今天要说的DIN模型是产自阿里巴巴推荐团队,它的应用场景是阿里巴巴的电商广告推荐。
无论是用户还是广告,都含有两个非常重要的特征–商品id(good_id)和商铺id(shop_id)。用户特征里的商品id是一个序列,代表用户曾经点击过的商品集合,商铺id 同理;而广告特征里的商品 id 和商铺 id 就是广告对应的商品 id 和商铺 id。基于base模型的一些缺点,例如用户特征组中的商品序列 和商铺序列经过简单的平均池化操作后就进人上层神经网络进行下一步训练,序列中的商品既没有区分重要程度,也和广告特征中的商品 id 没有关系。而经过事件的认知,广告特征和用户特征的关联程度是非常强的。
一个例子
这里可以列举一个例子,假设广告中的商品是键盘,用户的点击商品序列中有几个不同的商品 id 分别是鼠标、T 恤和洗面奶。从常识出发,“鼠标” 这个历史 商品 id 对预测“键盘”广告的点击率的重要程度应大于后两者。从模型的角度来说,在建模过程中投给不同特征的“注意力”理应有所不同,而且“注意力得分” 的计算理应与广告特征有相关性。
DIN模型
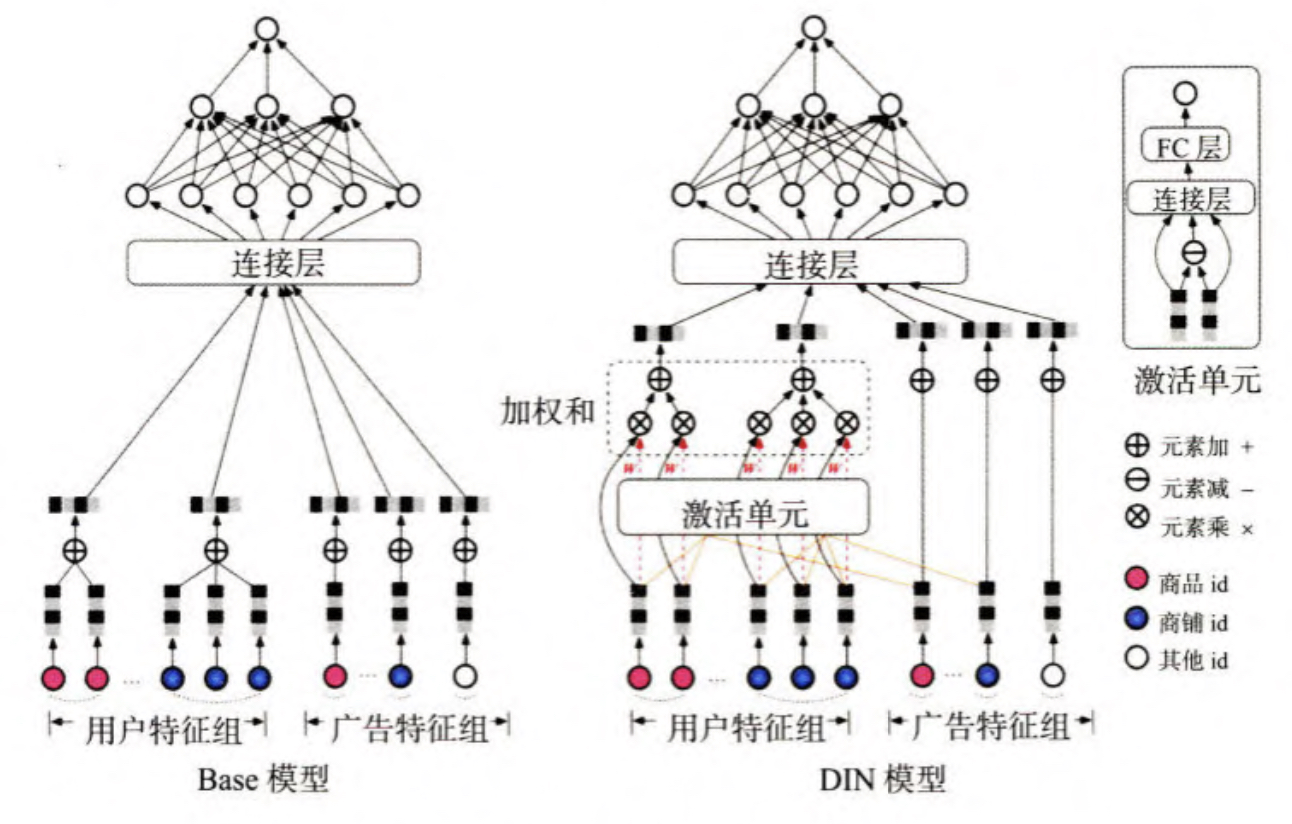
上图呈现了DIN模型和基础模型的一个本质不同,将上述“注意力”的思想反映到模型中也是直观的。利用候选商品和历史行为商品之间的相关性计算出一个权重,这个权重就代表了“注意力”的强弱,加 人了注意力权重的深度学习网络就是 DIN 模型。
Vu=f(V1)=i=1∑NwiVi=i=1∑Ng(Vi,Va)Vi(1.1)
Vu是用户的Embedding向量,Va是候选广告商品的Embedding向量,Vi是用户u第i次行为的Embedding向量,这里用户的行为就是浏览商品或店铺,因此行为的 Embedding 向量就是那次浏览的商品或店铺的 Embedding 向量。
加attention的方式也比较简单,Vu从过去的Vi的加和,变成了Vi的加权和,而权重wi与Vu和Va的关系决定,也就是1.1中的g(*),也就是注意力得分。
g(*)的讨论
下面一个问题是g(Vi,Va)函数到底采用什么形式比较好呢? 如上图所示,使用一个注意力激活单元(activation unit) 来生成注意力得分。这个注意力激活单元本质上也是一个小的神经网络,上图有展示。可以看出, 激活单元的输入层是两个 Embedding 向量,经过元素的”减法“操作,与原Embedding向量一同连接后形成全连接层的输人,最后通过单神经元输出层生成注意力得分。
注意上图的红线w部分,可以发现商铺 id 只跟用户历史行为中的商铺 id 序列发生作用,商品 id 只跟用户的商品 id 序列发生作用,因为注意力的轻重更 应该由同类信息的相关性决定。
减法的深思
这里不知道你是否有一个疑问,为啥在activation unit)做了一个减法的运算,其实这里咱们可以这样理解,对于神经网络而言,不管是加法还是减法都是对向量做了一个pooling。 向量的减法也是过滤向量相似度的一种方法, 比如两个物品向量相减之后,得到的结果很小,也能说明两个物品相似。