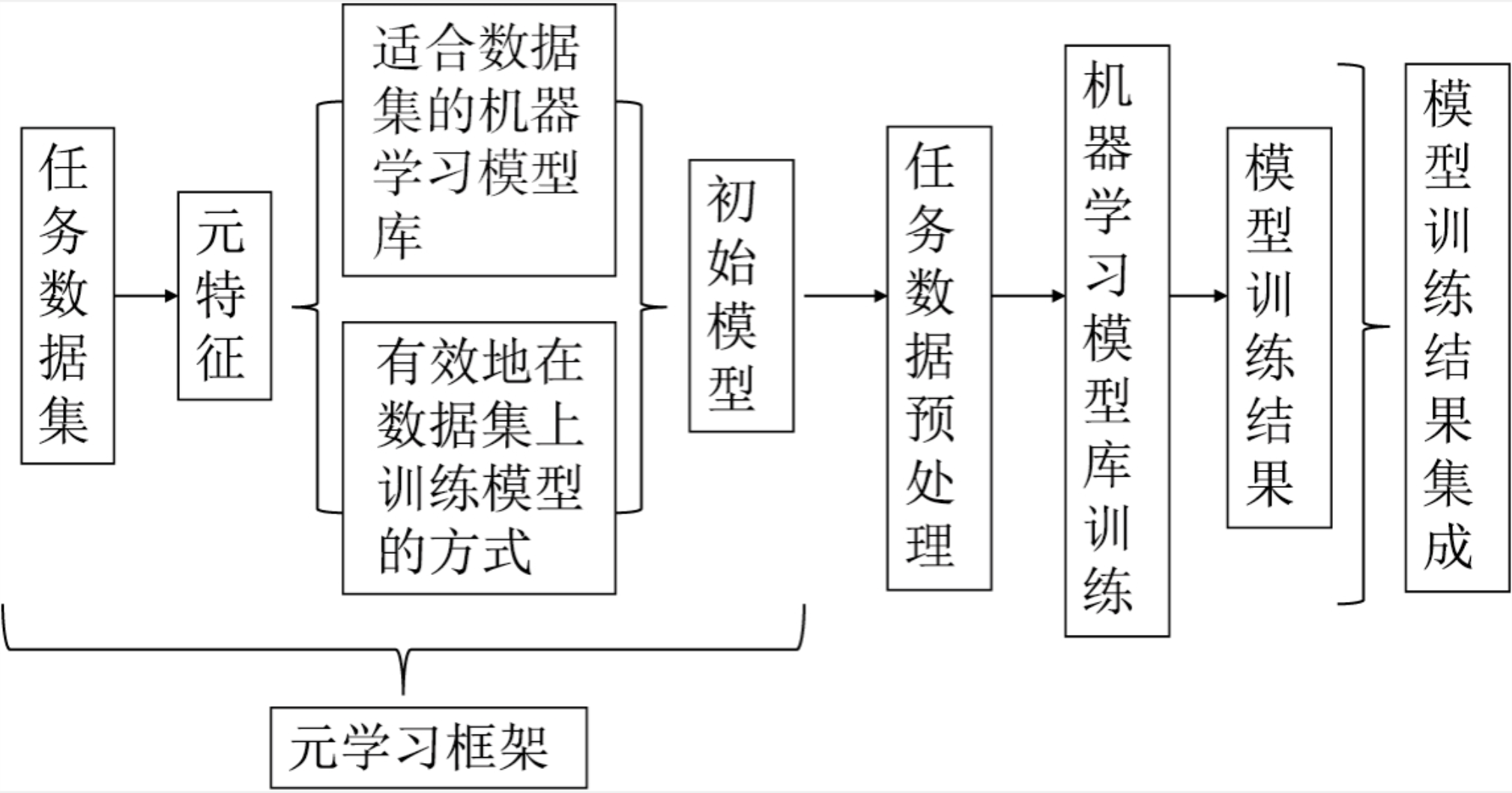
元学习框架可以累计以往的训练历史,包括神经网络的层数和宽度,已经所有超参数包括学习率是否有捷径的特征决策当前的参数配合下是否能有性能的提升,从而大量的减少学习成本。
另一个点就是元学习框架将每个的训练当成一个任务,从多个任务中学习其中相似的部分,从而快速决策出后续的调参方向。
加速自动化学习
