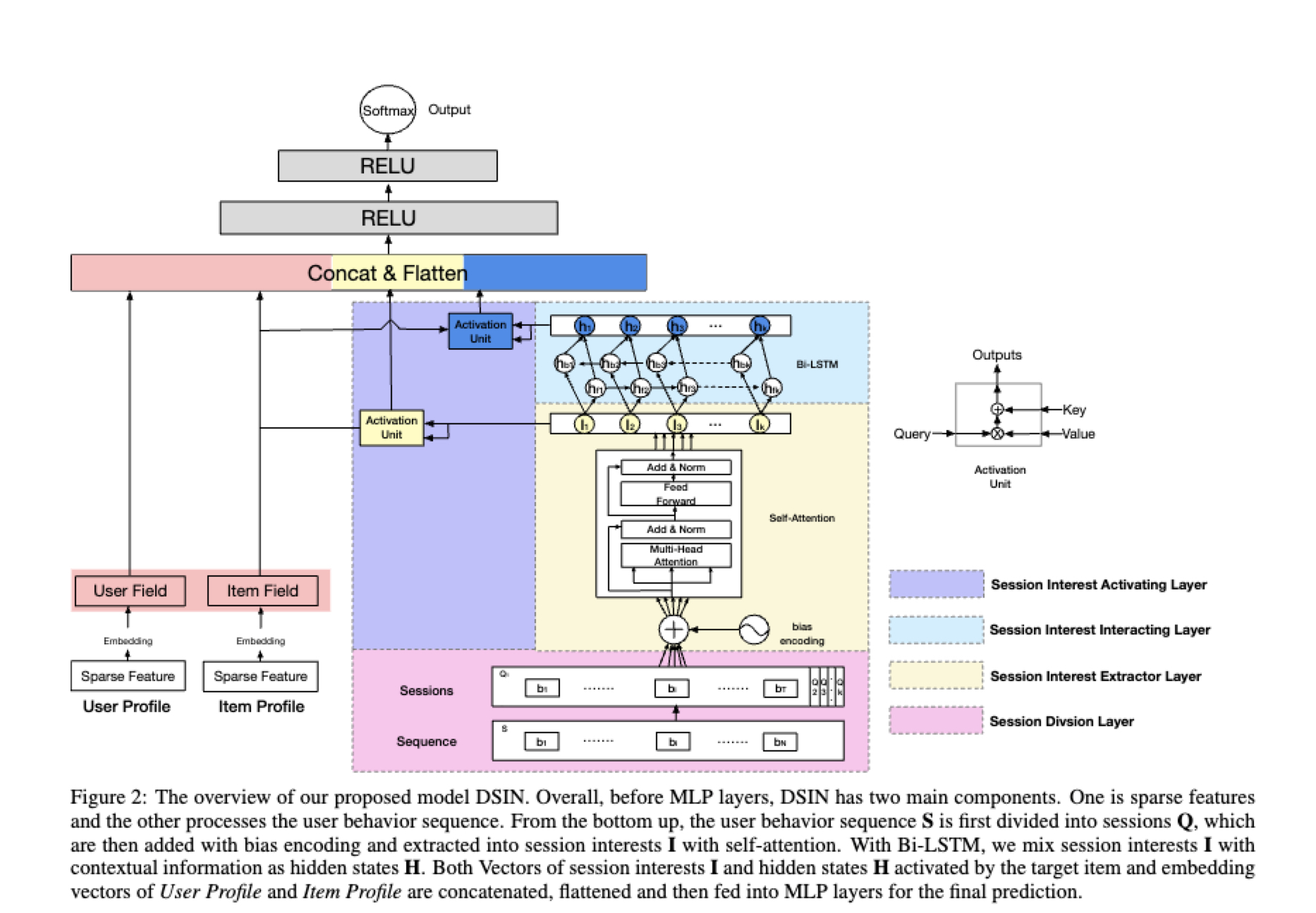
DISN
有用户历史行为虽然好,但是也需要节制。把用户的行为序列先分片(session) 能过滤掉一些噪声序列。
DSIN 针对 DIN 和 DIEN 没有考虑用户历史行为中的 Session 信息,因为每个 Session 中的行为是相近的,而在不同 Session 之间的差别很大,它在 Session 层面上对用户的行为序列进行建模;
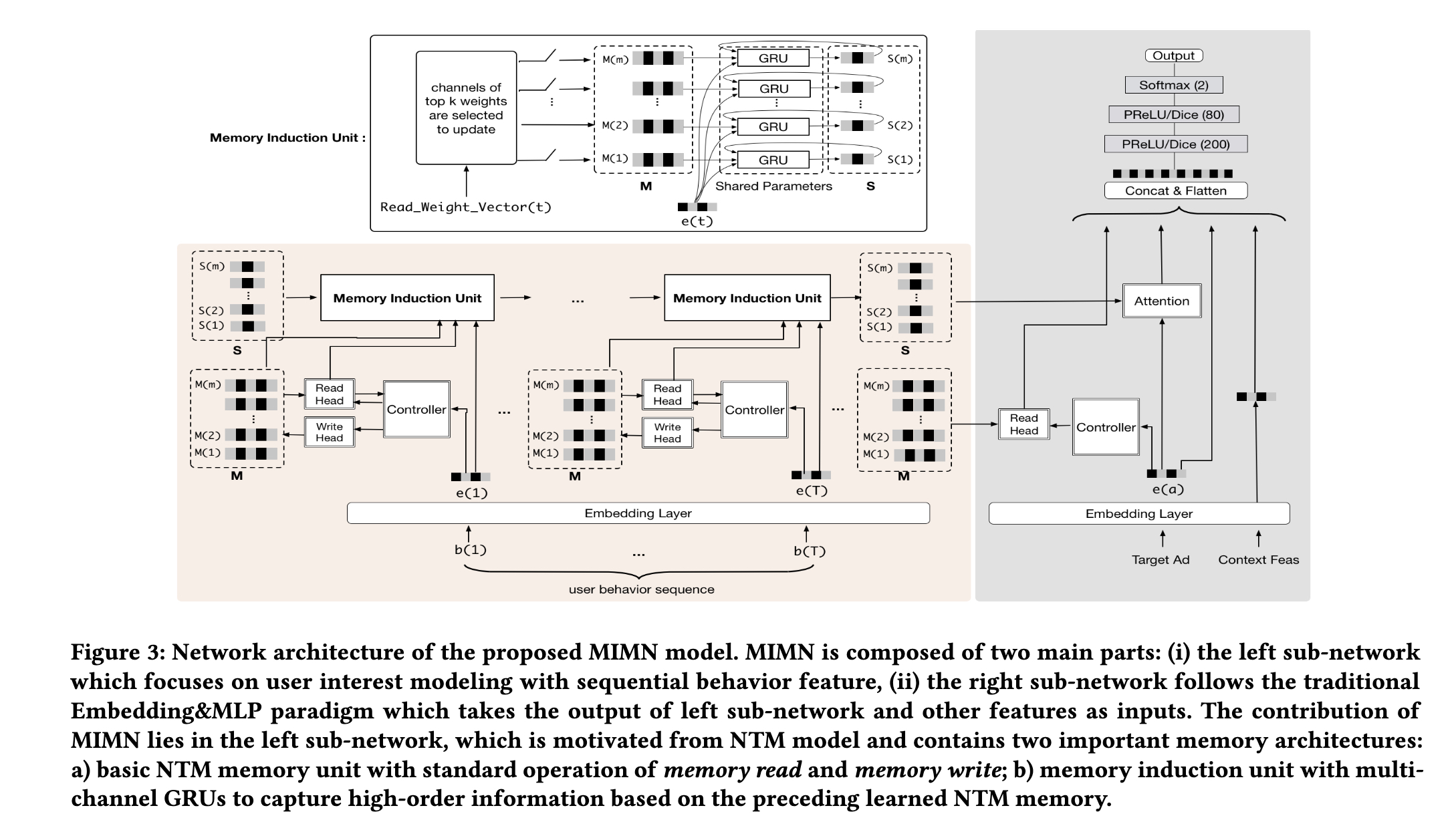
MIMN
MIMN算是本系列中,用户长期行为序列建模的开端,既然是开端,其核心要解决的问题也是长序列模型的推理开销问题。
自attention提出后,序列建模上效果比RNN系列模型好了很多,但随着用户行为序列的长度进一步增加,采用这种模型结构由于计算复杂度较高,同样无法满足线上延迟的需求。所以文章借鉴神经图灵机利用额外存储模块来解决长序列数据问题的思路。