大模型的推理也是大模型领域需要研究的一个重要部分,涉及到推理的优化方法。
● 减小模型尺寸:常见的方法包括模型量化、知识蒸馏、权重共享等。这些方法可以减少存储空间的占用、提高模型的加载速度和推理速度等。
● 减少计算操作:常见的方法包括模型剪枝和稀疏激活等。这些方法的核心思想是用更高效、计算量更少的操作来代替模型中原有的操作
知识蒸馏
知识蒸馏不是一个新的概念, 相信大家应在其他的机器学习的背景知识上了解了这一个名词, 所谓知识蒸馏是将一个比较大参数的网络,用一个比较小的参数网络进行表示,进而起到压缩模型的作用。

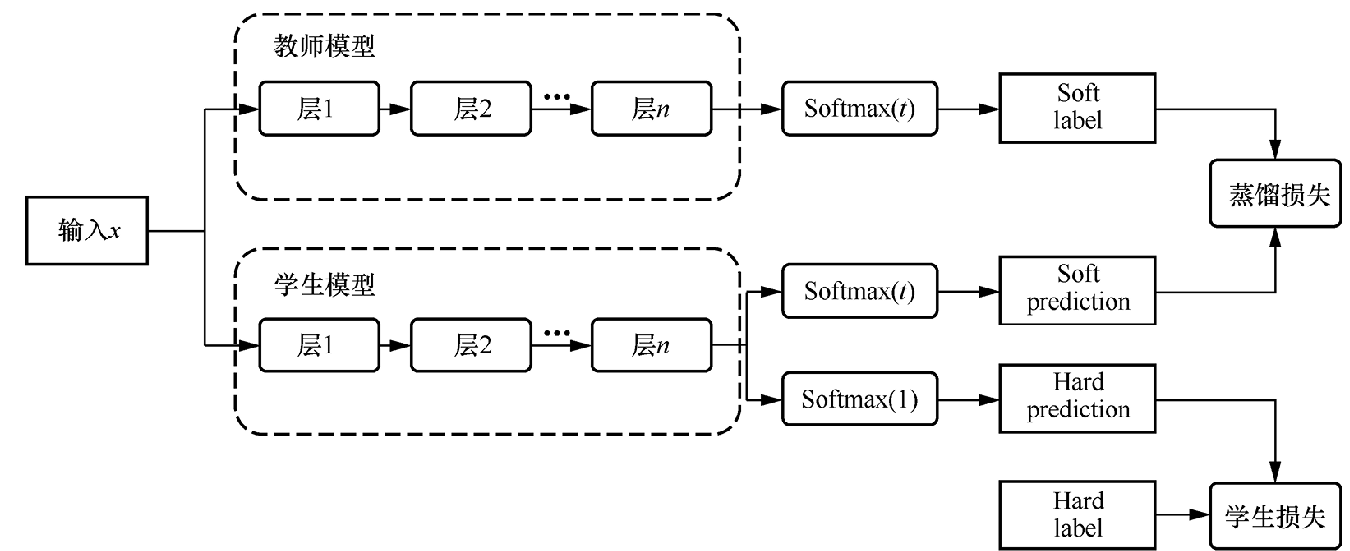
上图就是一个典型的教师-学生网络,知识蒸馏采用了教师-学生(teacher-student)模式。在该模式中,已训练完成的大型模型被称为教师模型,小型模型被称为学生模型。对于一个分类任务,训练数据集中的标签称为Hard label(在训练数据集中,除了正标签以外,其他负标签都是0),教师模型预测的概率输出为Soft label(在该输出结果中,每个类别基本上都分配到一定的概率,从而提供更为丰富的信息),Temperature代表用来调整Soft label平滑程度的超参数。
,知识蒸馏方法为学生模型提供了更为多样和丰富的信息。学生模型不仅能够学习到正确的分类结果,而且可以通过学习教师模型的输出结果捕捉到数据之间的复杂关系和不确定性。理论上,这种方法有望获得比单独训练学生模型(仅通过Hard label拟合训练数据)更好的性能。此外,Soft label的概率分布熵越大,表明其包含的信息量越大,对学生模型的学习也越有益。
蒸馏方法
对于一个向量z=[z1,..,zn], 对于某一个元素的softmax值可以如下的计算。
