这个系列介绍一下模型的可解释性,这一部分经常被算法同学忽略掉,其实也经常有同学不被其他的业务线理解,感觉算法同学是不是在撞大运。是否真的能对自己学习出来的模型负责。
为什么要有模型解释性
这个时候你是否会问,我模型效果好就行呗,为啥还要搞这个可解释性,有那个功夫我多做几个模型是不是就好了。其实这个是一个好的问题,算法同学对业务的产出只能是模型吗,模型数量代表工作量吗?这个也是我之前错误认知的理念。 目前而言,我的理解是算法同学对业务的输出不仅是模型做了什么样的决策,而且要对业务输出认知,这部分对于产研以及运营都是至关重要的。那么就简单说说缺乏了可解释性的问题。
无法挖掘因果关系错判问题
本站中花了大量的时间介绍因果关系,相信大家已经不陌生,当使用黑盒模型的时候,经常关注的指标是AUC,但是即使AUC很高,我们依然不清楚黑盒模型的判断依据是否正确,这样特别是做银行保险业务的时候会举步维艰。经常会被问到,我到底是哪些条件不满足不给我放贷呢?
还有一些经典的例子是在医学上经常被提到,例如现在学习看了一个模型的AUC达到了0.86,准确率的来源是学习到了“如果病人得了哮喘,那么属于肺炎的低风险人群”,这个结论看起来时反常识的,通过深入分析以后发现是因为有哮喘病史的病人,由于病情的严重性,会得到进一步的治疗,降低了这类病人的死亡率,从而判断是肺炎的低风险人群。 但是落到实际就变成了,通过这样的判断,会导致部分带有哮喘的病人错过最佳的治疗时间。
黑盒模型不安全
这类的不安全性主要来自两个方面
建模人员
对于建模人员,由于黑盒模型的结构复杂,模型受到了外界的攻击的时候,通常十分难以发现。例如某些样本是黑客故意产生的,目的是提升模型的误判,从而带来一定的漏洞。
模型的使用者
