Word2vec
将文本转化成向量是nlp中一个比较重要的任务,也是链接nlp和机器学习和深度学习的桥梁,单纯的中文文字,我们是无法直接放到模型中训练的,所以将文本转化为一个向量是我们必须要过的一关。
词袋模型(bag of word)
词袋模型的思路十分简单,是文本向量化的最简单方法。我们直接举一个例子来了解这个模型的方法。
- John likes to watch movie, Mary likes, too.
- John also likes to watch football games.
按照上面的句子中的单词顺序,我们给出一个词表。
{
"John":1,
"likes":2,
"to":3,
"watch":4,
"movie":5,
"Mary":6,
"too":7,
"also":8,
"football":9,
"games":10
}
然后我们根据这个顺序给上面的一句话编码,对应的值就是某个单词在这句话里的出现次数。对于第一句话来说就如下:
[1,2,1,1,1,0,0,0,1,1]
现在这个向量和原有的单词的出现词序无关,仅仅与频率有关。这种编码方式十分简单,那么我们看看有什么缺点;
- 维度灾难,很好理解,我们单词越多,这个向量越长,可能大部分都是0
- 无法保留词序信息
- 存在语义鸿沟的问题。
NNLM
对于上文中的一些缺点,研究人员就发现了一种可以通过深度学习的方式解决词向量编码的方法,
NNLM是一个语言模型,训练的数据主要是所有的语料数据,模型的结果如图。它所依赖的原理是构建一个概率分布。
P(w1,w2,..,wn)=P(w1)P(w2∣w1)...P(wn∣w1,...,wn)(1.1)
P(w1,w2,..,wn)表示w1,w2,..,wn同时出现的联合概率,也就是一句话的表达方法的枚举,而公式(1.1)就恶心了,每次都要计算一个条件概率,计算量会非常大,所以我们需要使用深度学习来拟合一个概率。这里我们假设ABC三个单词后面跟着单词D概率是最大的,所以这就变成了一个监督的学习问题,也是N-gram思想的一个体现。
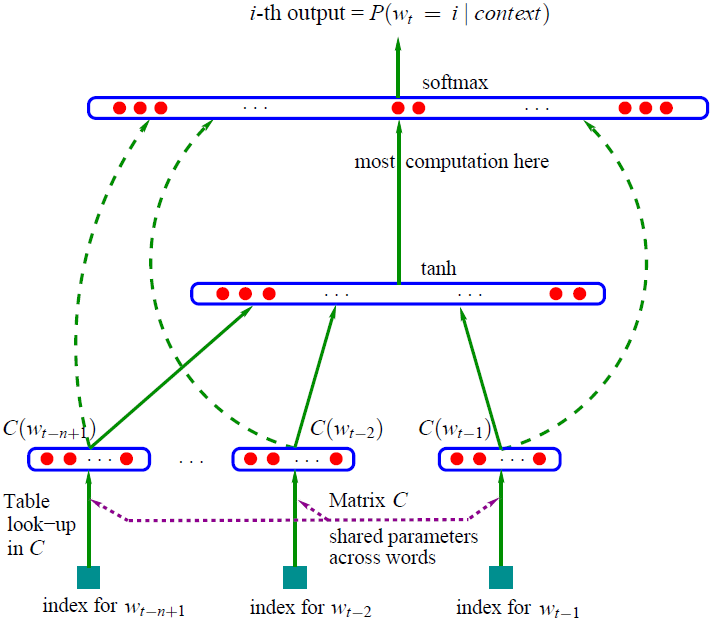
-
对于语料中的数据,从语料库中滑动4个数据,将其中前三个词转为one-hot编码形式,将三个one-hot形式作为输入喂入网络,第四个数据就是label。这里假设我们的词典集合长度是1w,所以one-hot的长度也是1w。
-
前向传播中,我们会将三个向量分别乘以一个[1w,100]的向量也就是图中的矩阵C(假设我们的目标泛化维度是300).
