本节要详细介绍一些Transformer这个常用的神经网络组件,会举一些十分详细的例子,目的是将这个网络结构讲清楚。
Transformer结构是主要是编码器和解码器组成,Transformer其实是经典的LSTM循环的结构,并使用了一种自注意力的机制。这里我们举一个机器翻译的例子,来讲解整个过程。
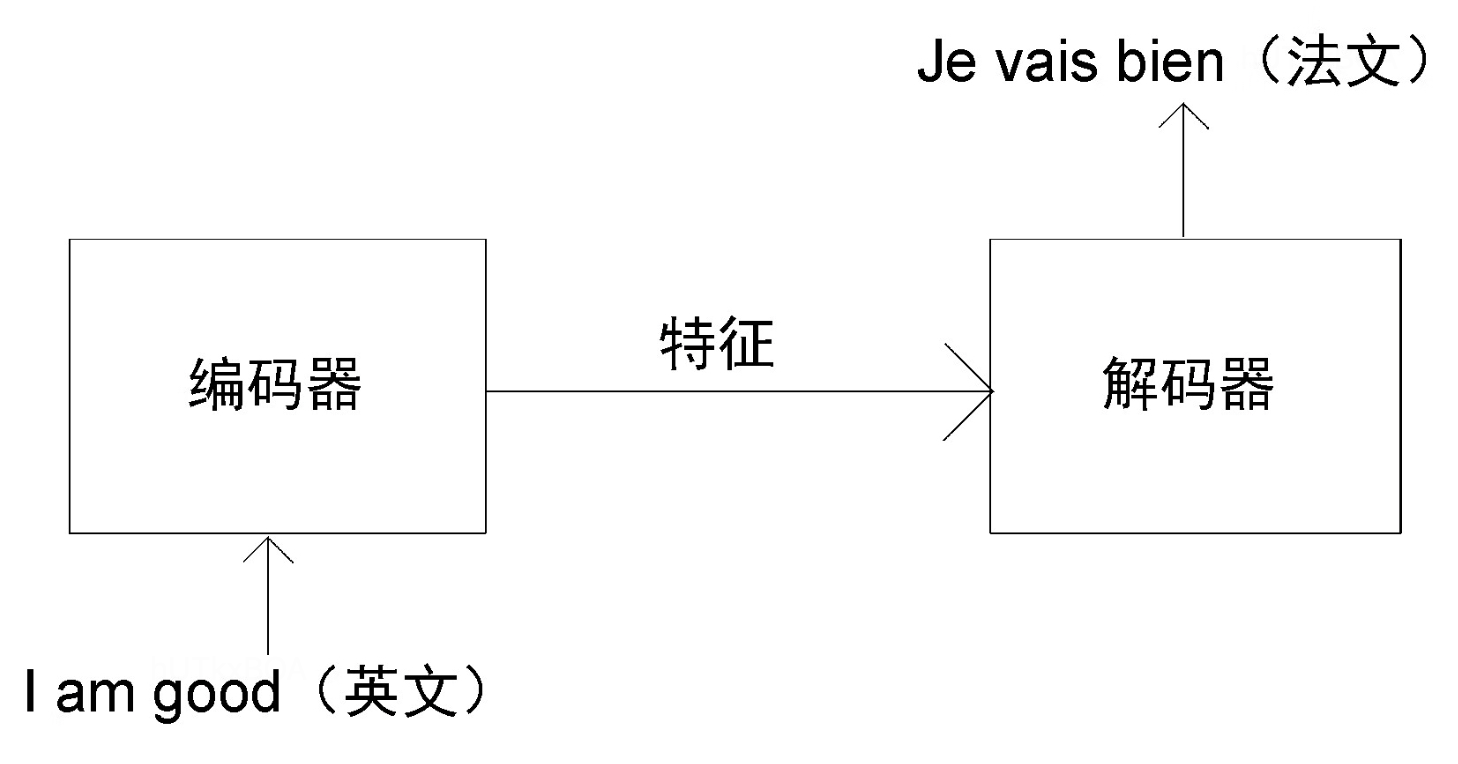
编码器
编码器的主要作用是从输入的语句中尽可能多的提取特征,其结构如图2-1.