softmax(zi)=∑iezjezi(1.1)
但经过实践检验,在使用一般形式的 Softmax()方法时,教师模型输出的 Soft label 分布熵相对较小,负标签的值接近于0,对于损失函数的贡献可以忽略不计。所以,可以考虑在公式中增加温度变量T,并将Softmax()方法改写为如式(1.2)所示的形式。
softmax(zi)=∑iezj/Tezi/T(1.2)
其中,温度T的值越大,Softmax()方法的输出结果的分布越趋于平滑,这意味着各个类别的差异会相对减小。在这种情况下,输出的分布熵也会随之增大,不确定性持续增加。值得注意的是,较大的温度T的值会相对放大负标签所携带的信息,使得模型在训练过程中更加关注负标签。
在了解上述知识后,接下来介绍知识蒸馏的具体步骤:第一步,训练教师模型,使其能够在特定任务上取得较高的性能;第二步,在温度T下,教师模型产生Soft label,这些标签中包含了模型对各个类别的概率预测;第三步,使用Soft label和Hard label同时训练学生模型,在这一过程中,学生模型不仅需要学习如何正确分类样本,还需要模仿教师模型的概率输出结果;第四步,当模型训练完成后,设置温度T为1,模型在不受温度的干扰下进行推理。需要注意的是,高温蒸馏过程中的目标函数的损失值由蒸馏损失(distill loss,对应学生模型输出结果与教师模型输出结果之间的差异)和学生损失(student loss,对应学生模型在温度T为1的情况下,输出结果与真实标签之间的差异)加权得到,如下图所示。这种加权方式允许我们在训练过程中平衡两者的重要性,从而实现更有效的知识传递和学生模型学习。
目标方法的损失值的计算公式可以简化为如下所示的形式。
L=αLsoft+βLhard(1.3)
SOFT 部分
