今天咱们通过自然语言处理的视角重新看循环神经网络这一模型。
RNN
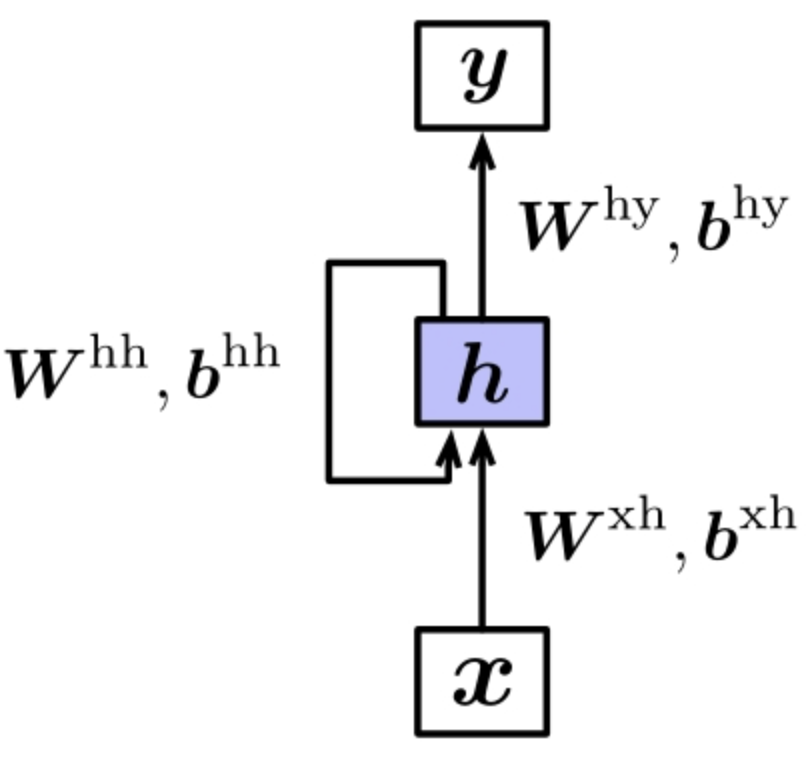
从这个结构的示意图来看,十分清晰,X作为输入除了经过Wxh的转换以外,把h的输出作为了当次的输入。这种形式的模型的结构让其相当于堆叠了多个共享隐含参数的前馈神经网络。
整个模型运行的过程就是输入一个序列输入,需要将循环神经网络按照输入时刻进行展开,然后将序列中的每个输入依次对应到网络不同时刻的输入,并将当前时刻的网络隐藏层的输入也作为下一个时刻的输入。
ht=tanh(Wxhxl+bxh+Whhht−1+bhh)(1.1)
y=softmax(Why+hn+bhy)(1.2)
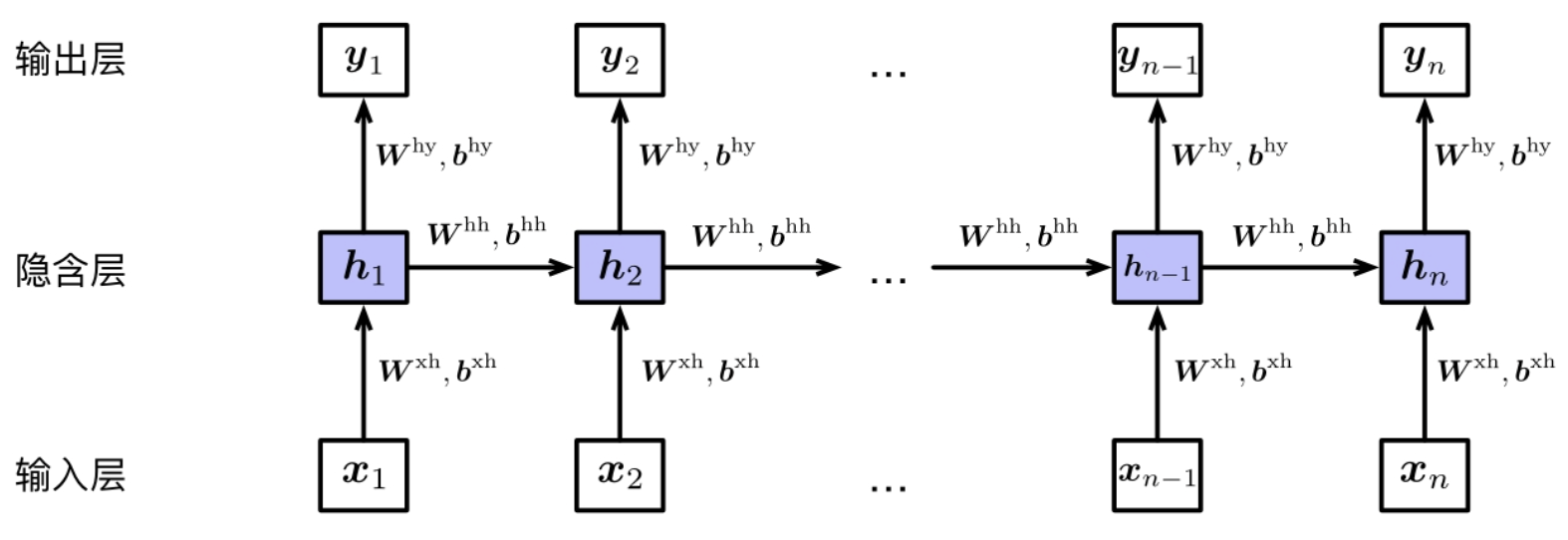
以上就是循环神经网络最后时刻的输出过程,十分适合处理文本分类的任务。除此以外还可以在每个时刻产生一个输出结果,这种结果适合处理nlp中的序列标注,例如词性标注,命名实体识别,甚至分词等。
LSTM
原始的循环神经网络中,信息通过多个隐藏层的传递,会导致信息损失的问题。这个时候引入了LSTM这种长短时神经网络的结果。
长短时神经网络是将公式1.1的隐藏层的更新方式进行了修改。
ut=tanh(Wxhxl+bxh+Whhht−1+bhh)(2.1)
ht=ht−1+ut(2.2)
这样的一个直观好处是直接将hk与ht(k<t),进行了链接,跨过啦t-k层,减少了网络层数。
