这一章我们介绍一下llama模型, 这一模型目前在开源领域十分出名,llama模型是一个训练模型,负责语义理解的编码。接下来我们就来看看这个模型。
llama 模型
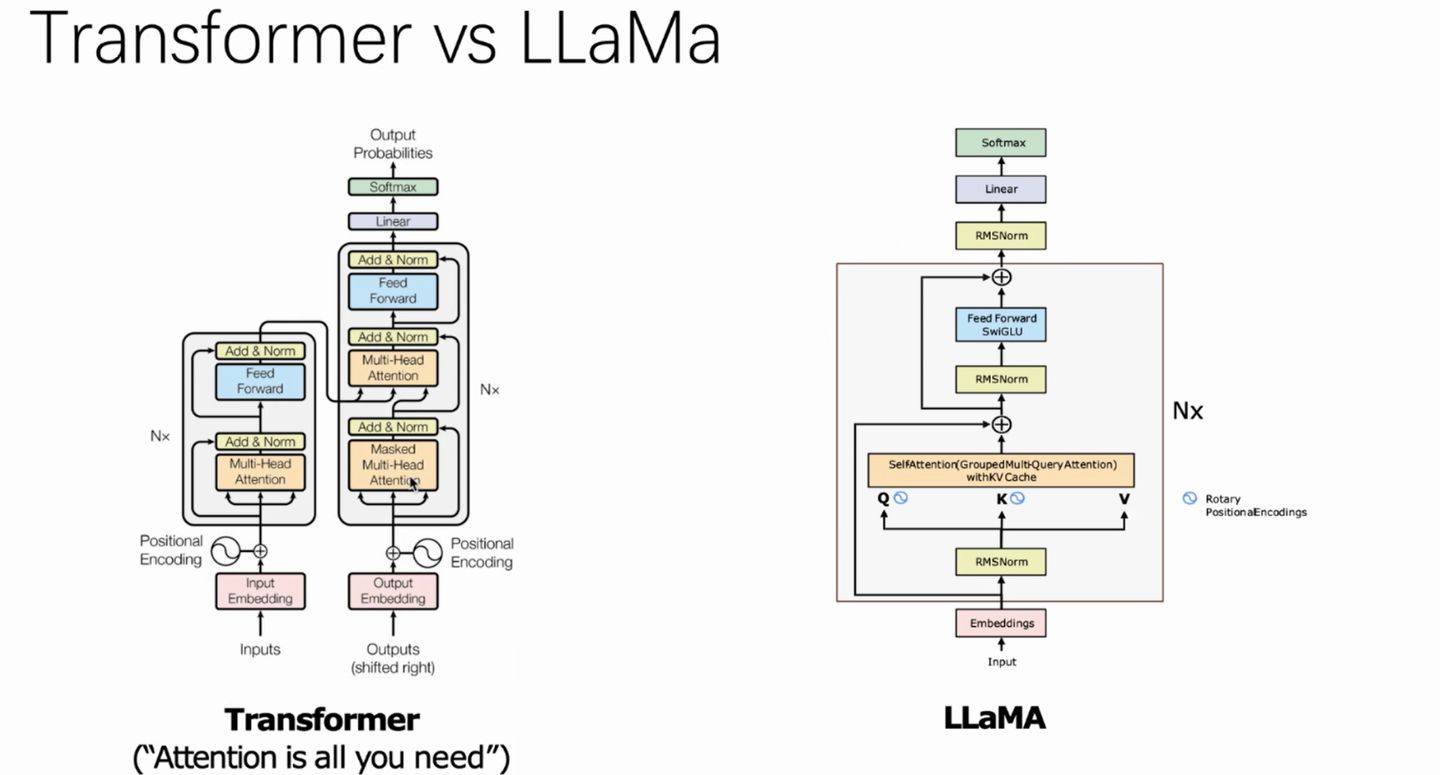
llama 1模型结构
llama模型也是基于Transformer的模型架构,但是在Transformer上做了一些修改,第一个方面的修改就是收到GPT3的启发的预归一化动作,就是在每个Transformer子层之前对输入进行归一化,而不是在子层以后进行归一化。这样做可以提高训练的稳定性。llama模型使用的均方根归一化(RMSNorm)。RMSNorm这个链接里介绍了一些归一化方式。
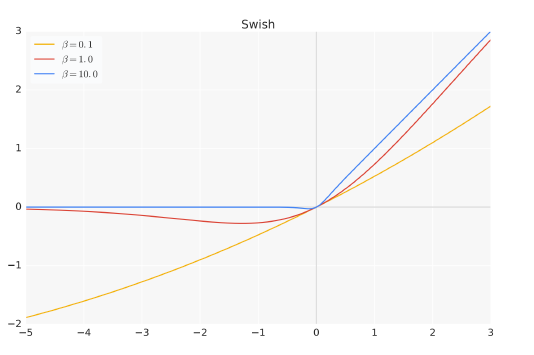
第二个方面,采用SwiGLU激活函数,它可以在维度减少的情况下,提高Transformer的性能。
SwiGLU(x,W,V,b,c,β)=Swishβ(xW+b)⊕(xV+c)
其中⊕表示逐个元素相乘,Swishβ(x)=xσ(βx), σ表示sigmoid函数,x表示输入,W,V表示模型参数,b和c表示偏移。
第三个贡献是受到GPTNeo的启发,采用了旋转位置编码(RoPE),它可以不使用决定位置编码的情况下,提高模型的外推能力。旋转位置编码是一种相对位置的信息集成到自注意力中的绝对位置编码。
此外llama模型优化器上选择快乐AdamW优化器,将权重衰减从梯度更新中分离出来,提高优化效果,采用了余弦学习率衰减,避免学习率切换时的震荡。
llama2模型
接下来就是llama1模型的改进版llama2模型,llama2模型也是一种基于Transformer的大规模预训练模型,参数量可以由70亿到700亿。 llama2模型结构和llama1模型模型结构相差无几。唯一多出来的一个创新点是使用了分组查询注意力(GQA)来提升模型的推理可拓展性。这里可以详细介绍一下
Group Multi Query Attention 分组查询注意力
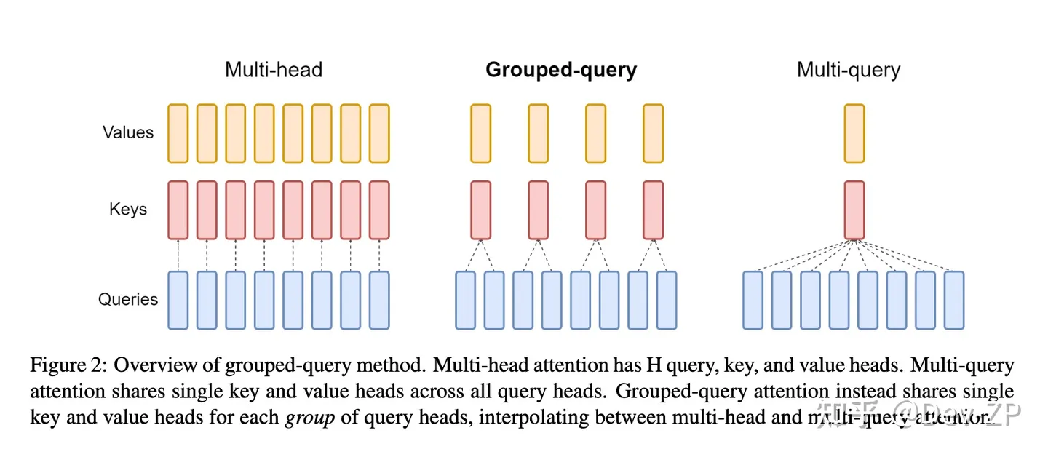
