今天来介绍另一个复杂的模型LSTNet模型, 这个时序模型是专门解决多元时间预测问题的,多元时间预测哦。 模型结构十分复杂,其中很多设计还是能有很多借鉴作用的,希望大家能够学习并且用到实际工作中。
LSTNet模型结构
老规矩,还是先看看整个模型的架构。看起来就十分的复杂。咱们从左往右一点一点介绍每个结构在干吗。
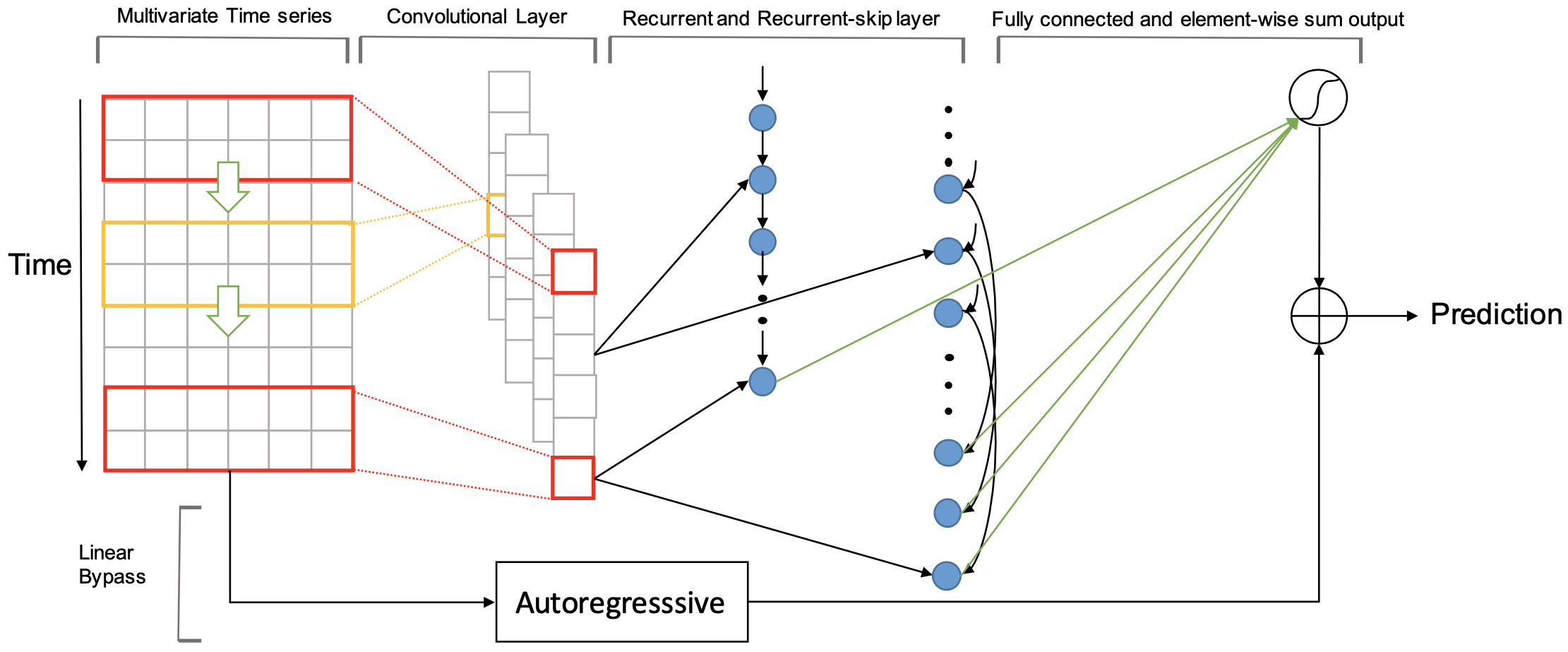
模型的输入是$Y=[y_{1},...,y_{T}]$, 其中$y_{t} \in R^{n}$,n是协变量的维度,预测$y_{T+h}$.
