Seq2Seq模型
对于一些自然语言处理任务,比如聊天机器人,机器翻译,自动文摘等,传统的方法都是从候选集中选出答案,这对素材的完善程度要求很高,随着最近几年深度学习的兴起,国外学者将深度学习技术应用与自然语言的生成和自然语言的理解的方面的研究,并取得了一些突破性的成果,比如,Sequence-to-sequence (seq2seq) 模型,它是目前自然语言处理技术中非常重要而且非常流行的一个模型,该技术突破了传统的固定大小输入问题框架,开通了将经典深度神经网络模型运用于翻译与职能问答这一类序列型任务的先河,并且被证实在各主流语言之间的相互翻译以及语音助手中人机短问快答的应用中有着非常好的表现,下面小修给大家简要介绍一下关于seq2seq模型的一些细节。

上图就是Seq2Seq模型一个简单结构,输入一句话,给出这句话的翻译,也是机器翻译的常见场景,左边蓝色的框框就是Encoder模块,这个模块一般用RNN或是LSTM的单元填充,但是输出目标还是一致向量,然后decoder也是起到解码的作用来拟合标签,如果大家想了解细节,可以看看本站RNN拆解,然后结合代码了解seq2seq的网络训练过程和传播过程。
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
PAD = 0
EOS = 1
vocab_size = 10
input_embedding_size = 20
encoder_hidden_units = 20
decoder_hidden_units = 20
batch_size = 100
def random_sequences(length_from, length_to, vocab_lower, vocab_upper, batch_size):
def random_length():
if length_from == length_to:
return length_from
return np.random.randint(length_from, length_to + 1)
while True:
yield [
np.random.randint(low=vocab_lower, high=vocab_upper, size=random_length()).tolist()
for _ in range(batch_size)
]
batches = random_sequences(length_from=3, length_to=10,
vocab_lower=2, vocab_upper=10,
batch_size=batch_size)
def make_batch(inputs, max_sequence_length=None):
sequence_lengths = [len(seq) for seq in inputs]
batch_size = len(inputs)
if max_sequence_length is None:
max_sequence_length = max(sequence_lengths)
inputs_batch_major = np.zeros(shape=[batch_size, max_sequence_length], dtype=np.int32)
for i, seq in enumerate(inputs):
for j, element in enumerate(seq):
inputs_batch_major[i, j] = element
inputs_time_major = inputs_batch_major.swapaxes(0, 1)
return inputs_time_major, sequence_lengths
train_graph = tf.Graph()
with train_graph.as_default():
encoder_inputs = tf.placeholder(shape=(None, None), dtype=tf.int32, name='encoder_inputs')
decoder_inputs = tf.placeholder(shape=(None, None), dtype=tf.int32, name='decoder_inputs')
decoder_targets = tf.placeholder(shape=(None, None), dtype=tf.int32, name='decoder_targets')
embeddings = tf.Variable(tf.random_uniform([vocab_size, input_embedding_size], -1.0, 1.0), dtype=tf.float32)
encoder_inputs_embedded = tf.nn.embedding_lookup(embeddings, encoder_inputs)
decoder_inputs_embedded = tf.nn.embedding_lookup(embeddings, decoder_inputs)
encoder_cell = tf.contrib.rnn.LSTMCell(encoder_hidden_units)
encoder_outputs, encoder_final_state = tf.nn.dynamic_rnn(
encoder_cell, encoder_inputs_embedded,
dtype=tf.float32, time_major=True,
)
decoder_cell = tf.contrib.rnn.LSTMCell(decoder_hidden_units)
decoder_outputs, decoder_final_state = tf.nn.dynamic_rnn(
decoder_cell, decoder_inputs_embedded,
initial_state=encoder_final_state,
dtype=tf.float32, time_major=True, scope="plain_decoder",
)
decoder_logits = tf.contrib.layers.linear(decoder_outputs, vocab_size)
decoder_prediction = tf.argmax(decoder_logits, 2)
stepwise_cross_entropy = tf.nn.softmax_cross_entropy_with_logits(
labels=tf.one_hot(decoder_targets, depth=vocab_size, dtype=tf.float32),
logits=decoder_logits,
)
loss = tf.reduce_mean(stepwise_cross_entropy)
train_op = tf.train.AdamOptimizer().minimize(loss)
loss_track = []
epochs = 3001
with tf.Session(graph=train_graph) as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(epochs):
batch = next(batches)
encoder_inputs_, _ = make_batch(batch)
decoder_targets_, _ = make_batch([(sequence) + [EOS] for sequence in batch])
decoder_inputs_, _ = make_batch([[EOS] + (sequence) for sequence in batch])
feed_dict = {encoder_inputs: encoder_inputs_, decoder_inputs: decoder_inputs_,
decoder_targets: decoder_targets_,
}
_, l = sess.run([train_op, loss], feed_dict)
loss_track.append(l)
if epoch == 0 or epoch % 1000 == 0:
print('loss: {}'.format(sess.run(loss, feed_dict)))
predict_ = sess.run(decoder_prediction, feed_dict)
for i, (inp, pred) in enumerate(zip(feed_dict[encoder_inputs].T, predict_.T)):
print('input > {}'.format(inp))
print('predicted > {}'.format(pred))
if i >= 20:
break
plt.plot(loss_track)
plt.show()
可能需要讲解的是embedding_lookup,这个函数的作用,这个函数是按照encoder_inputs的id进行embedding,这样我们的词向量就能对应的上。
整个模型和第一部分介绍的类似,整个模型分为解码和编码的过程,编码的过程结束后输出一个语义向量c,之后整个解码过程根据c进行相应的学习输出。
j解码过程是隐含层在t时刻的更新根据如下方程进行更新。
ht=f(ht−1,yt−1,c)(1.1)
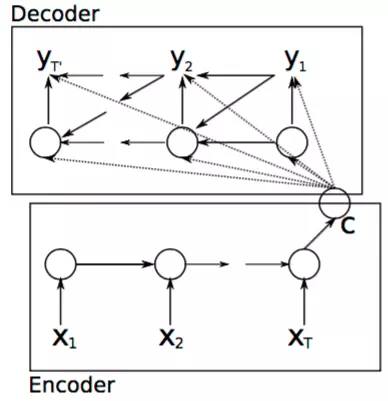
除了新加了c变量以外,其它和RNN原本的函数关系是一样的。类似的条件概率公式可以写为:
P(yt∣yt−1,yt−2,...,y1,c)=g(ht,yt−1,c)(1.2)
对于整个输入编码和解码的过程中,文行中使用梯度优化算法以及最大似然条件概率为损失函数去进行模型的训练和优化:
maxN1n=1∑Nlogpθ(yn∣xn)(1.3)
其中θ为相应模型中的参数,(xn,yn)是相应的输入和输出的序列。
按照这样的方式我们能够解决很多问题,但是seq2seq仍然存在极大的缺点,就是编码和解码依赖一个向量C,对于长句来说会丢失很多信息,即使使用LSTM也是一样的问题,它会有一个最大的记忆极限,后续我们会讲解seq2seq加入Attention的机制,来解决我们这个问题。
温馨提示
上文的代码中没有给出,不过这里还是强调下,当预测的y的时候, y1的预测值经常当成y2预测的输入, 因为y的拟合是需要一个过程的, 所以为了加快效率,会将y1的真值作为y2的输入,这样能够加快训练的速度。