整个网络的左侧主要负责用户兴趣的建模,该部分的核心及创新点主要包括以下两个方面:一方面是NTM中基本的memory read和memory write操作;另一方面是为提取高阶信息而采用多通道GRU的memory induction unit。网络的右侧则为传统的embedding+MLP的经典结构。
问题
MIMN模型在一定程度上解决了推荐系统CTR预估中引入用户长序列建模的问题。但是当用户行为膨胀到数万数十万时,有限的兴趣memory向量维度难以完整记录用户原始的行为信息。
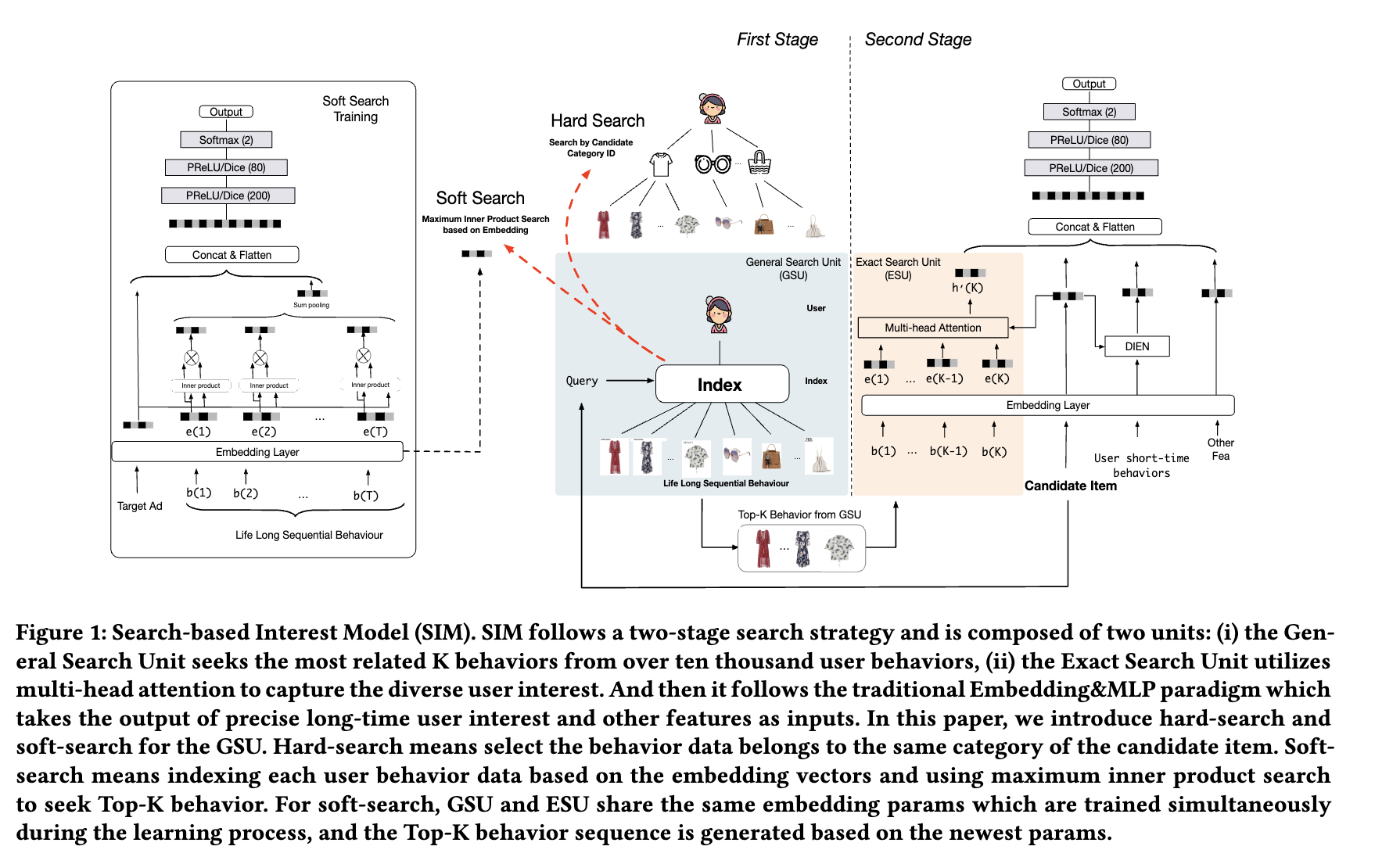
SIM
2020年阿里提出的两阶段搜索范式SIM模型,算是比较好的解决了超长用户行为建模带来的线上服务压力。
SIM的实现并不复杂,主要借鉴了DIN中通过候选广告搜索相关用户行为的方法。SIM利用两个阶段来捕捉用户在广告上的精准兴趣表达。
- 第一个阶段提出了GSU(General Search Unit,通用搜索单元)结构 。从原始的超长用户行为中根据广告信息搜索到和广告相关的用户行为。由于在线的计算和服务时长的限制,GSU采用了比较简单但是有效的方法来提取相关用户行为。搜索后的用户行为数据能够由原来的上万长度降低到数百长度,与此同时大部分和当前广告无关的信息都会被过滤。
- 第二个阶段提出了ESU(Exact Search Unit,精准搜索单元)结构 。利用第一阶段提取出和广告相关的用户行为和候选的广告信息来精准建模用户的多样兴趣。在ESU中,采用类似DIN或者DIEN这样复杂的模型来捕捉用户和广告相关的动态兴趣表达。
问题
虽然SIM能够处理上万甚至几十万的序列长度,但是也面临几方面的问题:
- 目标不一致 。GSU建立索引使用的item embedding不是SIM模型生成的,可能是预训练的,也有可能是直接拿item的类别建立的索引,比如是拿家电、女装、生鲜这样的类别,本质上是内容embdding上的索引。但是SIM模型本身的item embdding不一定是这样的内容embdding,要不然就不会有啤酒尿布这样经典的案例。
- 更新频率不一致 。SIM两阶段的更新频率不一致。线上模型都是以online learning的方式频繁更新的,以捕捉用户实时的兴趣变化,但是SIM中所使用的索引都是离线建立好的,成为性能的短板。