注意力机制主要是解决当处理大量信息的时候,注意力机制会选择一些关键的信息进行处理,忽略与目标无关的噪声数据,从而提高神经网络的效果。
注意力机制
注意力机制基本包括三个要素, 请求,键,值,如图1-1就是一个软性的注意力机制。
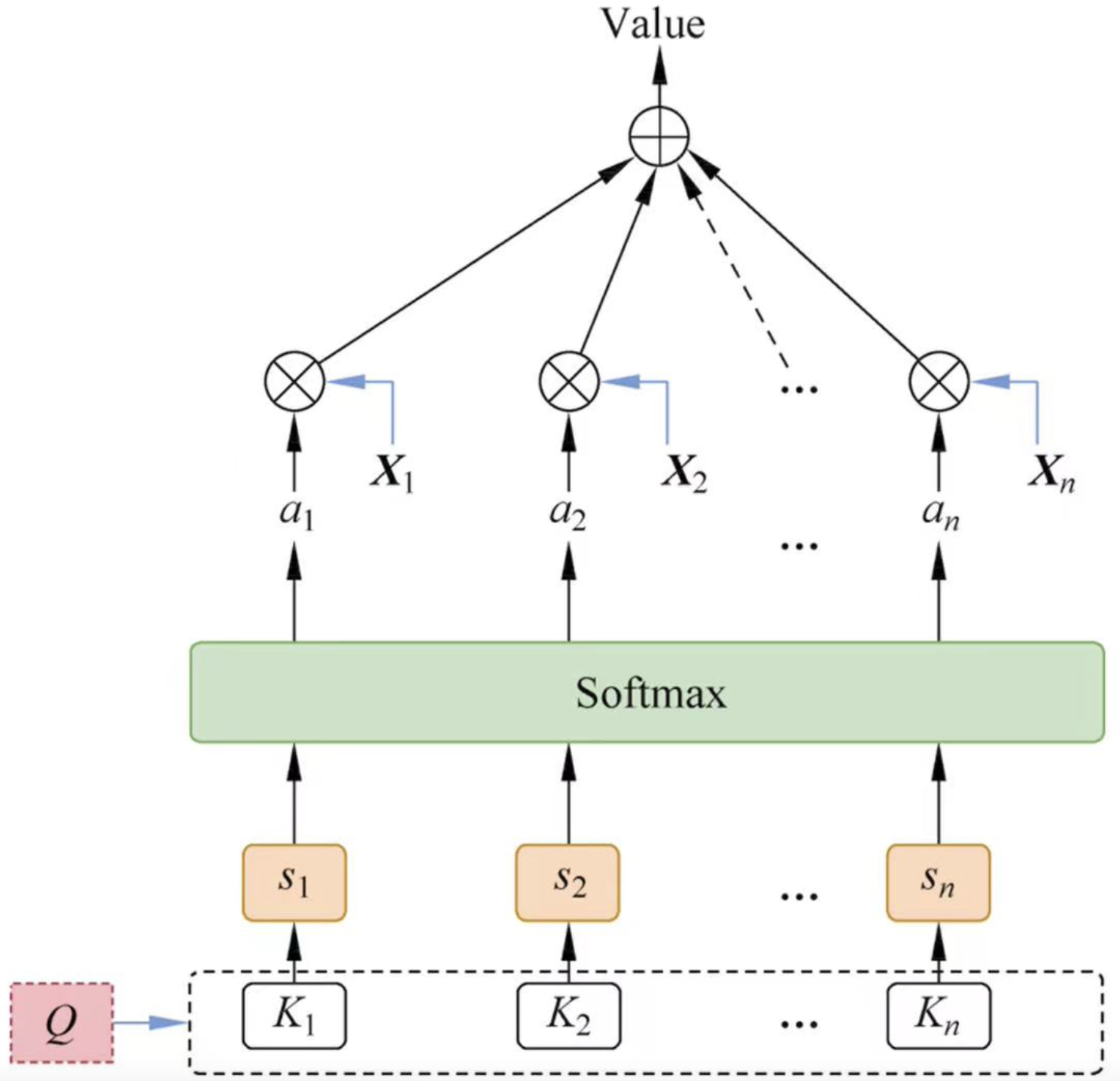
(K,V)是输入的键值对向量数据,包含n项信息,每一项信息的键用ki表示,值用xi表示,Q表示与任务相关的查询向量。Value是在给定值的情况,通过注意力机制从输入的数据中提取有用的信息,就是输出信息。一般分为三步
- 计算ki与Q的相关性得分。
- 将计算的相关性得分使用softmax函数进行归一化,称为注意力分布
- 根据注意力得分对输入数据X进行加权求和计算。
常用的注意力计算方法
点积模型
如果query和key一样长的话,那么可以用点乘也就是,内积的方式转换为注意力分数。
S(Ki,Q)=QTKi
缩放点积模型
S(Ki,Q)=dQTKi
矩阵相乘模型
S(Ki,Q)=QTWKi
余弦相似度模型
S(Ki,Q)=∣Q∣∗∣K∣QTKi
加性模型
S(Ki,Q)=VTtanh(WQ+UKi)
其中V,W,U都是可以学习的网络参数,d是输入数据的维度。
注意力分数是query和key的相似度,注意力权重是分数的softmax结果。·两种常见的分数计算:·
1.将query和key合并起来进入一个单输出单隐藏层的MLP·
2.直接将query和key做内积
注意力机制变体
硬性注意力
上文说的软性注意力会考虑所有的输入信息,硬性注意力只关注输入信息中的某一个位置的信息。
硬性注意力会选取高频的输入信息,或者注意力分布上进行随机采样选取信息。这个过程中可以理解是在输入数据中选择一个信息,将其注意力权重设置为1,其他信息都是0.硬性注意力效果是不稳定的。
局部注意力
软性注意力需要计算所有的输入信息,效果稳定但是计算量巨大,硬性注意力计算量小,但是效果不稳定。局部注意力则是软性注意力和硬性注意力的折中,其思路是使用硬性注意力定位到一个位置,然后以这个位置为中心点,设置一个窗口区域,在窗口范围内进行软性的注意力计算。
多头注意力
多头注意力使用多个任务目标Q,独立进行k次注意力计算,由于每次计算的q不同,所以每个注意力所关注的信息不同,这样可以从输入信息中抽取k个不同的信息,最后将k个学习进行拼接操作。
相对于基本的自注意力机制,它可以处理更多的信息,并且能够更好地表达不同的语义信息。
自注意力
自注意力模型动态的计算序列内信息权重之和,就能够建模变成序列内部的依赖关系(一般使用LSTM或者CNN)。
假设注意力模型输入序列X=[x1,...,xn],输出序列为H=[h1,...,hn],多输入数据X进行线性变换,得到以下的变量
Q=WQXK=WkXX=Wx∼X
其中Q,K,X分别表示查询向量,键向量,值向量。∼表示相似度计算
hi=j=1∑NSoftmax(s(qj,kj))X
自注意力计算序列数据的时候只考虑数据本身的信息,忽略了输入信息的位置关系,因此单独使用自注意力模型的时候,需要加入修正,具体做法可以参考Transformer模型。
注意力机制的优势
- 注意力机制能够有效的使模型忽略输入数据中的噪声数据,提升信噪比
- 注意力机制可以为输入数据中不同元素分配不同的权重系数,以突出与任务相关的信息元素。
- 注意力机制模型结果带来更好的解释性。