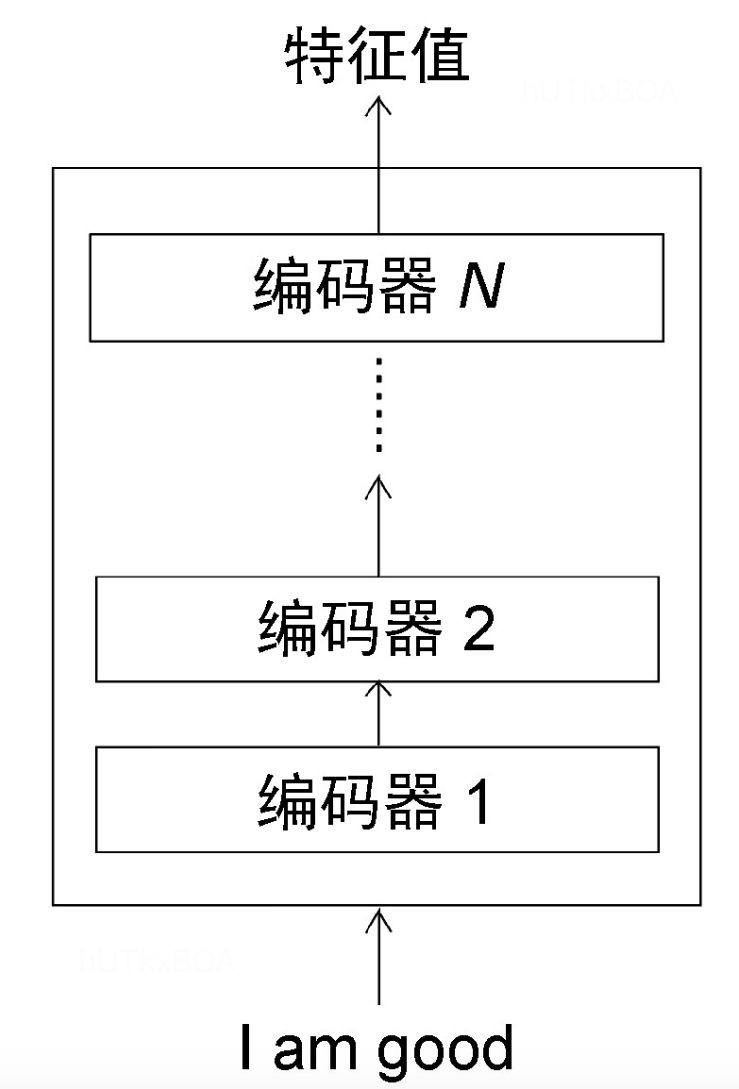
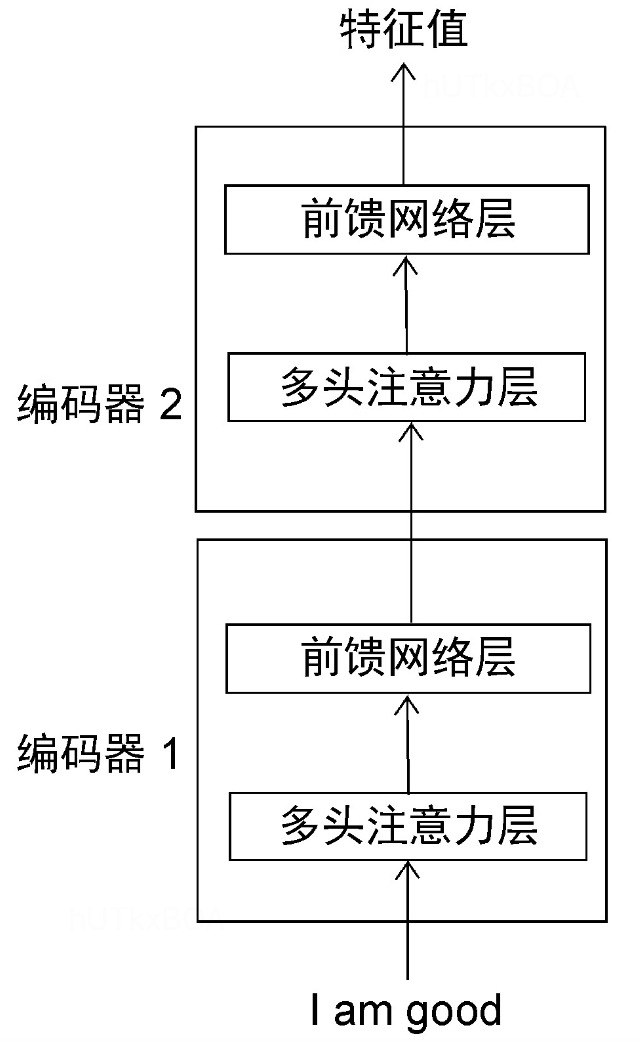
一般会有N个编码器,且前一个编码器的输出会作为第二个编码器的输入。编码器的内部结构如图2-2.
