排序学习是搜索、推荐、广告的核心方法。排序结果的好坏很大 程度上影响到用户体验,甚至会影响到广告收益。常规的排序模型存 在一些问题,如调整参数困难,通过给定的一个测试集合来比较模型 是否过拟合很困难等。而机器学习解决了这些问题,因为其可以自动 调整参数。更重要的是,它可以通过规范化来避免数据过拟合。
传统的检索模型靠人工来拟合排序公式,并通过不断地实验确定 最佳的参数组合,以此构成相关性打分函数。机器学习排序与传统的 检索模型不同,可通过机器学习获得最合理的排序公式,而人只需要 给机器学习提供训练数据。
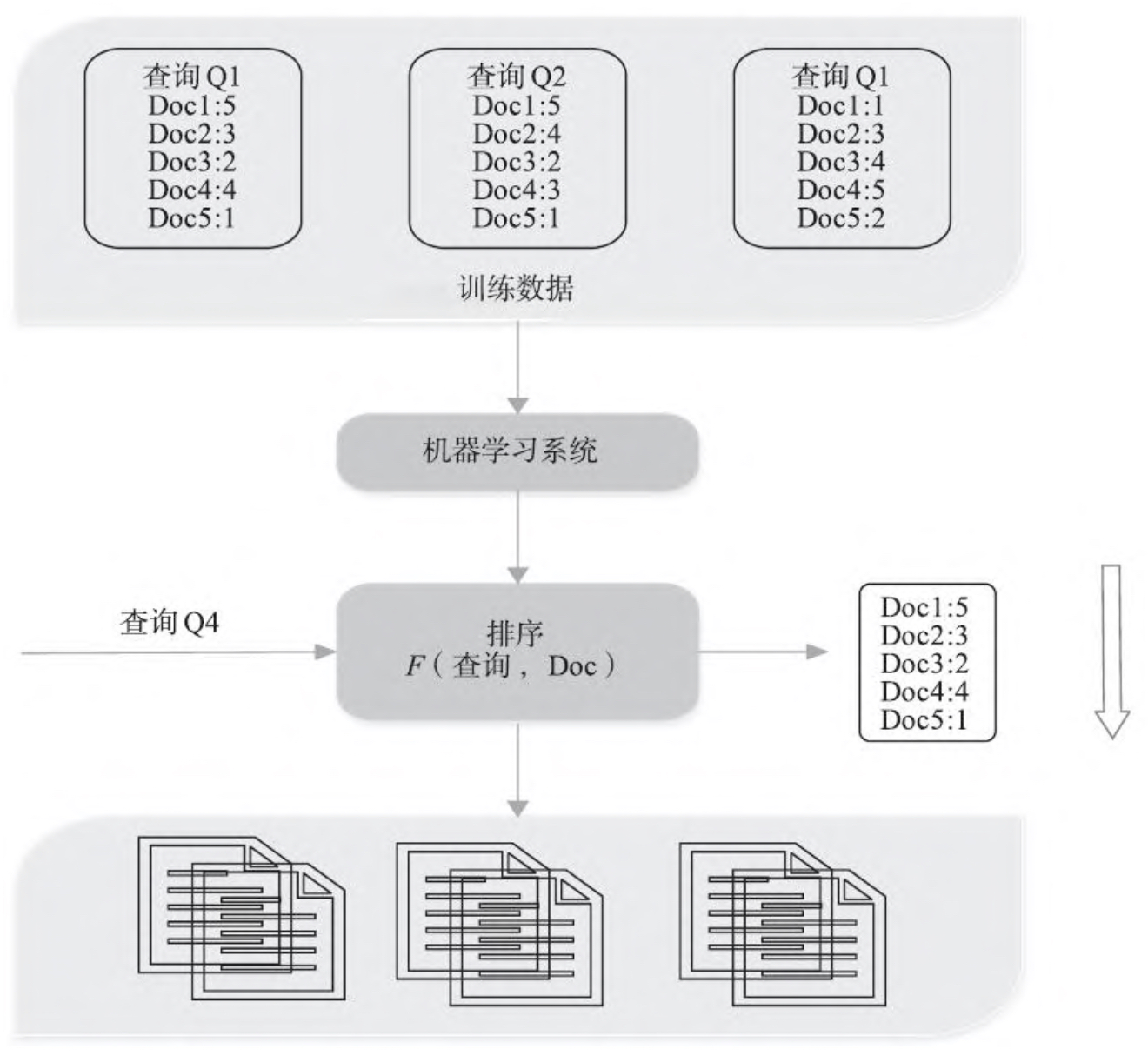
上图就是一个机器学习进行排序的基本原理,下面来看看机器学习怎么进行排序的学习呢?