在各种多头注意力机制比较中,原始的多头注意力机制(MHA,Multi-Head Attention)使得QKV三部分具有相等数量的“头”,并且它们之间是一一对应的。每一次计算注意力时,各个头部的QKV独立执行自己的计算,最后将所有头部的结果加在一起作为输出。标准的MHA就是这样一个模型,其中Q、K、V分别对应了h个Query、Key和Value矩阵。
相对于MHA,多查询注意力(MQA,Multi-Query Attention)则略有不同。MQA保持了原来的Query头数,但是只为K和V各设置了一个头,即所有的Query头部都共享同一个K和V组合,因此得名为“多查询”。据实验发现,这种机制通常可以提高30%-40%的吞吐量,对性能的影响相对较小。MQA是一种多查询注意力的变体,被广泛用于自回归的解码。与MHA不同,MQA让所有的头部在K和V之间实现共享,每个头部只保留一份Query参数,从而大大降低了K和V矩阵的参数量。
分组查询注意力(GQA,Grouped-Query Attention)综合了MHA和MQA,既避免了过多的性能损失,又能够利用MQA的推理加速。在GQA中,Query部分进行分组,每个组共享一组KV。GQA把查询头分成G组,每个组内部的头部共享一个相同的K和V组合。当G设为1,即GQA-1,则所有Query都共享同一组K和V,这时的GQA等效于MQA;而当G等于头的数量,即GQA-H,那么这时的GQA等效于MHA,
训练数据上llama2模型的训练语料是一个新的公开可用的数据混合,不包含来自Meta的产品或者服务的数据。
Meta公司还针对llama2模型模型进行为微调,产生了llama-Chat的应用。
llama2-Chat 模型
训练奖励模型
llama2-Chat 模型依赖奖励模型的输入, 这个奖励模型的输入是模型的回答和提示,输出是一个标量的分数,作为强化学习过程中的奖励。这样可以让llama2-Chat 模型更符合人类的偏好。然后有用性和安全性有时会存在冲突,这可能导致单个奖励模型难以在两个方面都做到最优。为了解决这个问题,llama2-Chat 模型训练两个独立的奖励模型,分别针对有用性和安全性。llama2-Chat 模型选择从预训练模型的参数初始化奖励模型,这样可以保证两个模型能从预训练中学习知识。