自注意力矩阵
了解了编码器的结构以后,我们来看看自注意是怎么回事。
A dog ate the food, because it was hungry
当我们想要了解it指代的是dog还是food时候,就需要将it与前面所有的单词构建一个联系,从而推导出it指代的是dog。那么接下来咱们来具体看自注意机制的计算的详细过程。
输入嵌入矩阵
这一步可以通过一些word2vec等方法将词转化为一个向量,并使用向量进行计算,接下来我们给出一个demo。

接下来会有三个矩阵,WQ,WK,WV ,分别表示查询矩阵权重、键矩阵权重、和值矩阵权重。
通过输入的矩阵X,可以分别获得查询矩阵、键矩阵和值矩阵。
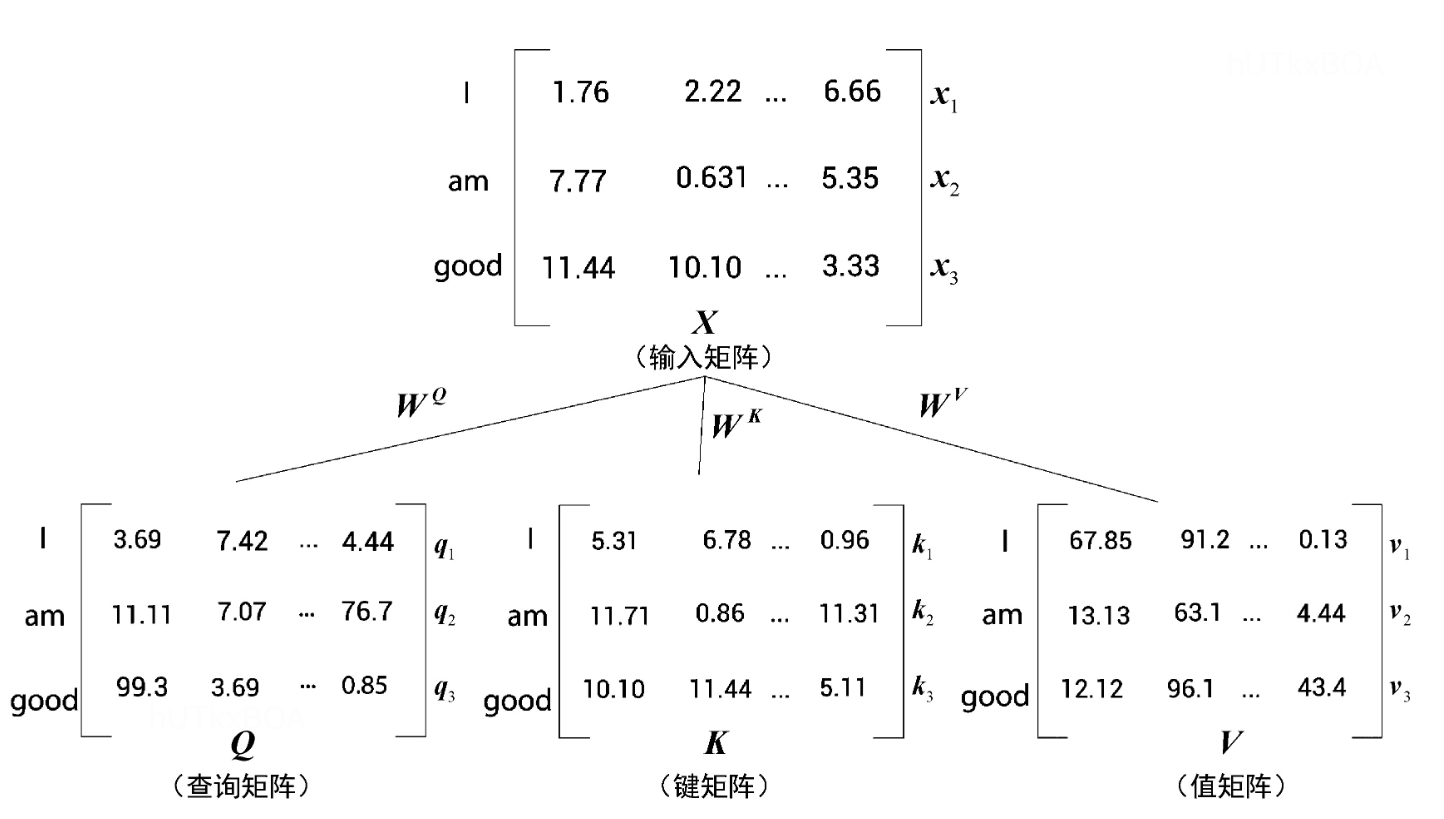
图2-4中q1,k1,v1分别表示查询向量、键向量和值向量。
我们想计算自注意矩阵,需要将每个单词与句子中的单词都要计算一下相似度,那么这个过程是如何计算的呢?
第一步是计算查询矩阵和键矩阵的点积,如图2-5.

其实这个过程就是在计算单词与其他单词的相关性,这个矩阵是有一定的物理含义的。
QK˙T中第一行【110, 90, 80】就表示的是I这个单词和自己是更相关的。
第二步骤是将QK˙T除以向量维度的平方根,如果是64维,那么就是除以8.如图2-6.