教师模型在温度T下产生的Softmax()输出结果作为Soft label,学生模型在同样的温度T下的输出结果与Soft label进行交叉熵计算,以衡量学生模型与教师模型之间的差异Lsoft
Lsoft=−i∑NpiTlog(qiT)(1.4)
piT是指教师模型在温度T下经由Softmax()方法计算输出的第i类的概率
qiT是学生模型在同等条件下的输出结果,N代表总的标签数量。
HARD 部分
学生模型在温度T等于1的条件下的输出与真实标签之间的交叉熵构成了损失函数的Lhard,计算如下
Lhard=−i∑Ncjlog(qi1)(2.1)
cj代表真实标签的取值(取值范围包含0或1).
qi1代表学生模型在温度T等于1的情况下在第i类上的输出概率.
Lhard的作用是有效降低错误被传递给学生模型的风险,因为即使教师模型的知识远超学生模型,但仍然有出错的可能性。这时,如果学生模型能同时参考教师模型的输出和真实标签值,就可以有效降低被教师模型的偶然错误所误导的可能性,并能学习教师模型的泛化能力。
特征蒸馏

在模型结构上学生模型更深、更窄。在上图中,需要使用教师模型的隐层输出对学生模型进行训练,这一过程称为特征蒸馏。
模型剪枝
受制于低延迟(low latency)、高吞吐(high throughput)、高效率(high efficiency)的挑战,模型剪枝(pruning)是比较低成本将大模型部署于真实工业场景时的常用技术。模型压缩算法可以将参数量庞大、结构复杂的大型预训练模型压缩为对硬件需求更低、推理速度更快的小型模型。在众多模型压缩方法中,模型剪枝因其简单和高效的特性而广受欢迎,它的核心思想是减少模型中不重要的权重。