-
经过上一层的相乘以后就变成3个100维度的向量相连然后变成一个300维的向量,然后进行tanh激活一次
-
最后构建softmax拟合输出。
而上面描述的300维的向量就是我们要的词向量。
例如我们有数据
- 有狗在屋里乱跑
- 有狗在屋里乱走
经过训练以后我们会发现,跑和走的词向量近似度很大,这就就是构建了语义上的距离,从而构建一个低维度的词向量。
损失函数
L=i−(n−1)i∈D∑logP(wi∣wi−(n−1),..,wi−1)(1.2)
很好理解,最大化下一个词的wi的概率。
CBOW模型
NNLM是构建一个语言模型,根据原文中后一个词的出现概率,来推知词向量的表示方式,而C&W模型是直接生成词向量的模型。在NNLM中我们的输入是几个词的词向量,从上面那个例子我们也能知道,上来就是一个8w维度的向量,本文介绍的是CBOW模型会一定程度上减少模型的参数。CBOW选取的是语料库中中间一个词语作为目标词,也就是标签。
因为CBOW的输入和标签的设定,决定了CBOW对高频词的表示性能更加优越。
首先,CBOW模型相比NNLM去掉了隐藏层。
其次,CBOW模型使用上下文信息的的词向量的平均,而不是每个词向量都拼接输入到模型,大量减少了参数
模型结构如图:
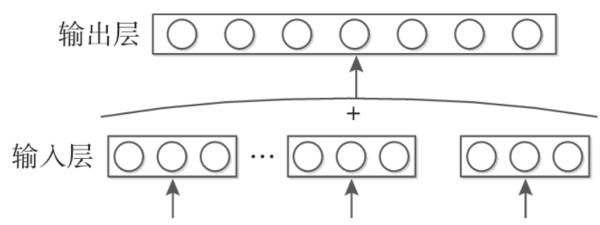
CBOW使用的损失函数和NNLM损失函数一致,训练的标注方式都是一致的,所以也很好理解。