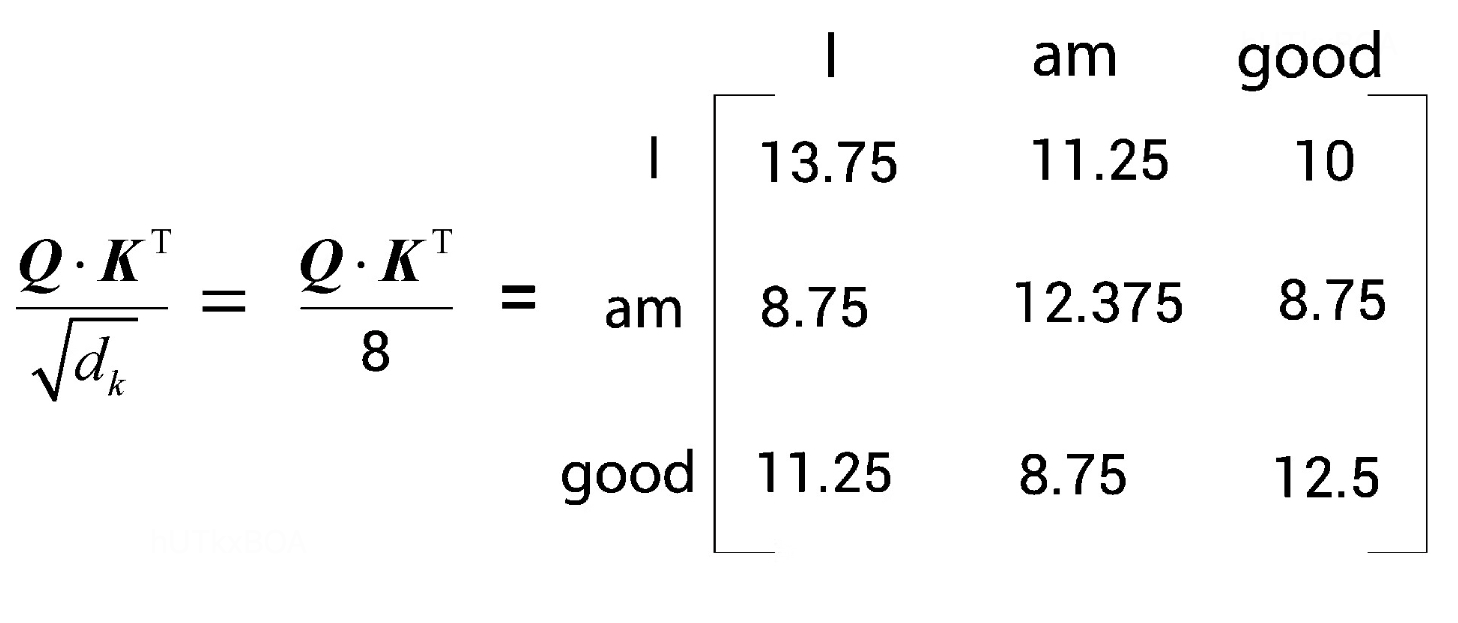
这样做的目的是为了获得稳定的梯度。这里主要还控制点积的大小,从而控制了softmax函数的输出范围,使得其更加稳定。
第三步就是简单的softmax归一化过程。如图2-7
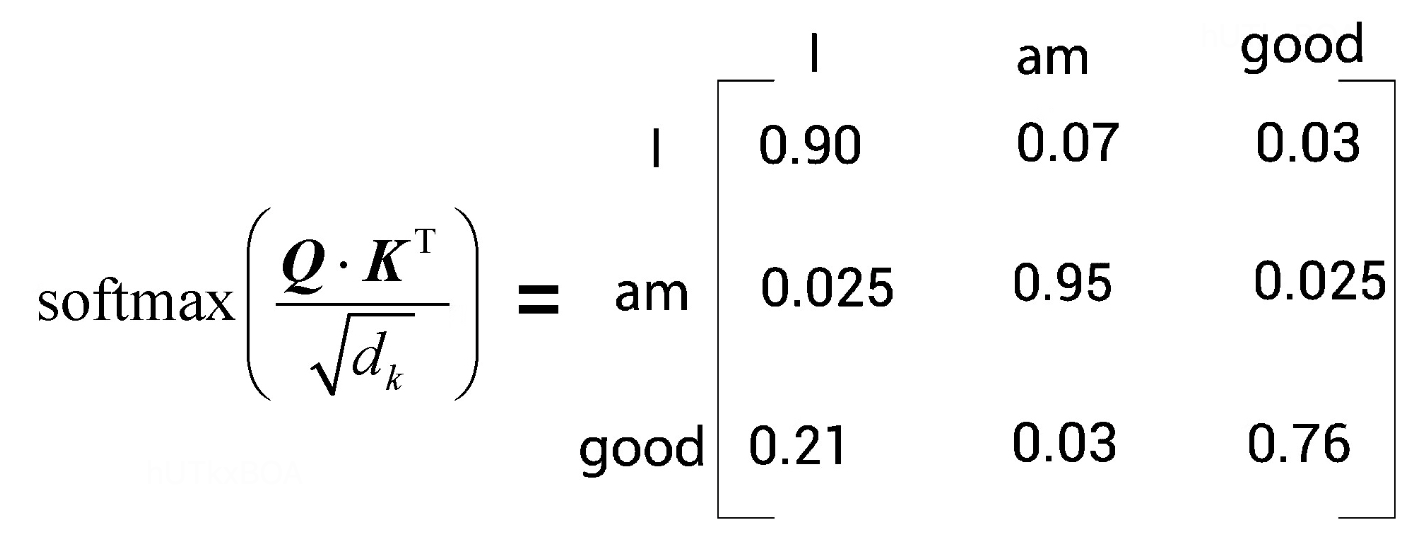
最后一步我们就要计算自注意力矩阵Z啦。

发现没有,之前归一化的结果实际上是对值矩阵的加权求和的权重。这样就获得了最终的自注意力矩阵。这里进一步总结K、Q、V的作用。
Transform的核心思想是根据查询(Q)和键(K)之间的相似度来计算注意力权重。查询(Q)用于表示你想要关注的位置或元素,而键(K)用于表示输入序列中的位置或元素。通过计算 Q 和 K 之间的相似度,可以为每个查询分配不同的权重,以便在编码过程中关注不同位置的信息。这个时候再与V矩阵相乘,就得到了对V矩阵中不同的元素的关注度是不一样的。
这里可以再给一下刚刚举的小例子。

这里it与前面的dag的权重是最大的,权重是1.0,这样就更加有助于我们理解整句话的含义。
位置信息
我们知道在自然语言处理的领域,词语与词语之间的顺序是异常重要的,那么上面介绍的计算过程中没有提到单词的顺序呀,接下来补充这一部分的信息。
这里的输入是原始的矩阵X,我们需要将位置信息融入到X中,之前的文章介绍过使用正余弦公式来表示位置编码。
\begin{equation}
PosEnc(pos,i)=\left\{
\begin{aligned}
sin(\frac{pos}{10000^{i/d}}) \ \ i为偶数 \\
cos(\frac{pos}{10000^{(i-1)/d}}) \ \ i为奇数 \\
\end{aligned}
\right.
