本文我们来介绍一个度量学习方式,取材于论文Learning to Compare: Relation Network for Few-Shot Learning。
数据集合
度量学习中,数据集不仅仅是监督学习的中的训练集合测试集的概念,那现在就来介绍他的数据集。
训练集: 和普通的训练集一致,这里存放大量级别带有标签的数据。
支撑集合:支撑集合也是带有标签的数据,但是数量量比较小,并且支撑集合的类别与训练集是互斥的。假如支撑集合包含C个类别,每个类别下有K个样本,就称这样的任务为C way K-shot任务。
测试集合: 测试集合的数据类别和支撑集合是相同的,但是与训练集互斥。
那么通过这样的训练怎么来识别测试集合的类别的,看样子训练集合的数据,测试集合都没有呢。 所以这里元学习起到的作用是通过训练集合能够区分不同类别之前的区别,让同类更相近,异类距离更远。这个基本就是度量学习的基本思想。
训练方式
上文提到过,如果想训练一个任务在没有见过的分类上做学习,那么不能使用监督学习的方式仅仅做一个分类,需要学习每个类别之间的关系和区别,并且这种关系和区别能够在没有见过的样本中也能区分出来。
对于训练的方式也比较有意思,不是一次性的把所有的数据都放进一个网络,而是从训练集合中随机抽取C个类别K个样本,然后从剩下的训练集抽取几个分类作为支撑集合,然后放到下面的网络训练
模型框架
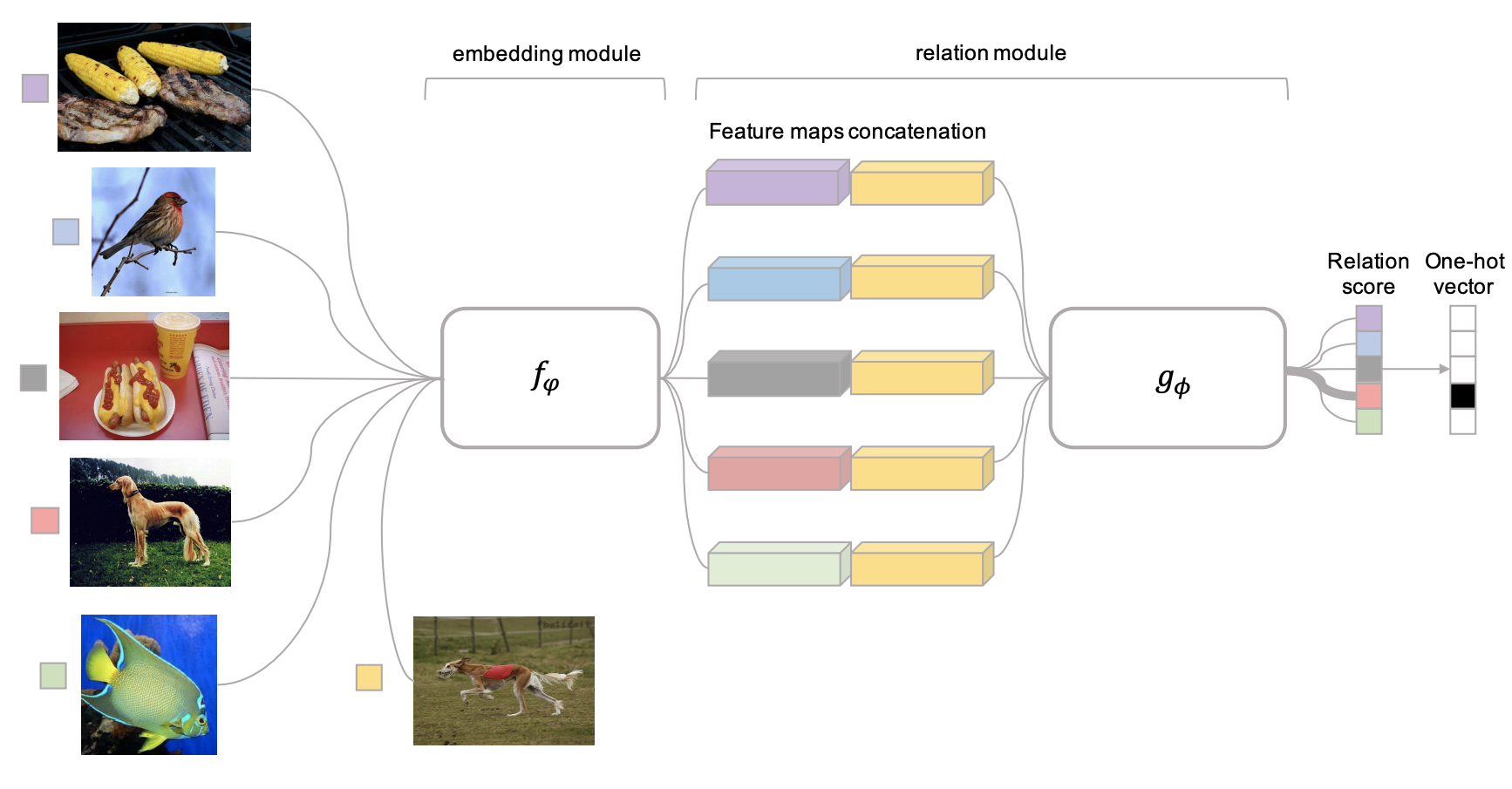
下面来看看上面这个框架,模型分别两部分,首先通过fφ特征提取器。 分别抽取的C个类别中抽取数据(左边一列图片),然后从支撑集合抽取一个图片,第二列的狗狗图片就变成了一个查询集合。在relationg module阶段,分别将查询集中的狗狗使用fφ提取的特征和在训练集合中提取的特征分别做链接,就构成了relationg module每个特征的来源。这个时候通过fφ去学习这些链接向量的relation scores。
ri,j=gϕ(C(fφ(xi),fφ(xj))
这里的C表示向量的连接操作,这里需要注意下的是,g函数是将所有的向量连接好后一起放到relation network的 。构成了Relation Score的向量,这个时候给出我们的标注然后求损失就好啦。这里需要说明一下的是标注只要标注当前两个数据是否属于一类就行啦。
ϕ,φ=argmin ∑(ri,j−(yi==yj))2
原文使用的就是MSE的损失函数,主要是要看最后这两个向量的偏差的平方,从而当成误差学习。
模型推理
模型推理使用的是真正的支撑集合与测试集合,推理的时候就是从支撑集合中抽取C个分类,从测试集合中抽取几个分类,学习测试集合中的分类是否属于支撑集合的分类,如果相同就输出支撑集合的分类就可以啦。
备注