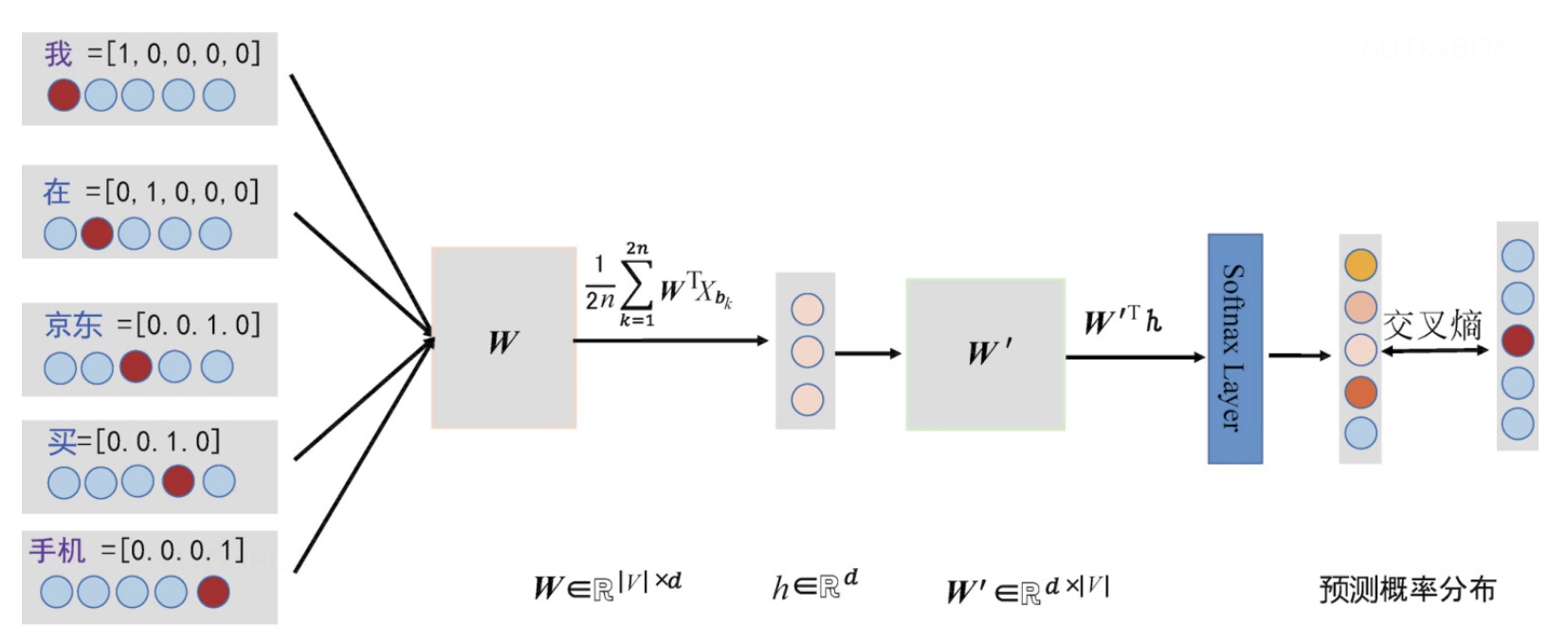
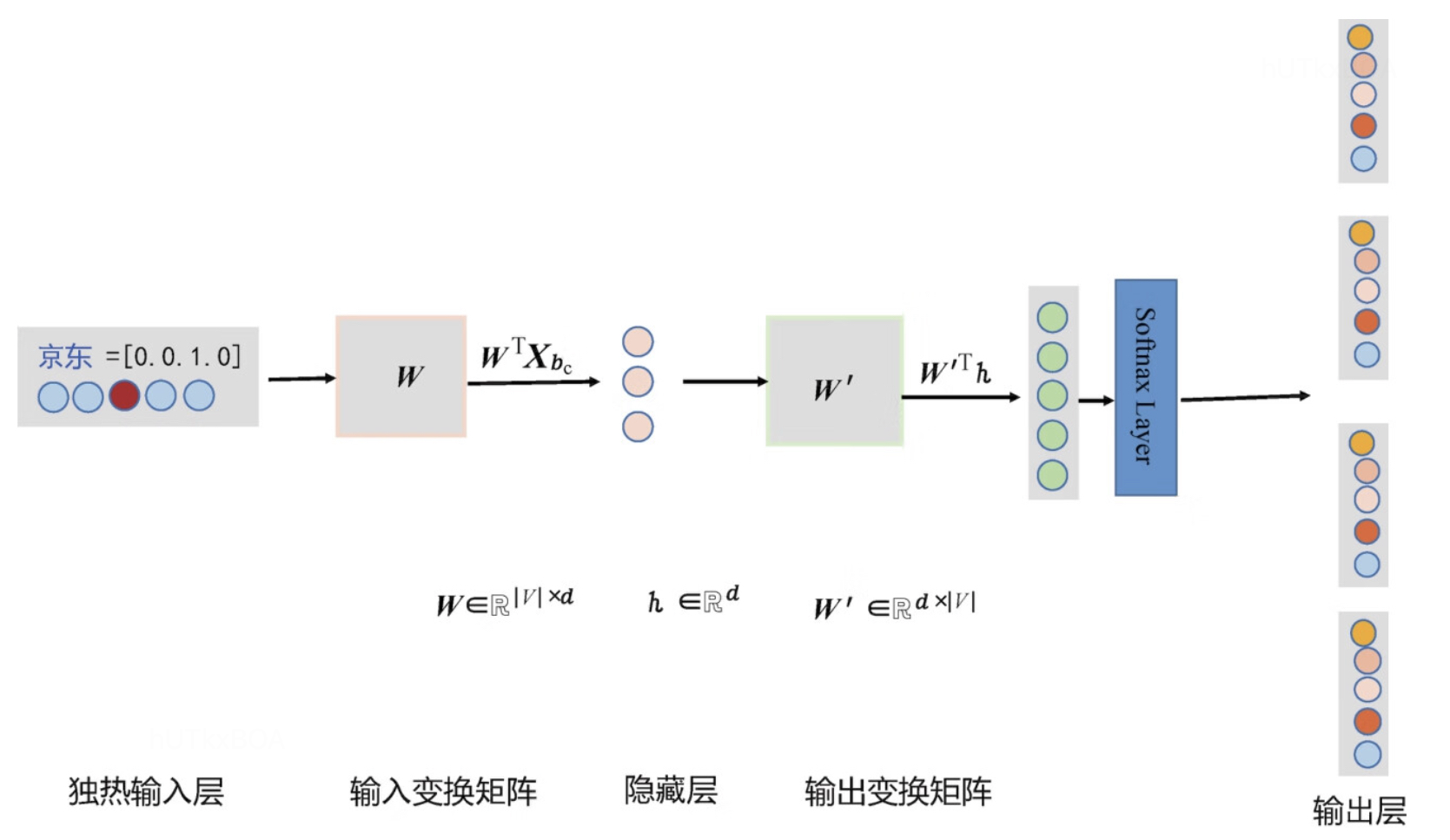
Skip-gram模型
Skip-gram模型和CBOW模型几乎一致,唯一有一点不同是,在输入数据的选取中,Skip-gram是从目标词上下文选一个词向量标识作为输入,而目标词反而变成了标注的y。Skip-gram对稀有词的表示性能更加优越。
这里我们可以对比这两种学习方法
在skip-gram里面,每个词在作为中心词的时候,实际上是 1个学生 VS K个老师,K个老师(周围词)都会对学生(中心词)进行“专业”的训练,这样学生(中心词)的“能力”(向量结果)相对就会扎实(准确)一些,但是这样肯定会使用更长的时间;
cbow是 1个老师 VS K个学生,K个学生(周围词)都会从老师(中心词)那里学习知识,但是老师(中心词)是一视同仁的,教给大家的一样的知识。至于你学到了多少,还要看下一轮(假如还在窗口内),或者以后的某一轮,你还有机会加入老师的课堂当中(再次出现作为周围词),跟着大家一起学习,然后进步一点。因此相对skip-gram,你的业务能力肯定没有人家强,但是对于整个训练营(训练过程)来说,这样肯定效率高,速度更快。
word2vec 优化
通过上面模型的介绍,我们能够理解其实word2vec是一个参数巨大的神经网络,同样也有一些策略能够优化这个训练过程。
