二阶优化
之前介绍的一阶的优化方法,能够找到迭代的方向,但是往往不能决定迭代的步长,本文介绍的牛顿相关方法能一定程度上解决这个问题。
牛顿法
首先我们来看看牛顿法的推导过程,
对于函数f(x)在xk处进行二阶泰勒展开。
f(x)=f(xk)+f′(xk)(x−xk)+21f′′(xk)(x−xk)2
前两阶求导等于0
f′(xk)+(x−xk)f′′(xk)=0xn+1=xn+f′′(xk)f′(xk)
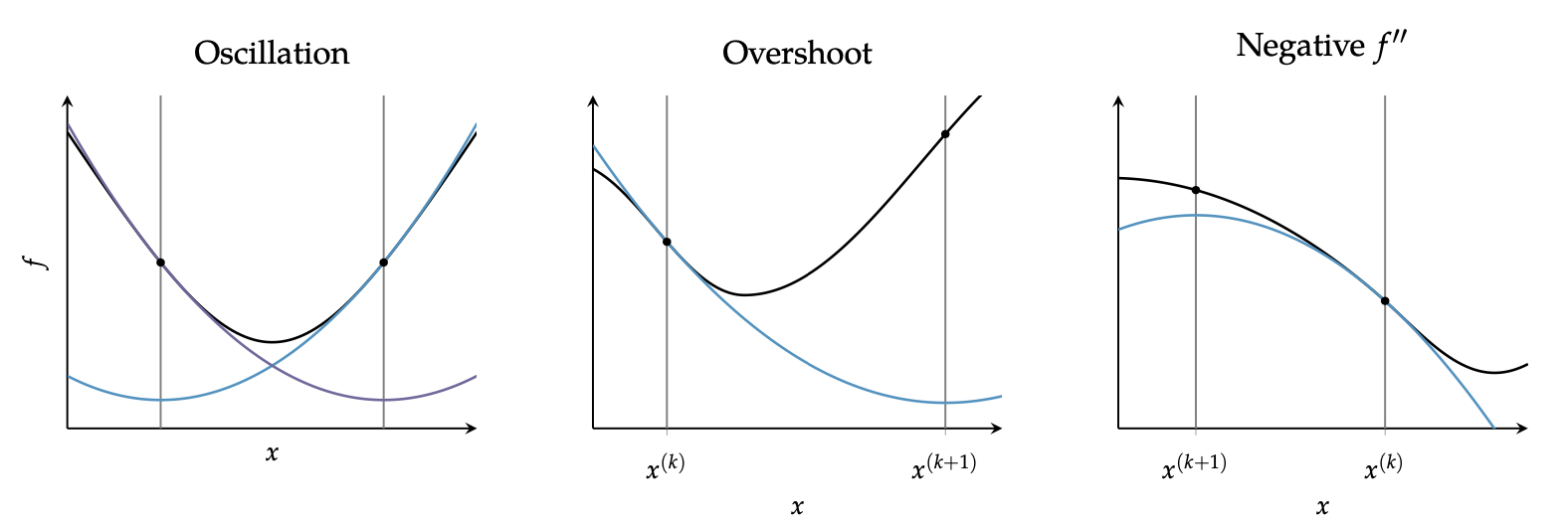
迭代过程如下图。
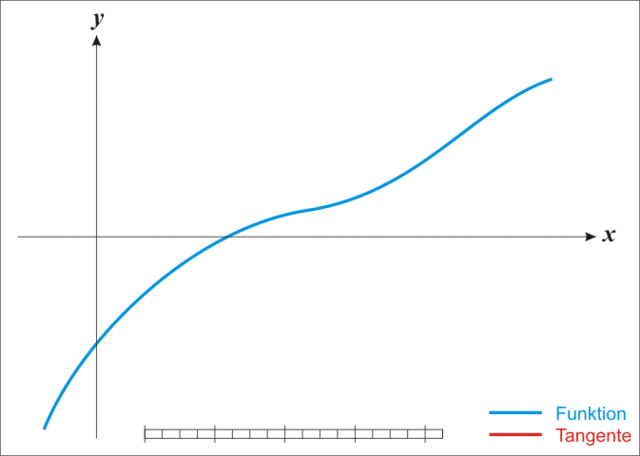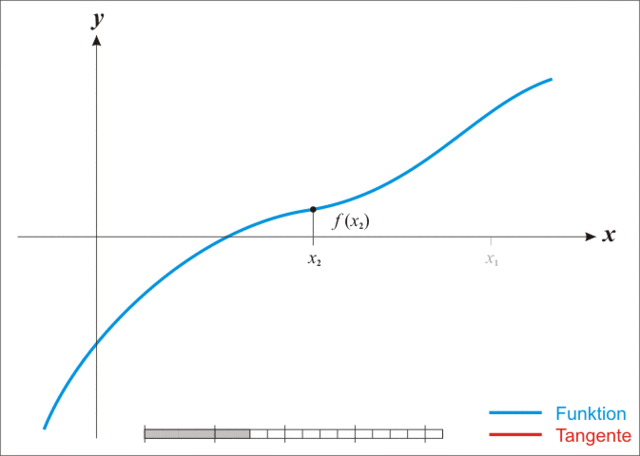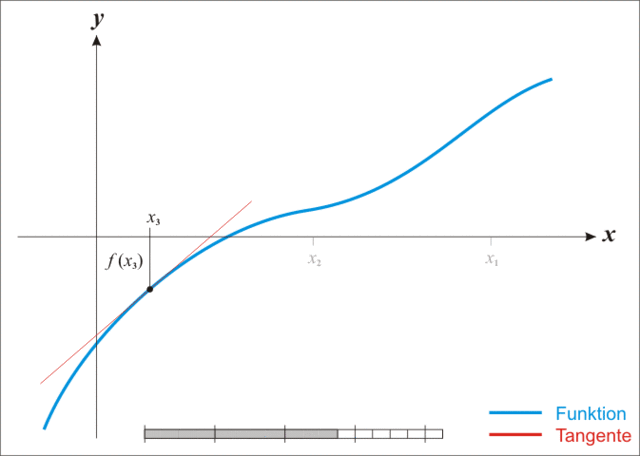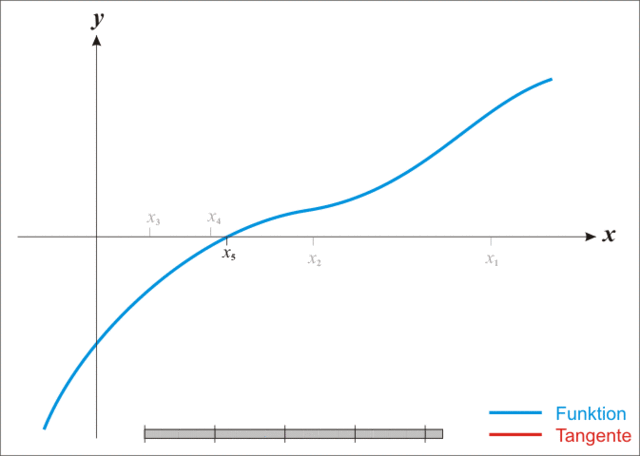
从上面的迭代过程能够看出,对于底部碗装的线性,其效果会十分的差。如前两种线性。
割线法
通过上面的讲解,我们知道牛顿法是要求有二阶导数的,但是并不是所有的函数都存在二阶导数, 割线法主要就是解决这个问题的。
f′′(xk)=xk−xk−1f′(xk)−f′′(xk−1)
这样就能解决没有二阶导数的函数的牛顿法的使用上。
拟牛顿法
拟牛顿法也是解决类似的问题, 但是在矩阵上近似黑塞矩阵,这里就不做进一步的讲解啦。
约束优化
接下来咱们来介绍约束优化,什么样的优化是约束优化呢? 其实就是咱们原有的优化函数上加上约束条件而已。
min f(x)s.t. h(x)=0
h(x)可以是等式也可以是不等式。 实际上就是在约束范围内找到最优解。
其方法也是尽可能的消除掉约束,从而变成一个正常的优化问题。
消除转换
例如下面这个问题。