对于模型的使用者,如果不了解模型的运行集机制,仅仅是利用模型决策,会产生很多风险。例如对于医药领域不仅要知道药物的用法和用量,还需要知道注意事项,存在哪些风险。病人了解到这些才能相信药物的使用。这个也是我在工作中经常问的问题,你训练了一个模型,你知道你的模型擅长做什么场景下的决策,不擅长做什么场景下的决策,直到了以后,你对模型的使用有什么改进吗?
当关注了模型的可解释性,带来的好处也是很多的。
- 可靠性强,易于产生信任。(生活中我们往往能够听取别人的意见,当别人说出决策的逻辑时候,我们选择采纳还是放弃,往往就是通过逻辑判断,模型只给你结果,会让你不知道应该采纳还是如何采纳的问题。)
- 判别和减少模型的偏差
- 启发特征工程的思路
- 改进泛化和性能
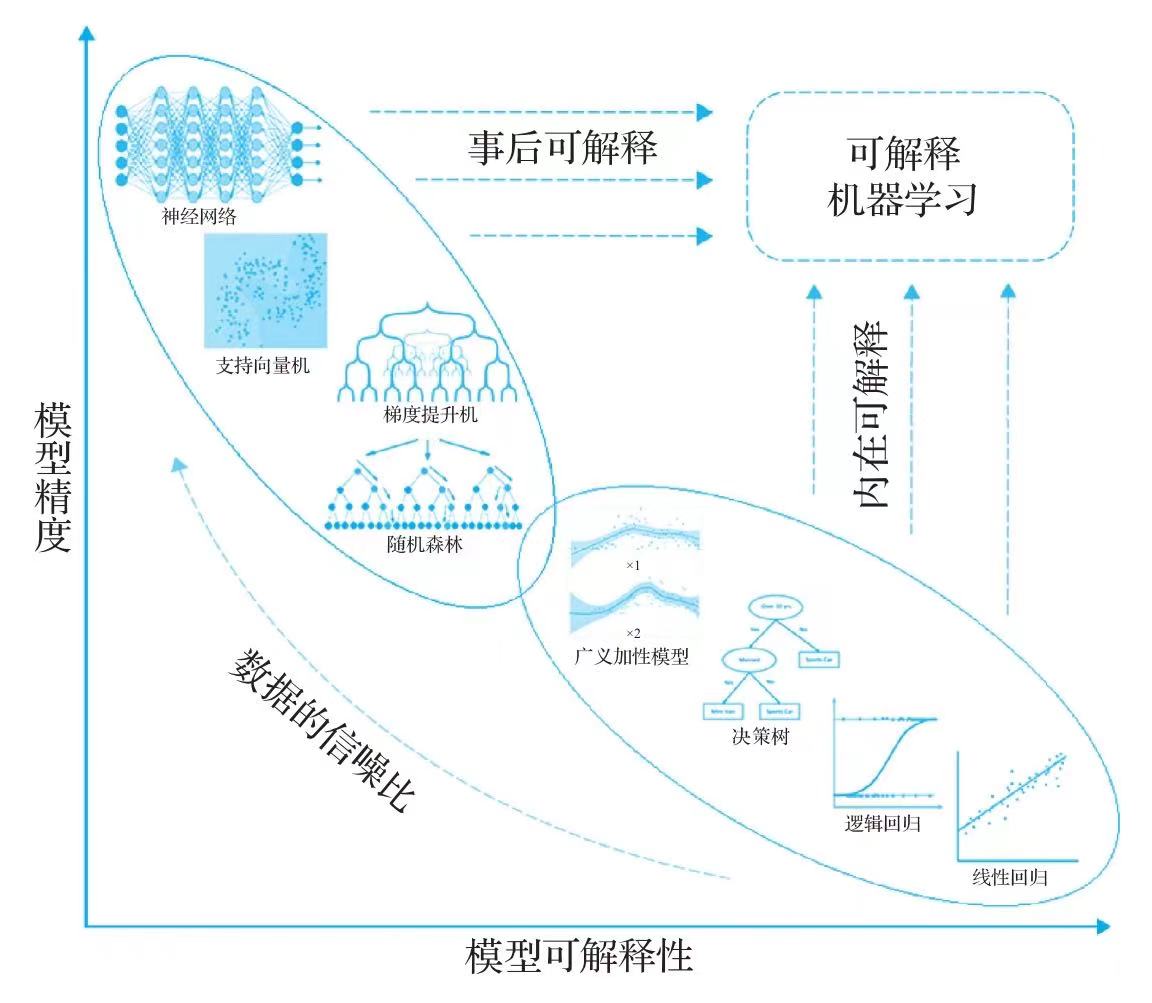
模型的可解释性
模型的可解释性可以分为以下几种形式。
内在可解释性
内在可解释性是指模型自身结构的特点,使用者可以清晰的看到模型内部结构,模型自带的可解释性效果,例如浅层次的树模型,以及线性模型。模型设计的时候已经考虑可解释性的问题。
事后可解释性
事后可解释性是指模型训练完以后,使用了一定的方法增强的模型的可解释性,挖掘模型学习的信息。这个系列里也会介绍一些这样的方法。
局部可解释性
局部可解释性是指case级别的解释,例如银行业务下,要对每个客户做出一个完整的回答,以及改进意见等等。
全局可解释性
全局可解释性是指整个模型的输入和输出上解释模型,可以通过规律和统计推断,理解每个特征对于模型的影响。例如像吸烟会导致肺癌这样的宏观结论。
可解释模型的研究方向
对于可解释性性模型的研究方向主要有两个,一种是基于统计模型一般具有较好的可解释性,但是模型的准确率却不能得到很好地保证,然后会有研究人员改良模型,使一些复杂模型具有一些好的可解释性。
另一方面对于目前的复杂模型,例如深度学习等,主要通过降低模型的复杂度换取解释性,另一方面就是利用事后辅助归因的方式获得模型的可解释性。