为了训练奖励模型,llama2-Chat 模型将搜集到的成对的数据转换为二元排序数据标签格式。使用二元排序损失来优化奖励模型
Lranking=−log2σ(rθ(x,yc)−rθ(x,yl))
其中rθ表示标量分数,yc表示标注者选择偏好的回答, yl表示拒绝的回答,x表示提示。llama2-Chat 模型还分别对有用的奖励模型和安全模型进行了改进,并将评级分成了4级。为此,llama2-Chat 模型在损失中增加一个边界项
Lranking=−log2σ(rθ(x,yc)−rθ(x,yl)−m(r))
这个m®是一个根据偏好评级定义的离散函数。
迭代微调模型
llama2-Chat 模型主要是使用两种强化学习算法来微调模型的效果,分别是近端策略优化和拒绝采样,这两种算法主要区别在于广度和深度。
广度:近端策略优化只是生成一个样本,而拒绝采样会对每个提示生成K个样本
广度:近端策略优化的每个样本都是基于更新后的模型策略生成,该策略是根据前一个的梯度更新得到的,拒绝采样则是先根据模型的初始策略生成所有样本,再用类似于有监督微调的方法进行微调。不过,由于llama2-Chat 模型采用的迭代模型更新,所以两种算法之间差异不明显。
在人类反馈强化学习第4次更新之前,llama2-Chat 模型只使用拒绝采样进行微调。之后将近端策略优化和拒绝采样结合,先在拒绝采样的检查点上应用近端策略优化,再进行重新采样。
近端策略优化用来进一步训练llama2-Chat 模型的方案,它使用如下的优化目标
argmaxπEp∼D,g∼π[R(g∣p)]
p是从数据集D中采样提示,g是从策略π中采样生成。llama2-Chat 模型使用近端策略优化和损失函数来迭代改进策略。并最终使用奖励函数表示
R(g∣p)=Rcˉ(g∣p)−βDKL(πθ(g∣p)∣∣π0(g∣p))
其中DKL表示KL散度,用来防止策略π偏离原始策略π0.这个约束对于训练稳定性有帮助。Rcˉ(g∣p)是一个分段组合函数,它由安全性和有用性奖励模型组成。
大家可能发现了,这个过程中依赖的标注数据对标注人员的偏好具有很大的依赖,相比于这个标注,人类反馈强化学习在比较两个模型的输出好坏要更加简单,奖励机制能够快速给不好的长尾分配低分,并和人类的偏好一致。