单文档方法(Pointwise)
处理对象是单一文档,将文档转化为 特征向量后,将排序问题转化为机器学习中常规的分类或回归问题。 CTR方法是单文档方法的典型应用,相对比较成熟,广泛应用于广告、
搜索、推荐中。CTR方法的数学表达式:y=f(x),其中y的范围为[0, 1],y的值越大表示用户点击率越高。
这类方法比较简单,就是通过历史的一个点击动作,学习哪些文档被用户点击的概率最大就能够轻松实现排序。
单文档排序算法是点点之间排序,训练数据之间的关 系与最终排序无关。换句话说,样本经过模型训练形成的是一种评分 方式,而所有样本按照评分结果由大到小排序即可。模型生成后,每 个样本的输出结果是固定的、静态的,不会发生变化。这里典型的单 文档排序算法有逻辑回归、树模型等。
文档对方法(Pairwise)
相比于单文档方法算法,文档对方法 将重点转向文档顺序关系,是目前相对比较流行的方法。这种方法的核心思想是不关心每个文档实际的点击概率,而是关心不同文档放到一起的相对顺序。任何两个不同标记的文档都可以得到 一个训练实例(di,dj),如果di>dj标签就是1,反之就是0,于是我们就有了大量的训练数据,数据量也得到了有效的扩充,这样通过对召回结果的模型模型两两排序就能够实现整个顺序的有序。
排序算法都可以当作单文档排序。其根本逻辑就在于设定两个 分类1、0,在训练样本时考虑每个独立样本与当前分类的关系,生成 模型参数。在排序过程中,先计算每个样本当前参数耦合后的结果再 总体排序即可。而对于文档对方法,输入的是文档对。比如现在有三 个文档D1、D2、D3,排序为D1>D2>D3,那么输入应该是<D1,D2>、 <D2,D3>、<D3,D1>,对应的训练目标是“文档1是否应该排在文档2 的前面”。这种方法在模型构造上与大部分单文档方法可以共用原始 模型,好处在于模型训练出来的是对应文档组的排序关系,在复杂、 高维度、不易解析的情况下,有时会比单文档方法的排序结果更接近 真实值。其经典算法是RankNet
其缺点也很明显,其中一个缺点是由于模型输出的两个 文档之间有排序先后关系,如果靠前的位置出现错误,那么对于整体 排序的影响是远远大于单文档方法。另一个缺点是模型较难对输出结 果进行评价且训练困难,由于不同情况下文档之间的关系多种多样, 而且不同情况下,不同的输入对训练产生的影响不同,因此很难对模 型整体输出结果做出评价,同时,文档对方法一方面增加了标注的难 度,另一方面增加了训练的时间.
文档列表方法(Listwise)
与上述两种方法不同,其将每个查 询对应的所有搜索结果列表作为一个训练样例。根据训练样例训练得 到最优评分函数F,评分函数F对每个文档打分,然后根据得分由高到 低排序,得到最终的排序结果。这种方法的输入是文档集合,输出是 排好顺序的列表。
输入是一个文档列表,且每一个文 档的对应位置都已经锁定。例如,输入是[D1,D2,D3],那么该方法 认为单次样本的输入中,排序为D1>D2>D3。该方法的代表模型有Lamda Rank、Ada Rank等。得益于NDCG等新的评价方式,文档列表排序在模 型训练的过程中可以有效地迭代数据。而且由于输入的单个样本是一 组标注好的序列,模型在迭代的过程中也更容易贴近用户需求。文档 列表排序方法的缺点也有很多。首先,在理想情况下,其确实更容易 保证模型的排序结果贴近用户需求,但是这需要前期大量的标注工作 或者说对于使用场景有着明显的限制。其次,由于独立样本复杂,模 型的训练成本大于其他两种方法。最后,在现实生活中,我们往往很难能确定地输入单个样本的排序。我们还是要根据具体场景选择合适 的排序方法。
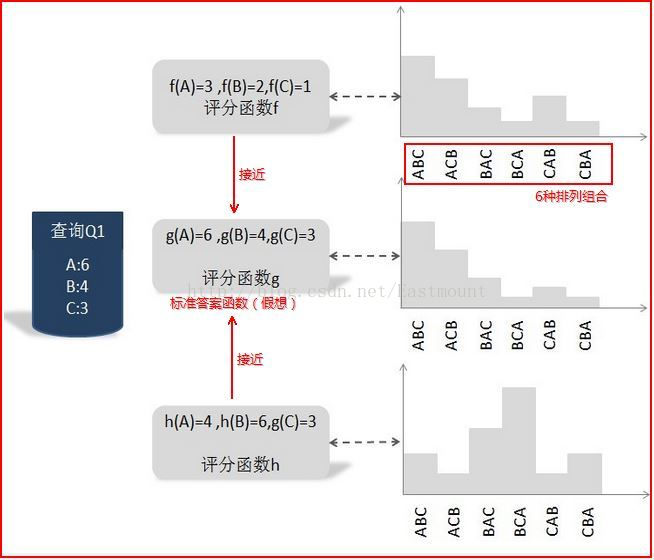
用户输入查询Q1,假设返回的搜索结果集合里包含A、B和C三个文档,搜索引擎要对搜索结果排序,而3个文档顺序共有6种排列组合方式:ABC、ACB、BAC、BCA、CAB和CBA,每种排列组合都是一种可能的搜索结果排序方法.
