这个话题咱们要开启一个新的系列啦,尽可能的讲清楚推荐系统的演变过程,以及其中都需要那些问题,并做出什么样的改动,最终取得什么样的效果。希望你能学到一些历史的基础上,还能思考自己做事情的过程。
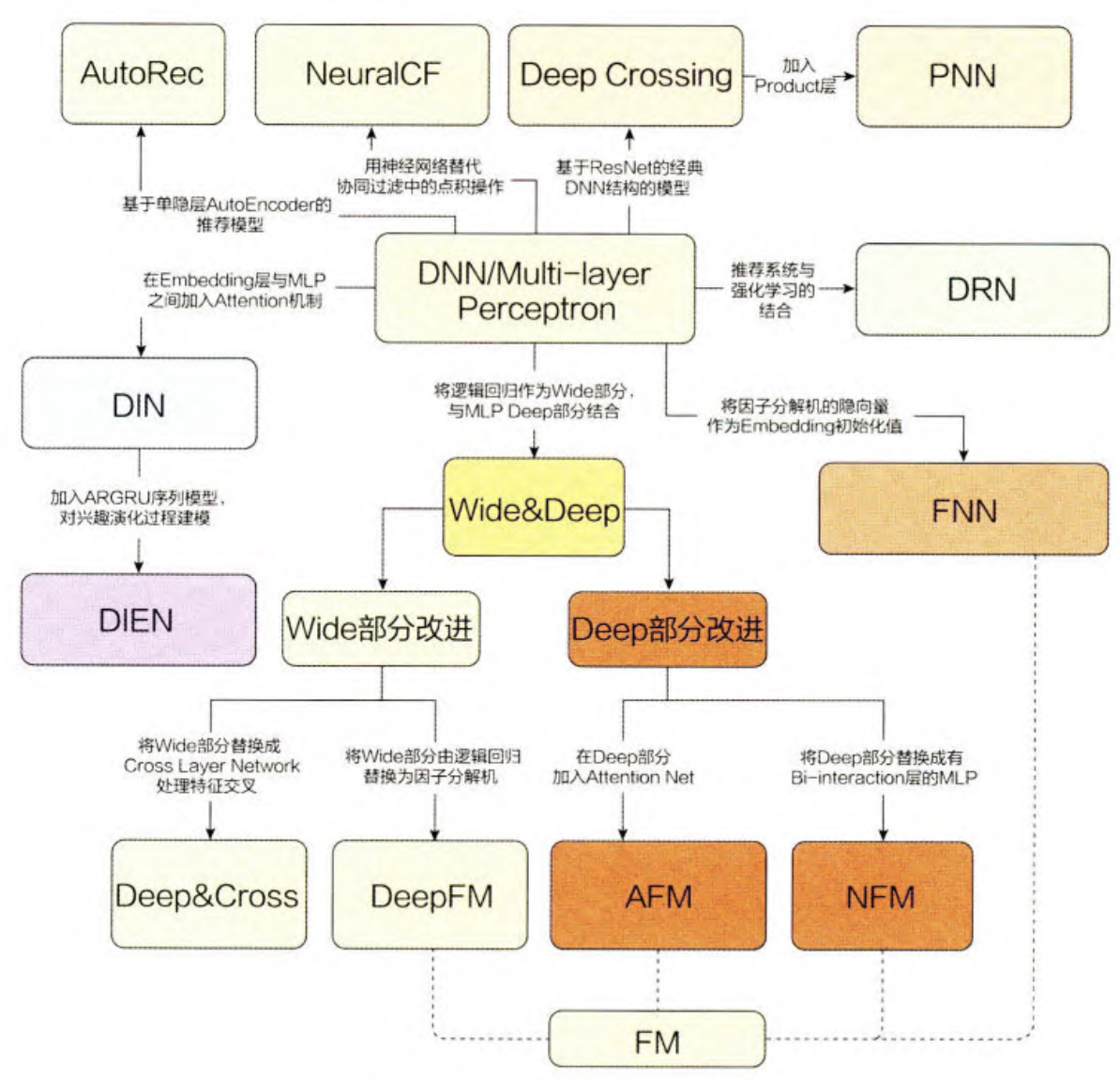
上面是为数不多能把整个推荐发展过程讲清楚的一张图,接下来的章节中,咱们会按照这个图一点一点的讲清楚技术的发展历程。
AutoRec 单隐层神经网络推荐模型
AutoRec 模型是一个标准的自编码器,它的基本原理是利用协同过滤中的共 现矩阵,完成物品向量或者用户向量的自编码。再利用自编码的结果得到用户对 物品的预估评分,进而进行推荐排序。
自编码器
编码器是指能够完成数据“自编码”的模型。无论是图像、 音频,还是数据,都可以转换成向量的形式进行表达。
假设自编码器的重建函数为h(r,θ),那么目标函数就是
minr∈S∑∣∣r−h(r,θ)∣∣2
S是所有的数据的向量集合,可以是打分特征也可以是类似one-hot特征,重建函数的参数数量远小于输人向量的维度数量, 因此自编码器相当于完成了数据压缩和降维的工作。
假设有 m 个用户,n个物品,用户会对n个物品中的一个或几个进行评分, 未评分的物品分值可用默认值或平均分值表示,则所有m个用户对物品的评分可 形成一个 m x n 维的评分矩阵,也就是协同过滤中的共现矩阵。
对于物品i来讲,所有m个用户对它的评分就可以表示为一个m维的向量,r=(R0,...,Ri).那么AutoRec的结构如下。
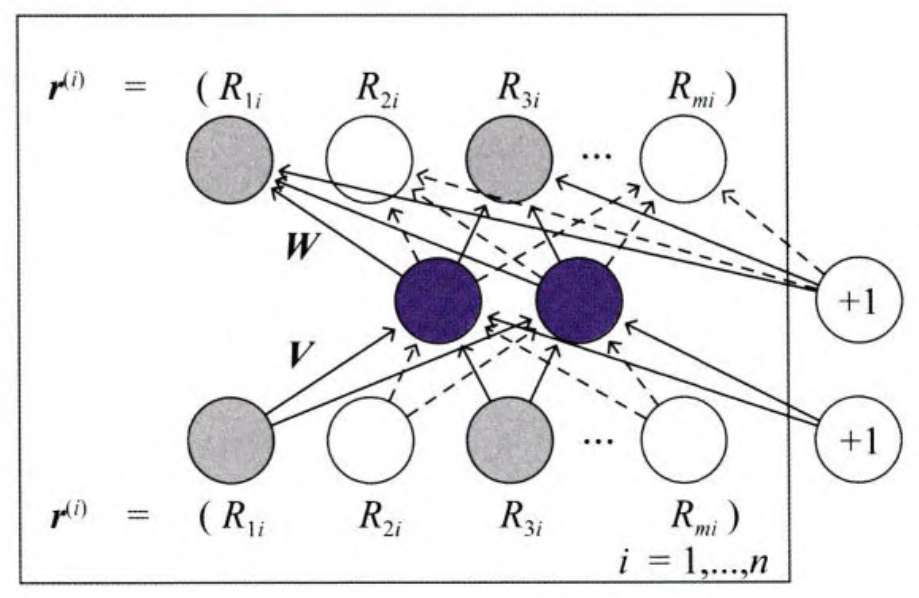
图中的 V 和 W 分别代表输入层到隐层,以及隐层到输出层的参数矩阵。重建函数的形式化表达为