\end{equation}
这里的pos表示位置,i表示坐标信息,d表示模型接受的最大长度
位置编码矩阵就如下图所示
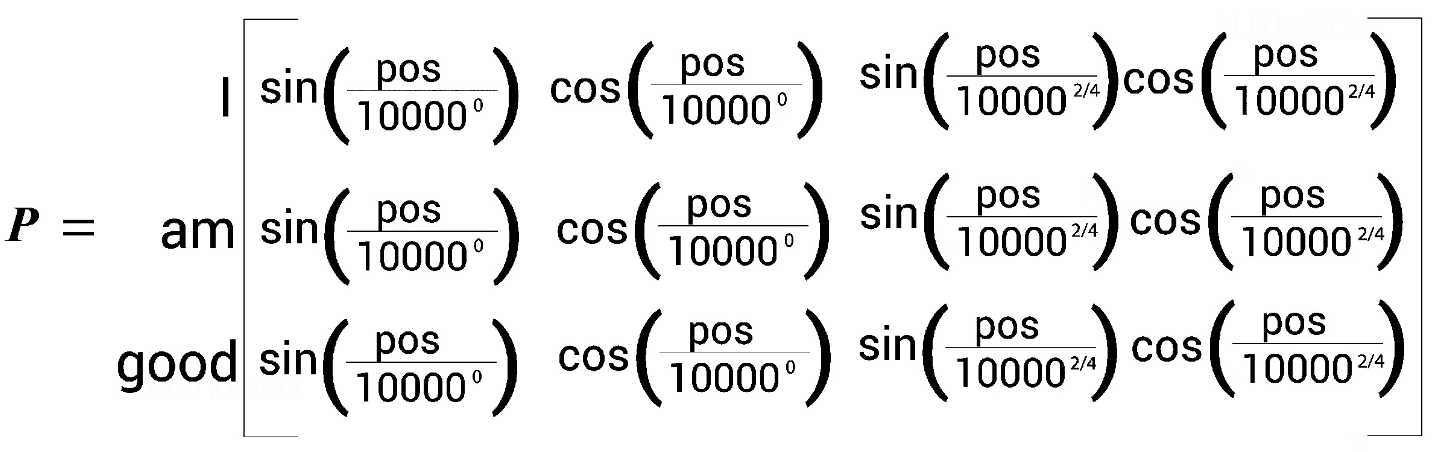
计算位置矩阵P后直接使用到输入矩阵X中,作为整个模型的原始输入。
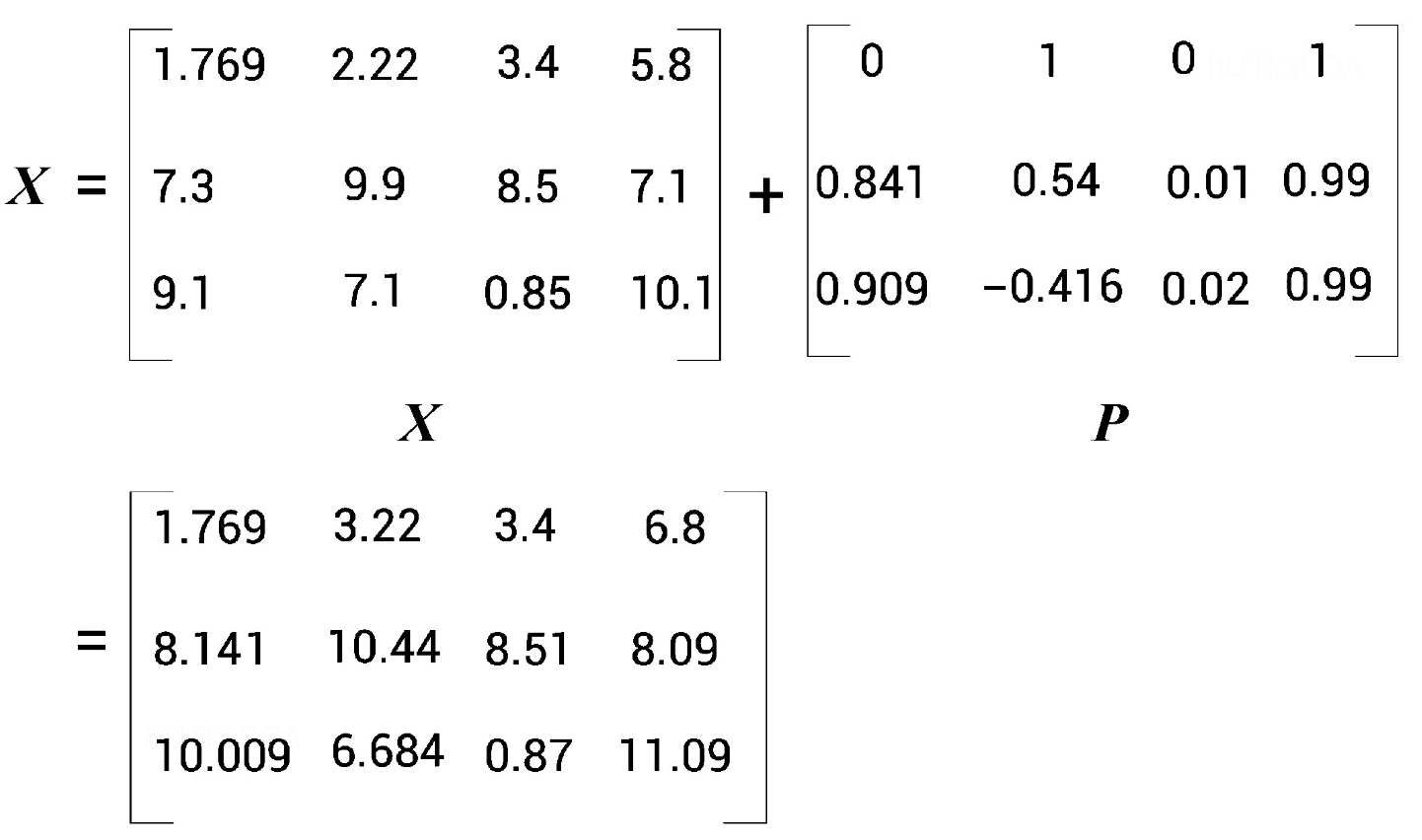
到这里,这个自注意矩阵的来龙去脉就讲的比较清楚啦。
解码器