min xsin(x)s.t. 2<x<6
可以通过如下的转换
x=t2,6(x)=22+6+26−21+x22x
通过上面的转换,原来的公式就变成了
min t2,6(x)sin(t2,6(x))min [4+2(1+x22x)]sin[4+2(1+x22x)]
这样就变成了一个无约束问题。
拉格朗日乘法
拉格朗日乘法主要是解决受限约束的函数是等式的情况下,如下公式。
min f(x)s.t. h(x)=0
利用拉格朗日乘法计算f的等高线与h(x)=0的等高线对齐的位置。由于函数在某个点的梯度垂直于该函数通过该店的等高线,我们知道h的梯度将垂直于等高线h(x)=0,因此需要找到f的梯度和h的梯度在哪里对齐。
∇f(x)=λ∇h(x)
其拉格朗日函数为
L(x,λ)=f(x)−λh(x)
举例
看下面这个例子。求解如下的公式
min −exp(−(x1x2−23)2−(x2−23)2)s.t. x1−x22=0
使用拉格朗日法
L(x1,x2,λ)=−exp(−(x1x2−23)2−(x2−23)2)−λ(x1−x22)∂x1∂L=2x2f(x)(23−x1x2)−λ∂x2∂L=2λx2+f(x)(−2x1(x1x2−23)−2(x2−23))∂λ∂L=x22−x1
分别令上面的导数为0,就能求出相应的x
惩罚方法
通过向目标函数增加惩罚项,可以使用惩罚方法将约束问题转化为非约束问题。
min f(x)s.t.f(x)<0h(x)=0
一种简单的惩罚方法是计算违反的约束方程数量
Pcount(x)=∑gi(x)>0+∑(hi(x)=0)
那么新的方程就是
min f(x)+aPcount(x)
a是乘法幅度。 惩罚方法从初始点x和一个很小的a开始,求解无约束优化方程。然后得到一个点作为另一个优化的起点,并增加惩罚,直到得到可行结果,或者达到了最大迭代次数。