h(r,θ)=f(W∗g(Vr+μ)+b)
其中f和g分别是输出层和隐层的激活函数。加入L2正则以后形式如下。
mini=1∑n∣∣ri−h(ri,θ)∣∣2+2λ∗(∣∣W∣∣2+∣∣V∣∣2)
由于 AutoRec 模型是一个非常标准的三层神经网络,模型的训练利用梯度反
向传播即可完成。
AutoRec使用过程
当输人物品 i 的评分向量为 ri时,模型的输出向量h(r,θ)就是所有用户对物品i的评分,通过遍历输入物品向量就可以得到用户 u 对所有物品的评分预测,进而根据评分预测排序得到推荐列表。不知道你发现了没有,类似的方式其实我们可以做于物品的 AutoRec 和基于用户AutoRec。以上介绍的AutoRec输入向量是物品的评分向量,因此可 称为 I-AutoRec( Item based AutoRec ),如果换做把用户的评分向量作为输入向量, 则得到 U-AutoRec ( User based AutoRec ) 在进行推荐列表生成的过程中, U-AutoRec 相比 I-AutoRec 的优势在于仅需输人一次目标用户的用户向量,就可 以重建用户对所有物品的评分向量。也就是说,得到用户的推荐列表仅需一次模 型推断过程;其劣势是用户向量的稀疏性可能会影响模型效果。
AutoRec的局限性
AutoRec 模型从神经网络的角度出发,使用一个单隐层的 AutoEncoder 泛化 用户或物品评分,使模型具有一定的泛化和表达能力。由于 AutoRec 模型的结构 比较简单 ,使其存在一定的表达能力不足的问题。不知道大家记不记得word2vec的nlp中的算法,其实AutoRec和word2vec类似的实现。 某种程度是可以替换的。