解码器和编码器的输入不太一样,可以看图3-1, 解码器的输入不仅仅包含了原始特征的输入,还包含了编码器的原始输出。第一个解码的前一个解码的输入默认是<sos>标记。
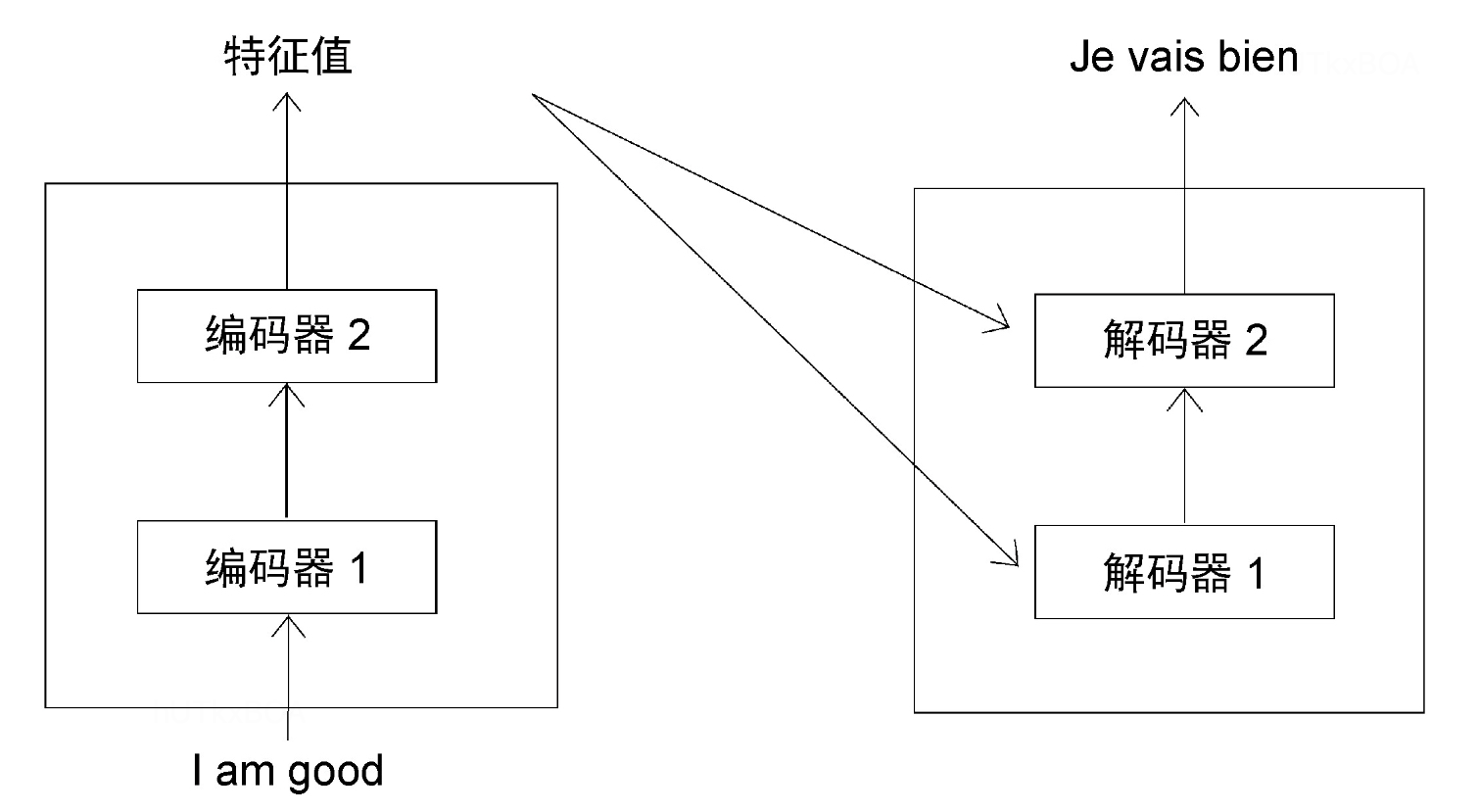
先来看看解码器的结构。

首先我们来看看解码器是如何工作的,当刚刚开始的时候,解码器输入包括编码器的输入和<sos>的编码,这个时候期望的预测值是Je。 当t=2的时候,解码器的输入就是<sos> Je,期望预测的是vails。