sample_features_ext = sample_features.unsqueeze(0).repeat(BATCH_NUM_PER_CLASS*CLASS_NUM,1,1,1,1)
batch_features_ext = batch_features.unsqueeze(0).repeat(SAMPLE_NUM_PER_CLASS*CLASS_NUM,1,1,1,1)
batch_features_ext = torch.transpose(batch_features_ext,0,1)
relation_pairs = torch.cat((sample_features_ext,batch_features_ext),2).view(-1,FEATURE_DIM*2,19,19)
relations = relation_network(relation_pairs).view(-1,CLASS_NUM*SAMPLE_NUM_PER_CLASS)
class RelationNetwork(nn.Module):
"""docstring for RelationNetwork"""
def __init__(self,input_size,hidden_size):
super(RelationNetwork, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(128,64,kernel_size=3,padding=0),
nn.BatchNorm2d(64, momentum=1, affine=True),
nn.ReLU(),
nn.MaxPool2d(2))
self.layer2 = nn.Sequential(
nn.Conv2d(64,64,kernel_size=3,padding=0),
nn.BatchNorm2d(64, momentum=1, affine=True),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc1 = nn.Linear(input_size*3*3,hidden_size)
self.fc2 = nn.Linear(hidden_size,1)
def forward(self,x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0),-1)
out = F.relu(self.fc1(out))
out = F.sigmoid(self.fc2(out))
return
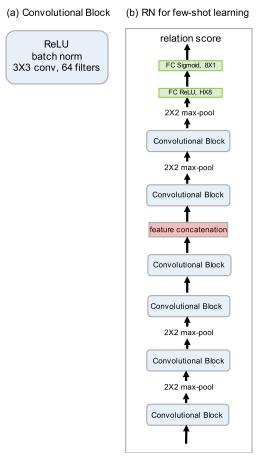
网络可视化如下图
总而言之
我们发现元学习和监督学习的方式并不一样,他希望学习到的是各种任务之间的偏差,而非是否属于一个类的概率,这样也为我们学习新的任务提供一个新的思路。