元学习和AutoM一个典型的案例是通过元学习推理神经网络的学习率,对于一些预测不会达到比现在更优的方案果断放弃掉,防止资源的浪费。
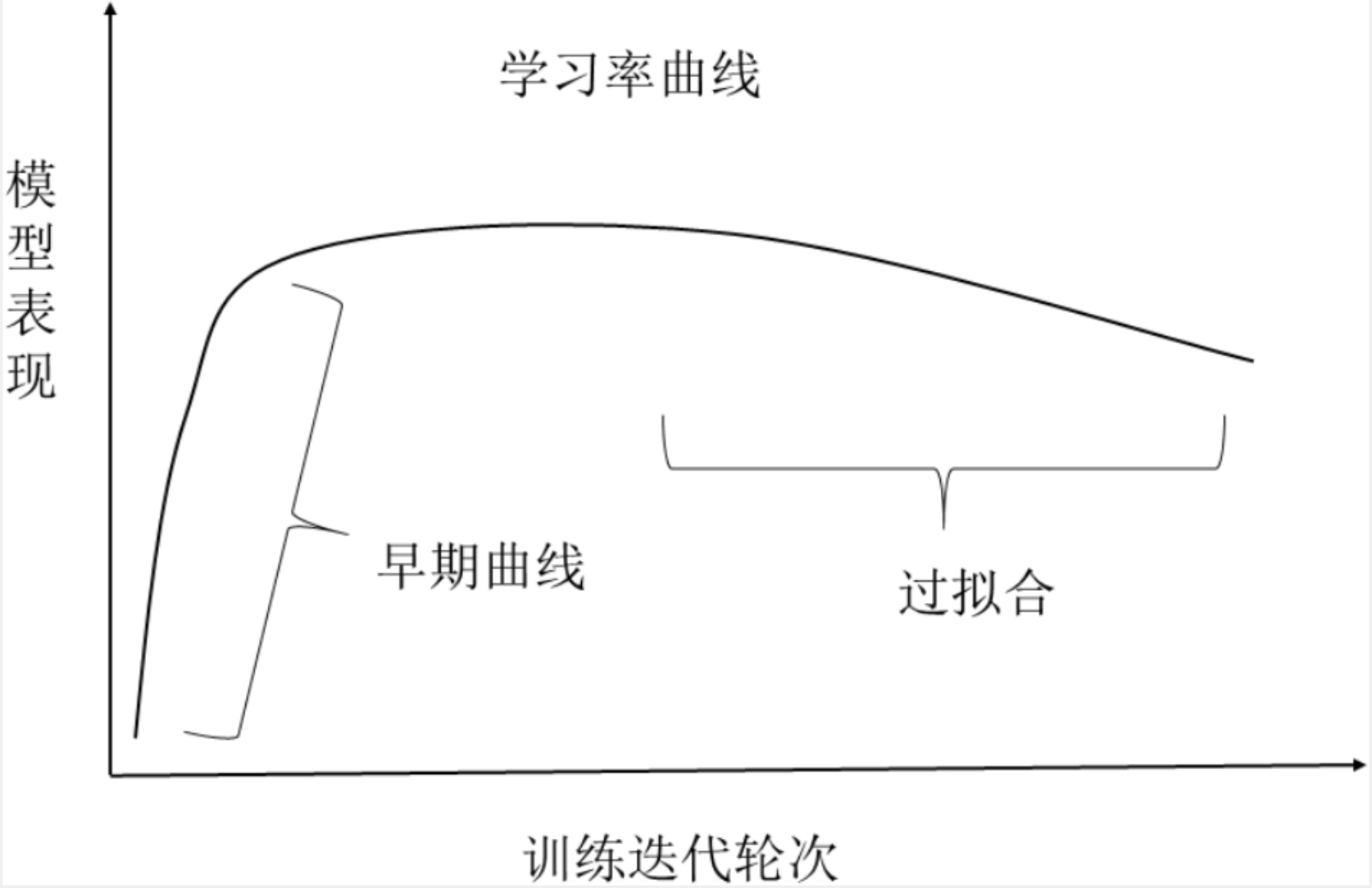
上图就是一个训练的一般形式,其中大部分曲线都是这样一个走势,经过前几轮的完整训练我们就能通过元学习预测样本外的数据,从而更加早的判断一个训练是否是一个有价值的训练。这类算法的大致框架如下。
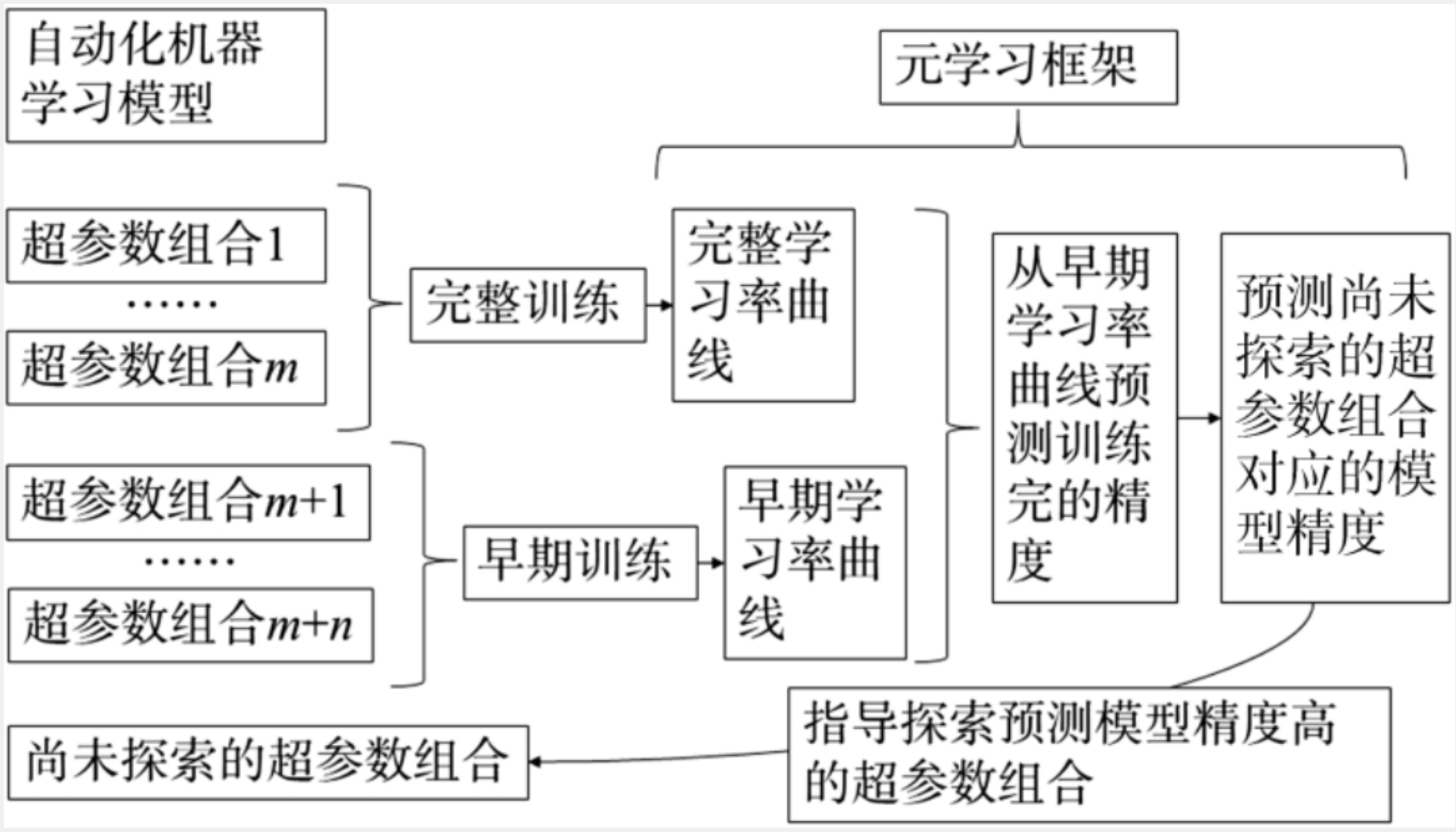