我们可以把函数g设想成最优评分函数(人工打分),对查询Q1来说:文档A得6分,文档B得4分,文档C得3分;我们的任务是找到一个函数,使得其对Q1的搜索结果打分顺序尽可能的接近标准函数g.其中函数f和h就是实际的评分函数,通过比较两个概率之间的KL距离,发现f比h更接近假想的最优函数g.故选择函数f为搜索的评分函数.
这里我们还是要详细讲解下,说起来容易,怎么讲类别放入到训练中呢?
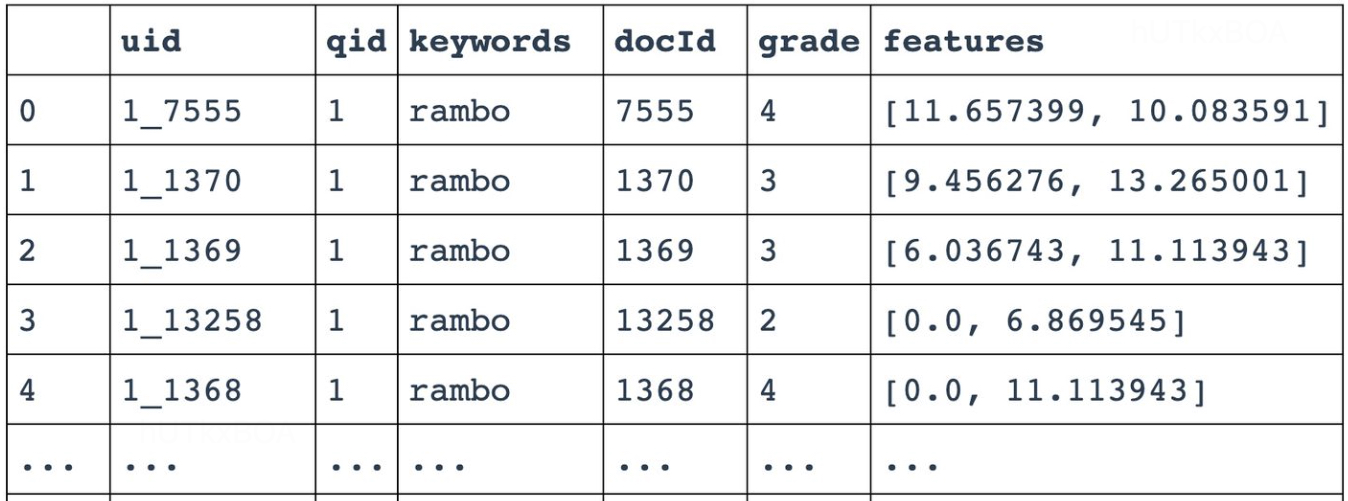
uid是一个sample的id,qid是query的id,keywords是query的查询内容,docid是对应该query的一个文档,grade是人工对该文档进行的label,features是文档被提取的特征。这里需要注意的是,grade在本文中是0-4,在真实情况下,可以是按照实际规则标记的打分。这样训练好的模型就可以根据新的输入进行打分的判断,从而在线上使用啦。
score=h(q,c)S=softmax([scorei])
q是query,c是候选集合.
将上面的结果与实际的关联度的归一化计算KL散度。
Y=∑yiY
当前关联度为1,2,3的时候,归一化后61,62,63.
还有一种稍微特殊一点的算法ListNet接下来介绍一下
ListNet
但让上面的形式也不是一成不变的,例如ListNet算法对于list定义为,
两层循环,一层是所有qid,一层是针对每个qid下的doc进行训练。目标函数是每个找出排列之后概率最大的组合。下面我们举个例子。
假如有s1,s2,s3需要排列的对象。那么s1排第一,s2排第二,s3排第三的概率表达形式如下。
P=σ(s1)+σ(s2)+σ(s3)σ(s1)+σ(s2)+σ(s3)σ(s2)+σ(s3)σ(s3)
其中σ就是要训练的参数。最后保证这个概率P与真实值的归一化分布一致。