带掩码的注意力层
开始咱们就需要看看这个带掩码的注意力层是干嘛的。训练数据如下
训练数据
I am good
标签
Je vails bien
这里需要注意一点,虽然我们是将整个语句传给了模型,但是实际上解码器每次输入的时候,仅仅有目标词之前的词计算Q、K、V。 后面的词会以掩码的形式进入模型。

对应于向量就是指定的位置上用负无穷这类标记。如图3-4
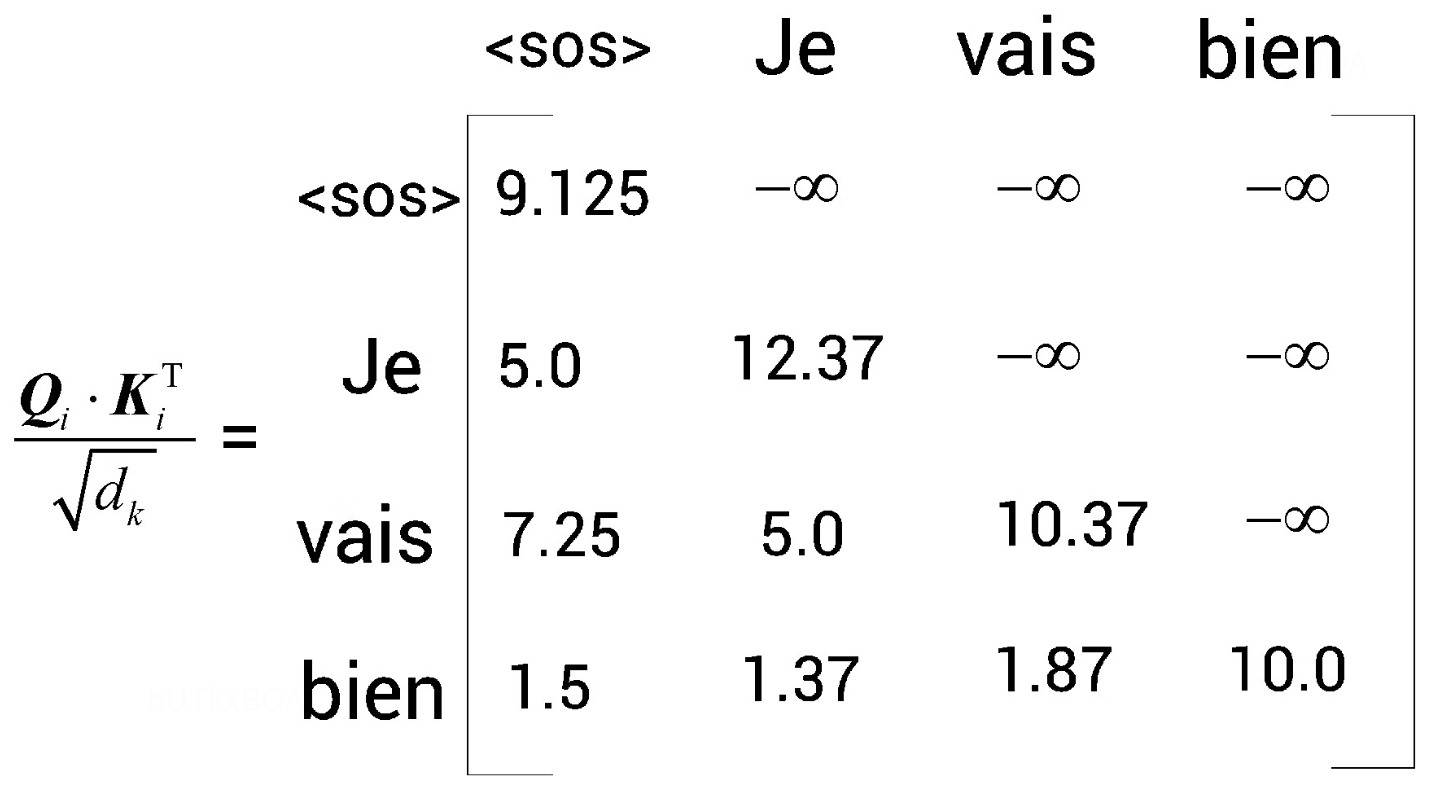
下图给出一个完整的编解码过程。
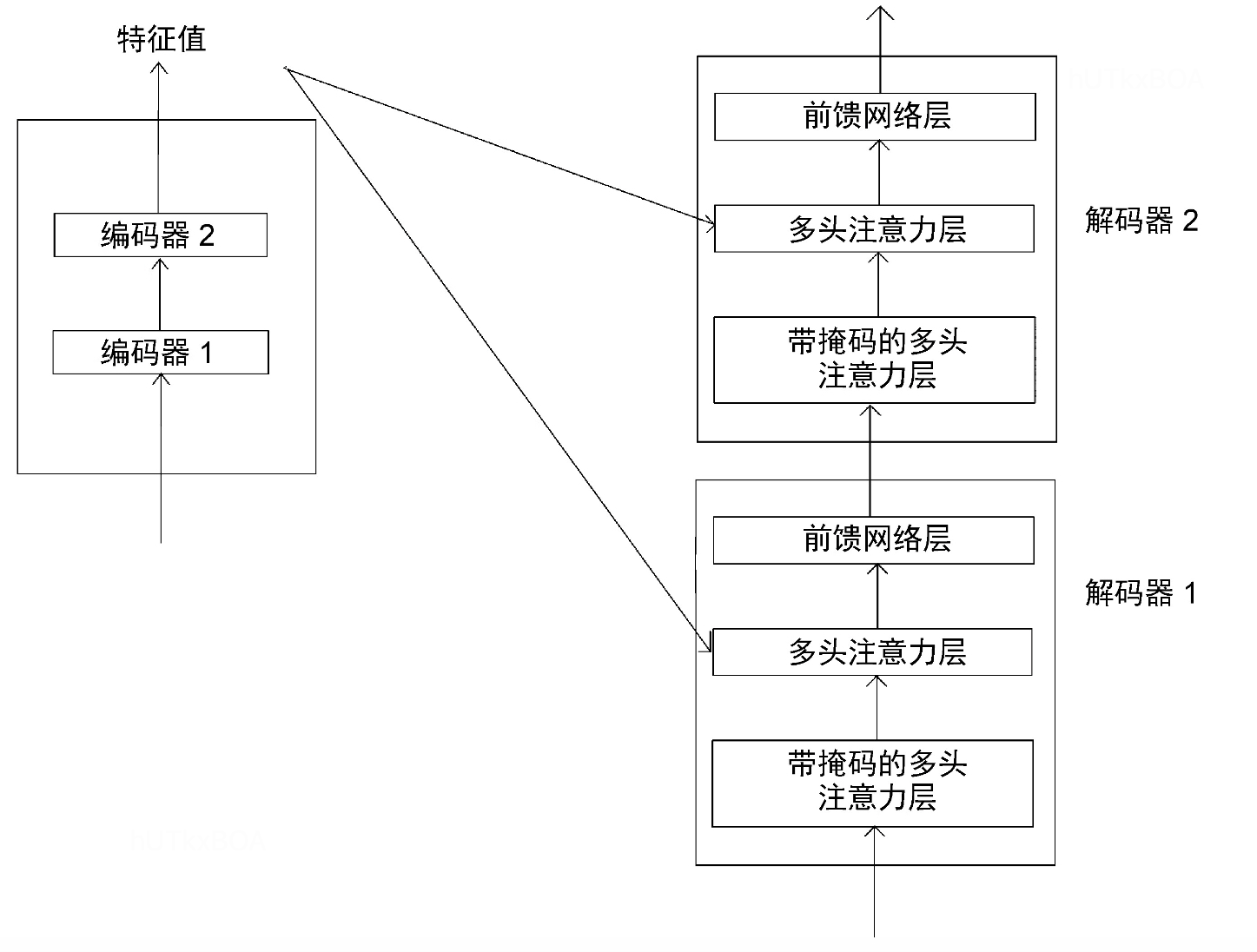
前馈神经网络
这部分就比较简单,就是特征抽取后进入到神经网络进行变换就可以啦。
损失函数的选择
通过上面的介绍,基本上就把整个网络的学习和计算过程讲的比较清楚,这里就是提示一下,对于损失函数的选择,因为解码器经常是预测词汇的分布,所以一般会选择交叉熵损失函数。