卷积层
LSTNet模型中的卷积层是没有pooling操作的,目标是抽取短期内的pattern,通过构建协变量之间的关系,第k个卷积核的形式如下
$$
h_{k}=RELU(W_{k}*X+b_{k}) \tag{1.1}
$$
这里的*是卷积操作,经过卷积层输出的数据的维度是$d_{c} \times T$, 其中T是$h_{k}$的长度。$d_{c}$表示卷积数。
循环神经单元
通过卷积输出的结果,就可以喂到循环神经单元中了,这里采用的GRU神经单元。其数学表达形式如下
$$
r_{t}=\sigma(x_{t}W_{xr}+h_{t-1}W_{hr}+b_{r})\\
u_{t}=\sigma(x_{t}W_{xu}+h_{t-1}W_{hu}+b_{u})\\\
c_{t}=RELU(x_{t}W_{xc})+r_{t}⊙(h_{t-1}W_{hc}+b_{c})\\
h_{t}=(1-u_{t})⊙h_{t-1}+u_{t}⊙c_{t} \\
$$
其中⊙表示对应元素相乘。$x_{t}$表示时间t层神经网络的输入。
跳跃循环神经网络
这部分是有一点特殊, 为了解决单纯使用GRU的情况下,仍然会有长时的pattern被遗忘的问题,所以这里采用了跳跃GRU的方式尝试解决这样的问题。这里需要一个超参数p,就是跳跃间隔,例如你选学习当前时间的用电量,是不是昨天同一时间或者上周同期这样的数据比较有用,这个p就是这个周期。一般是24h。这部分和上一步的学习是一致的,仅仅是输入数据加上了一个间隔,所以它的数学表达过程是。
$$
r_{t}=\sigma(x_{t}W_{xr}+h_{t-p}W_{hr}+b_{r})\\
u_{t}=\sigma(x_{t}W_{xu}+h_{t-p}W_{hu}+b_{u})\\\
c_{t}=RELU(x_{t}W_{xc})+r_{t}⊙(h_{t-p}W_{hc}+b_{c})\\
h_{t}=(1-u_{t})⊙h_{t-p}+u_{t}⊙c_{t} \\
$$
最后是合并循环神经网络和跳跃神经网络的值,最后神经网路的预测结果为。
$$
h_{t}^{D}=W^{R}h^{R}_{t}+\sum_{i=0}^{p-1} W_{i}^{S}h_{t-i}^{S}+b
$$
最后$h_{t}^{D}$就是预测值。上标S表示跳跃神经网络,上标R表示正常的神经网络结构。
时间维度的Attention机制
这里面作者其实也提出了一个Attention机制,为了解决上文中使用跳跃循环神经网络需要指定超参数的问题,对于有些问题并不好指定一个好的间隔值,所以使用如下的方法。学习一个attention参数$a_{t} \in R^{q}$. q是attention参数的维度。
$$
a_{t}=AttScore(H_{t}^{R},h_{t-1}^{R})
$$
其中$H_{t}^{R}=[h_{t-q}^{R},...,h_{t-1}^{R}]$, AttScore可以是相似度或者是点乘的计算方式。 这里就是枚举了前q个隐层的输出,然后与最近的输入做一个相似度的计算,形成这个attention的权重。
相应的中间的有上下文权重,$c_{t}=H_{t}a_{t}$,以及最后一个窗口的隐层输出$h_{t-1}^{R}$,最后的预测结果的表达为
$$
h_{t}^{D}=W[c_{t;h_{t-1}^{R}}]+b
$$
自回归矫正
观察入微的你一定能发现,上图中最下面一行似乎还有一些操作,是的,单纯的使用神经网络预测,一个主要缺点是输出的大小对输入的大小不敏感。然而,在的真实数据中,输入信号的大小通常会以非周期的方式不断变化,这会大大降低神经网络模型的预测准确性。所以又加入了自回归的部分。这部分是一个简单的AR模型,预测的结果是$h_{t}^{L} \in R^{n}$。参数规模是$W^{ar} \in R^{m}$, m是输入窗口的大小。
$$
h_{t,i}^{L}=\sum_{k=0}^{m-1} W^{ar}_{k} y_{t-k,i}+b^{m}
$$
最后的预测值也是毫无疑问的取和就完成啦。
$$
Y_{t}=h_{t}^{D}+h_{t}^{L}
$$
总而言之
其实纵观整个模型,还是对个人训练模型有些感触的,GRU可以采用跳跃GRU,深度和线性结合等。
原文地址: LSTNet