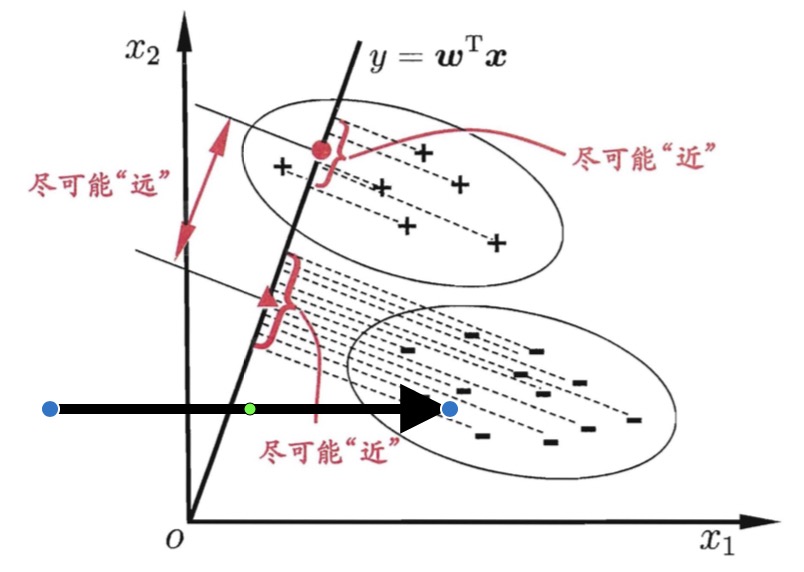
思考如下问题,如果有一个数据集合不是特别容易分类,这个可能是我们的数据维度并不能描述我们的数据本身,导致我们不能将数据完全切分开,如果能经过相应的变换,让我们的数据在某个变换以后变得显而易见,那是不是我们就解决了分类问题呢?本文就将介绍这这样的一个算法。就如下图所示。
LDA算法描述
现在我们用白话了解了一个问题,接下来我们需要用数学的语言将这个问题定义出来。这里想要提醒大家,学习一个问题,对于算法的同学,比较重要的是将这个问题的数学表达定义好,否则问题会变得格外的复杂和无从下手。大的思路还是要将原始数据x,通过权重矩阵w,转变成y且也具有比x更好的区分的性能。
y=wx
对于这个问题的输入数据是这样的,我们有n个样本数据,它们的特征向量是xi,属于不同的类别。其中属于类C1的样本集合为D1,且有n1个样本,属于C2的样本集合D2有n2个。对于每类样本的均值的定义为
m=n1x∈Di∑x
经过投影后的均值为
m=n1x∈Di∑wTx
投影后两类样本的均值绝对差为:
wT(m1−m2)
而对于类内的误差,我们使用方差来衡量,i表示第i类。
si2=∑(y−mi)2
这时候我们想要的损失函数是怎样的呢?我们肯定希望投影以后的数据,类内间距尽量小,类间的间距尽量大,所以不难定义我们的损失函数。
L(w)=s12+s22(m1−m2)2
我们发现这个损失函数竟然连w都没有,我们必需想尽办法写成关于w的函数,至于为什么呢?我们想求梯度,当然需要有优化的对象呀。
定义类内的散布函数如下
Si=∑(x−mi)(x−mi)T
总体的散布矩阵为
Sw=S1+S2
这样就有
si2=∑(wT−wTm)2
=∑wT(x−mi)(x−mi)Tw
=wTSiw
这样总体的个个类的散布之和为
s12+s22=wTSww
好了,从这里开始我们已经结束了分母的改写,接下来咱们就开始处理分子。
(m1−m2)2=(wT(m1−m2))2=wT(m1−m2)(m1−m2)Tw
如果定义SB=(m1−m2)(m1−m2),那么
(m1−m2)2=wTSBw
综合上面的描述,我们的最后的大公式终于出炉拉。
L(w)=wTSBwwTSWw
我们尝试加上一个约束条件
wTSWw=1
这问题又转化到了一个带有限制条件的最优化问题。
max wTSBw
st.wTSWw=1
L=wTSWw+λ(wTSww−1)
对w求导,能够得到
SBw+λSww=0
SBw=λSww
同时乘以Sw−1
Sw−1SBw=λw
发现了什么?
λ是Sw−1SBw的特征值,w是特征向量,将这个表达式放到目标函数中。
wTSBwwTSWw=wTSwwwT(λSWw)=λ
所以最大特征值
和其对应的特征向量就是本问题的最优解。
那么最后的问题来了,即使投射到一维空间,如何做分类呢? 其实我们可以把这个问题想简单点,例如KNN算法的方式也是可以接受的,就是用它的邻居来决定它的分类。