决策式自动学习
决策式自动学习可以看成以上的几个阶段。
- 元学习器学习大量的任务数据,提取有效的元特征,记录这些特征和学习模型和参数的映射方式。
- 在处理新任务的时候提供更好的初始化学习器
- AutoML在训练过程中选取较好的模型进行迭代逐渐获取最优值
渐进式自动化学习
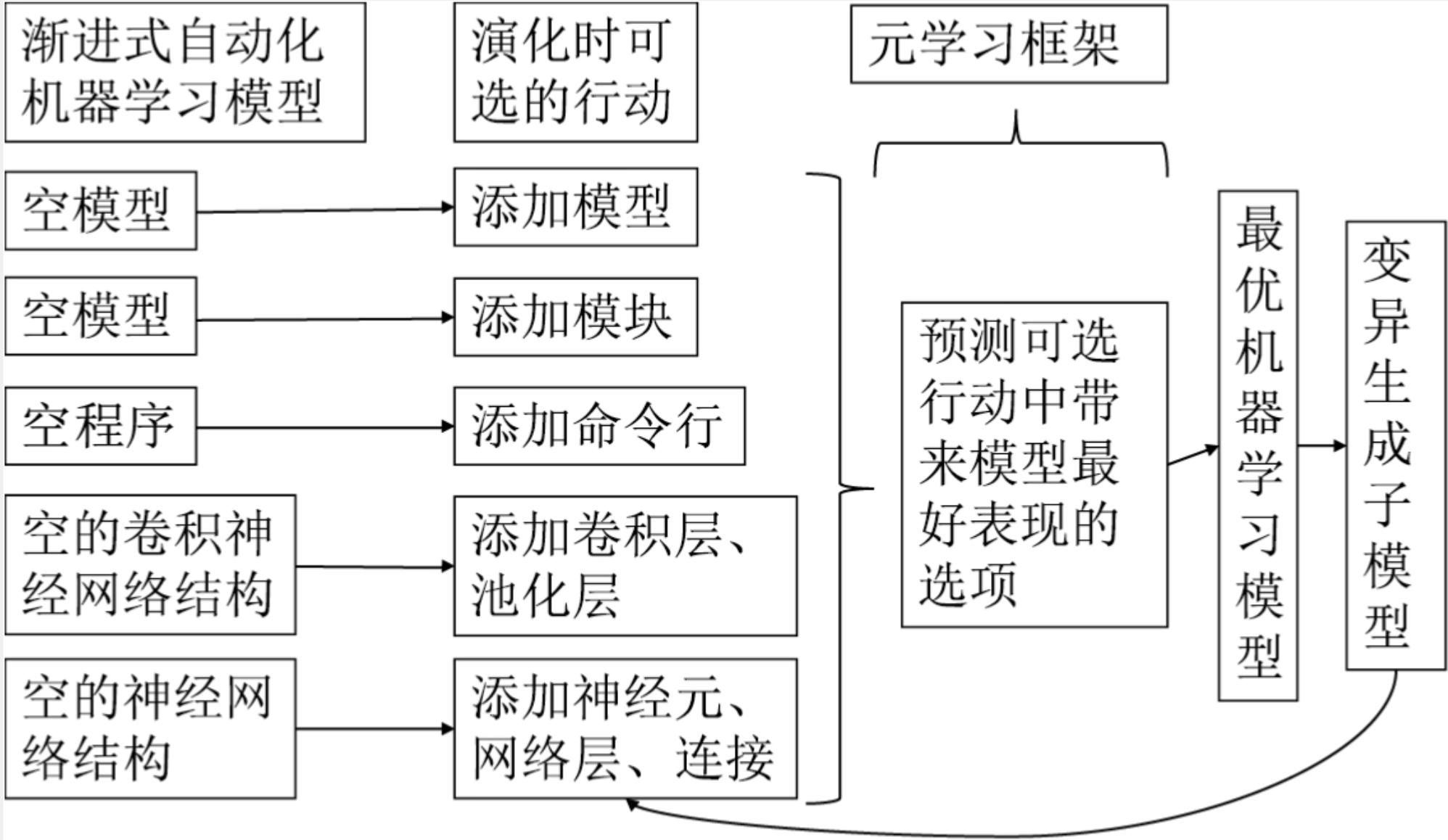
上图给出了渐进式自动化学习的流程,先生成空模型然后元学习框架得到模型的变异,不断优化模型逼近最优值。在超参数很多的情况下,随机搜索需要占用极大的搜索时间,而这个时候元模型框架能够根据目前的变异动作给出最优的解,从而不断的优化模型。在模型演化的过程中,原模型框架积累经验并对所有的动作作预判,推荐模型采用最优的动作。
说到这里开头的时候我们谈论到使用强化学习的方式实现AutoML也是这个思路,模型的每个改动都会当成一个动作,模型的训练效果当成是回报,从而构建一个模型演进的方向。