模型剪枝又可以称为模型稀疏化,它通过剔除模型中不重要的参数,以达到减少参数量和计算量的目的。经过实验验证(主要以直方图的形式对网络各层的权重数值进行统计),研究者发现在训练前后,网络各层权重的数值分布与正态分布类似,即数值越接近于0,权重分布越多,这种现象被称为权重稀疏现象。
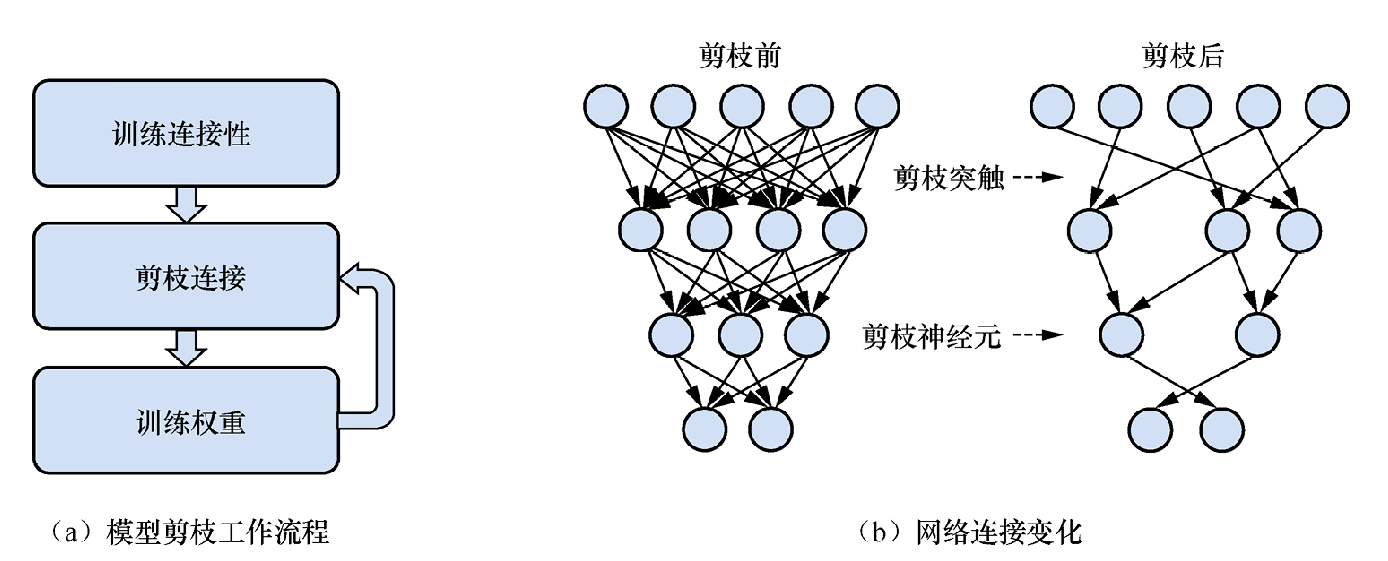
一些研究表明无论输入的图像数据的类型如何,卷积神经网络中的许多神经元都具有较低的激活率。由于神经网络的基本计算过程涉及乘法、加法和激活计算,大部分输出为0的神经元对后续计算过程的影响非常小,因此可以使用数学方式评估每个经元的所有连接也会被剔除,如果仍以修剪前的权重初始化模型,那么会造成一定的性能损失。因此,重新训练网络是必要的,它有助于恢复因剪枝而损失的精度,并提高剪枝后网络的性能。
神经元的重要性,并对不重要的神经元进行剪枝。使用该方法时需要对剪枝后的网络重新进行训练。这是因为,当剔除某个神经元时,与该神经元的所有连接也会被剔除,如果仍以修剪前的权重初始化模型,那么会造成一定的性能损失。因此,重新训练网络是必要的,它有助于恢复因剪枝而损失的精度,并提高剪枝后网络的性能。
稀疏激活
如果模型在应对特定的任务或数据样本时,仅有一小部分的神经元被激活,这类模型可被称为稀疏激活模型。稀疏激活模型能够在提升模型参数规模的同时降低所需的算力。研究表明稀疏激活模型在处理多任务时表现出更强的能力。
稀疏激活模型的优势在于能够极大地降低模型的算力成本。超大型预训练模型的训练和推理过程是计算密集型的,这意味着几乎所有的参数都会参与计算。当模型的规模增加时,这种全激活方式所带来的算力成本也会急剧升高。首先利用大模型的神经元激活稀疏性,在稠密模型上进行模块化划分,然后根据任务的不同激活部分模块,实现计算成本的有效降低。