- 将常见的词块放到一起表示和训练。
- 对高频词进行采样,减少训练样本。
- 对优化目标采用负采样的策略。也就是每个训练样本训练的时候,只对少部分参数更新
下面就来一一介绍这些策略。
高频词采样
word2vec采用窗口式的训练样本采集,例如英文中的The a词无法为上下文提供重要的语义信息,需要做特殊的处理,但是这样的词往往又是高频的词汇,所以操作是在原始的训练文本中的每个单词,都存在被删除的概率,而这个被删除的概率与词频是有关系的。某一个单词被删除的概率为
P(wi)=1−(0.001z(wi)+1)z(wi)0.001
其中z(wi)表示词频。这样就一定程度上解决了训练的问题。
负采样
训练一个神经网络往往需要不断的调整神经网络的参数,进而提升性能。这是一个十分耗费计算资源的工作。负采样的做法是不同与每个训练样本都需要更新所有的权重,负采样每次需要更新一个训练样本的一小部分权重,就能大幅降低梯度下降的计算量。
对于具有1000维度的编码, 我们期望输出词的对应位为1,其余999位为0,使用负采样 的时候,将随机选择一小部分负单词来更新权重,同时正单词也会更新权重。这样就减少了权重更新的范围。负单词的选择为
P(wi)=∑j=0nf(wi)0.75f(wi)0.75
其中f(wi)表示词频。
其他Word2vec方法
此外还有通过矩阵分解的方式进行Word2vec的计算,这里也不再过多赘述。