Wide&Deep
现在咱们就要看一下在推荐领域最经典的Wide&Deep模型了。被冠以集合了记忆和泛化能力的模型。其Wide 部分的主要作用是让模型具有较强的“记忆能力” memorization);Deep部分的主要作用是让模型具有“泛化能力”(generalization).
记忆能力
“记忆能力”可以被理解为模型直接学习并利用历史数据中物品或者特征的 “共现频率”的能力。一般来说,协同过滤、逻辑回归等简单模型有较强的“记忆 能力“。由于这类模型的结构简单,原始数据往往可以直接影响推荐结果,产生 类似于“如果点击过 A 就推荐 B” 这类规则式的推荐,这就相当于模型直接记住了历史数据的分布特点,并利用这些记忆进行推荐。
泛化能力
“泛化能力”可以被理解为模型传递特征的相关性,以及发掘稀疏甚至从未 出现过的稀有特征与最终标签相关性的能力 矩阵分解比协同过滤的泛化能力强因为矩阵分解引入了隐向量这样的结构,使得数据稀少的用户或者物品也能生成隐向量,从而获得有数据支撑的推荐得分,这就是非常典型的将全局数据传递到稀疏物品上 从而提高泛化能力的例子 再比如,深度神经网络通过特征的 多次自动组合可以深度发掘数据中潜在的模式,即使是非常稀疏的特征向量输入, 也能得到较稳定平滑的推荐概率 这就是简单模型所缺乏的"泛化能力”。
模型结构
说了这么多,现在咱们来看看这个模型的庐山真面目。
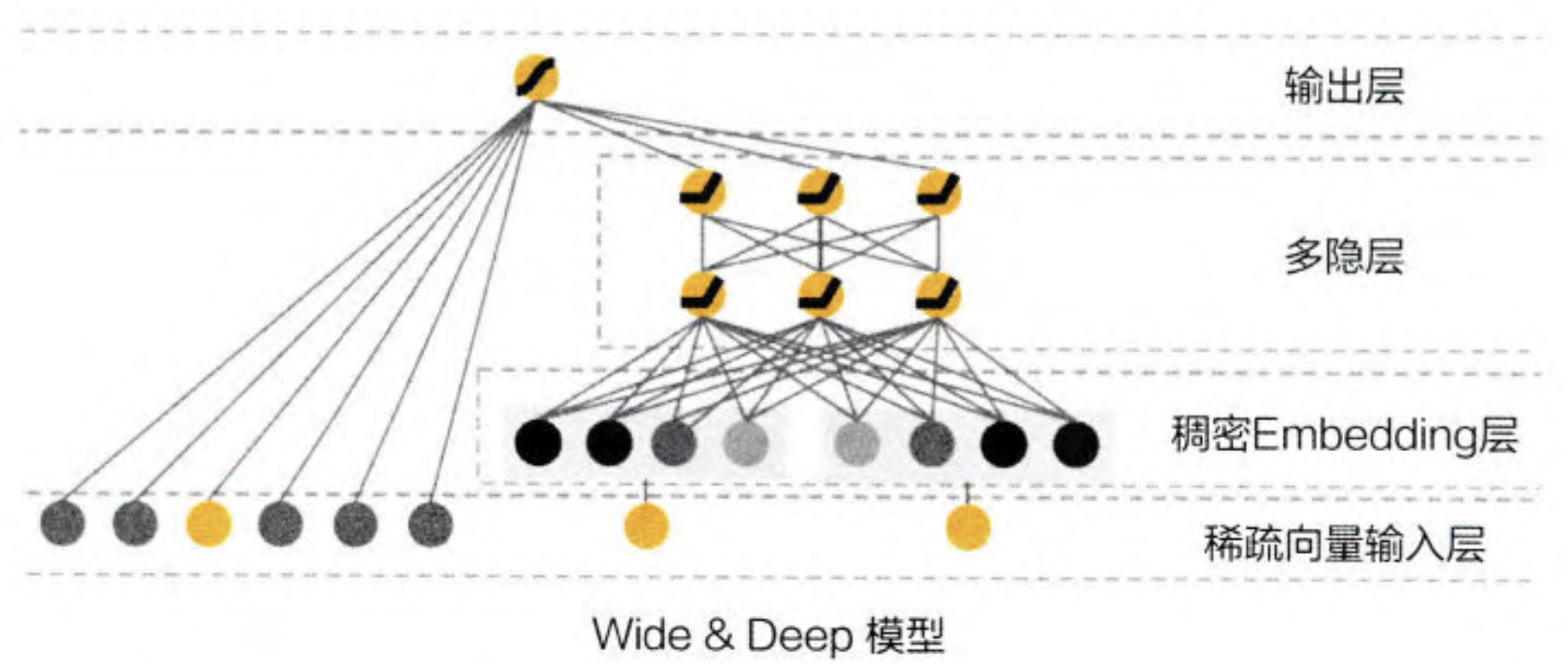
Wide&Deep 模型把单输入层的 Wide 部分与由 Embedding Deep部分连接起来一起输入最终的输出层。单层的Wide部分善于处理大量稀id 类特征 Deep 部分利用神经网络表达能力强的特点,进行深层的特征交叉挖掘藏在特征背后的数据模式。最终 利用逻辑回归模型 输出层将 Wide部分和Deep部分组合起来 形成统一的模型多隐层。 接下啦咱们可以看看 实际设计特征的时候如何使用这个模型。

Deep 部分的输入的是全量的特征向量,包括用户年龄、已安装应用数量、设备类型、已安装应用、 曝光应用等特征。稀疏特征需要经过 Embedding 层输入到连接层 Concatenated Embedding ), 拼接成 1200 维的 Embedding 向量,再依次经过3层ReLU全连接层,最终输入 LogLoss 输出层。
Wide 部分的输入仅仅是已安装应用和曝光应用两类特征,其中已安装应用 代表用户的历史行为,而曝光应用代表当前的待推荐应用。选择这两类特征的原因是充分发挥Wide部分“记忆能力”强的优势。正如上面所说的“记忆能力” 的例子,简单模型善于记忆用户行为特征中的信息,并根据此类信息直接影响推荐结果。
交叉积变换层
这里需要重点看下交叉积变换层是如何做的。以上图为例,“已安装应用”和“曝光应用”两个特征的函数被称为交叉 积变换 ( Cross Product Transformation)函数。
Θk(X)=Πi=1dxicki(1.1)
其中cki是一个布尔变量,当第i个特征属于第k个组合特征时,cki=1,否则为0,xi表示第i个特征的值。对于特征组合“AND(user_installed_app=netflix impression_app=pandora)”而言,只有当 “user_installed_app=netflix” 和“impression_app=pandora” 这两个特征同时为1时,其对应的交叉积变换层的 结果才为 1,否则为 0。
在通过交叉积变换层操作完成特征组合之后,Wide 部分将组合特征输入最终的 LogLoss 输出层,与 Deep 部分的输出一同参与最后的目标拟合,完成 Wide 与 Deep 部分的融合。
总而言之
对于wide&deep而言,核心的知识点都已经介绍完成啦,一个将简单模型和复杂模型结合以后综合计算的模型,对于比较好的输入是,简单模型有良好的记忆功能还是比较有用的。 对于模型的选型还是至关重要的。