此外,稀疏激活模型还具有多任务处理的灵活性。激活部分是由模型本身根据任务需求自动选择。而全激活型模型在应对不同的任务时需要激活所有的同一套参数,这样反而会出现“多而不精”的问题——如灾难性遗忘(模型在学习新任务后忘掉之前学习的能力)。
MoE技术
接下来就要和大家介绍MoE技术啦。
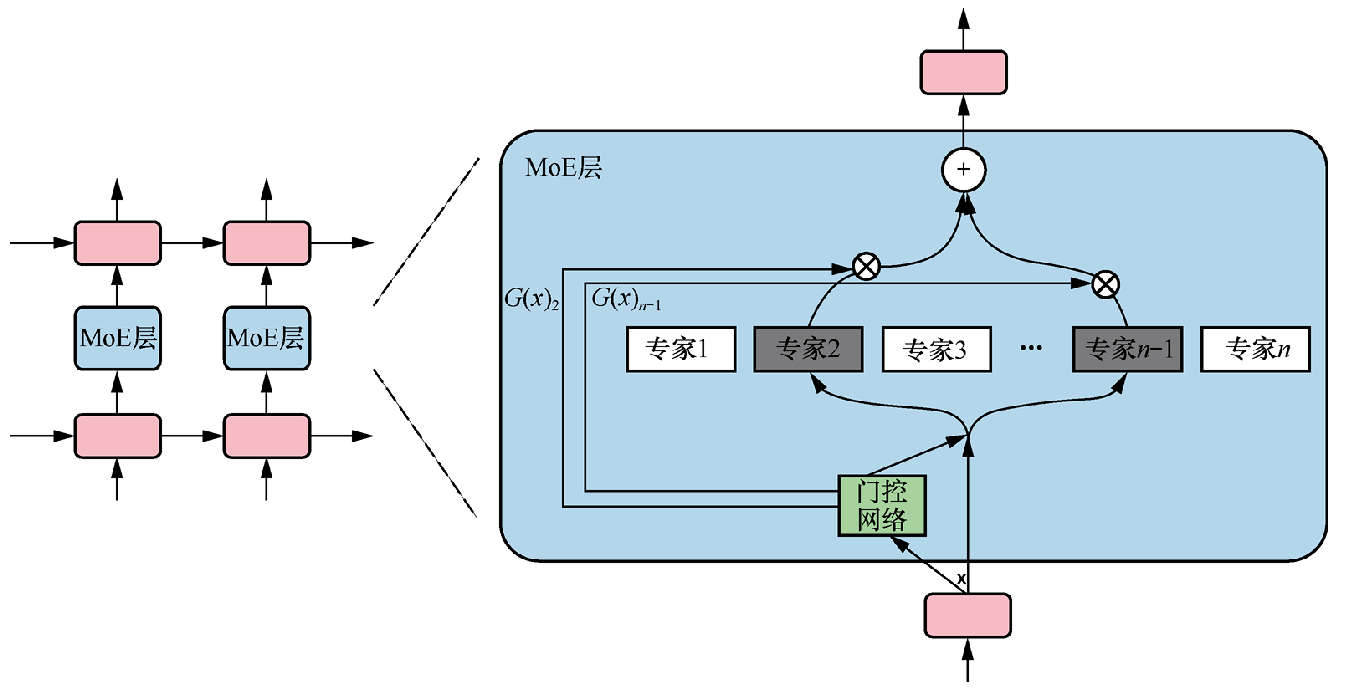
MoE 模块由多个专家组成,其中包含一个可训练的门控网络,该网络负责选择合适的专家,组成稀疏组合,以处理输入样本。专家本身可以是前馈神经网络等结构。
具有代表性的、使用MoE技术的Switch Transformer模型解决了MoE的设计复杂、通信成本高、训练不稳定的缺点。其中,最直观的改进在于更为简化的MoE结构,将Transformer中的前馈网络视为专家,使用Switching FFN层(包含多个前馈子层)来替代Transformer中的前馈网络。不同的输入只会选择Switching FFN层中的一个前馈网络进行计算,同时使用最简单的路由策略(每个任务只分配给一个专家)以降低计算量。相较于原来的模型结构,新架构增加了路由选择的计算量,而新增的计算量相比于原来的计算量可以忽略,这样实现了增大模型参数的同时维持相对不变的计算量,如下图所示。
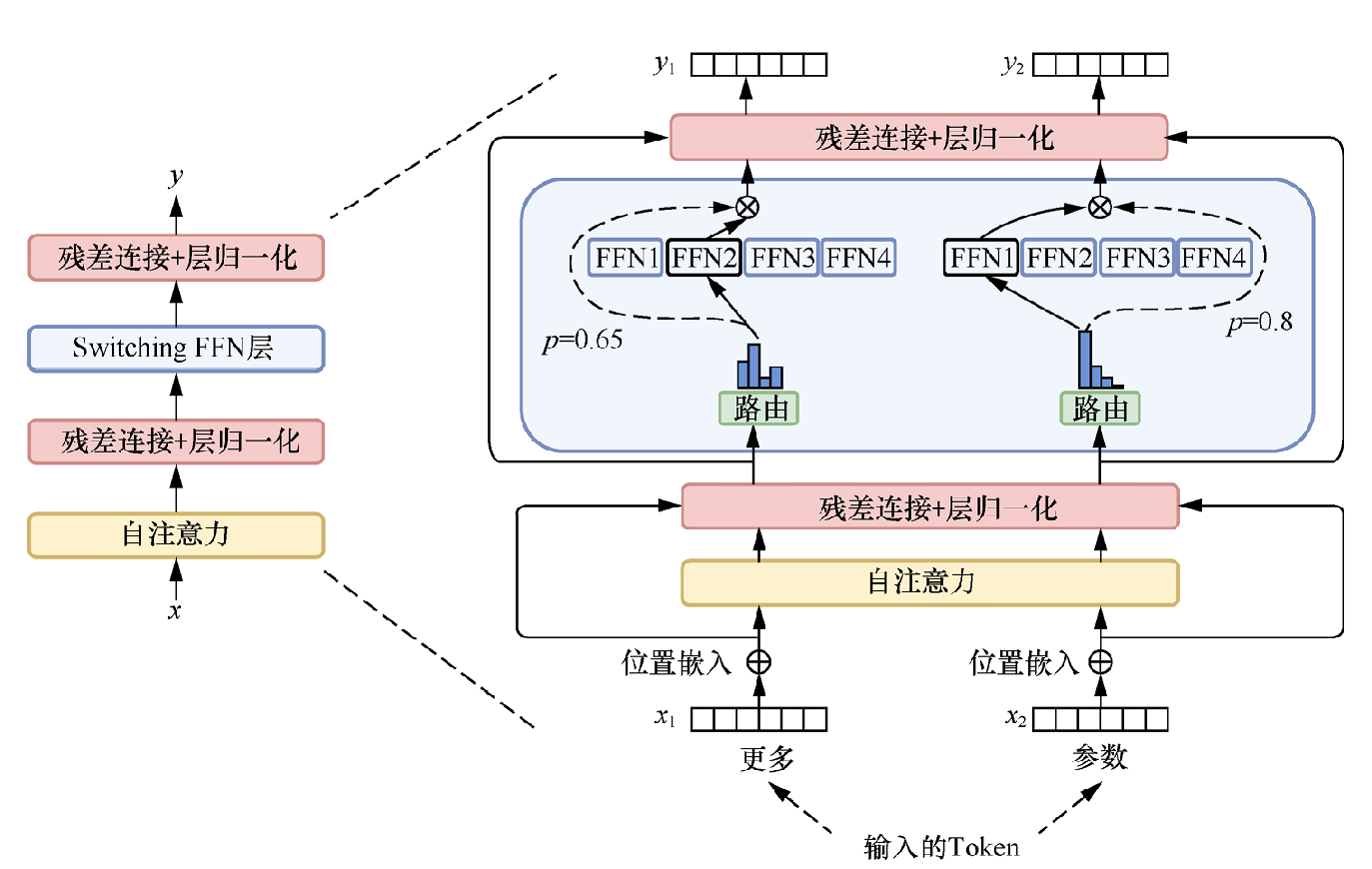
同时,Switch Transformer模型也引入了容量因子(Capacity Factor)这一组件,用于调控每个专家能够处理的任务量。当一些专家的任务过多时,该组件能够动态地分配任务,以优化计算和通信成本。
MoE需要考虑负债均衡的问题, 例如不希望任何推理都只有一些专家网络激活,而其他的网络使用率很低。一般会选择topK进行多个结果的加权。