而公式2.2中直接将ht−1将新状态ut进行相加,这种更新方式过于粗糙。也没有考虑两种状态对ht的权重。为了解决这个问题,可以通过前一个时刻的隐藏层和当前输入计算一个系数,并对此系数两个状态加权求和。
ft=sigmoid(Wf,hxxt+bf,xh+Wf,hhht−1+bf,hh)(2.3)
ht=ft⊙ht−1+(1−ft)⊙ut(2.4)
ft被称为遗忘层, 因为如果值较小的时候,旧状态ht−1对当前的贡献也较小,也就是遗忘了。
然而这种加权的方式有一个问题,就是旧状态ht−1和新状态ut贡献是互斥的,也就是说ft较小的时候,1−ft就会比较大。但是这两种状态对当前状态贡献有可能比较大或者比较小,因此需要使用独立的系数分别控制,因此引入了新的系数加权方式。
it=sigmoid(Wi,hxxt+bi,xh+Wi,hhht−1+bi,hh)(2.5)
ht=ft⊙ht−1+it⊙ut(2.6)
新的系数 it用于控制输入状态ut对当前状态的贡献,因此被称作输入门。,类似的还可以对输出增加门控制
ot=sigmoid(Wo,hxxt+bo,xh+Wo,hhht−1+bo,hh)ct=ft⊙ct−1+it⊙utht=ot⊙tanh(ct)
ct被称为记忆细胞,存储至今的重要信息。与原始的循环神经网络一致,既可以用hn预测最终的结果,也可以使用ht预测每个时刻的结果。
Bi-LSTM
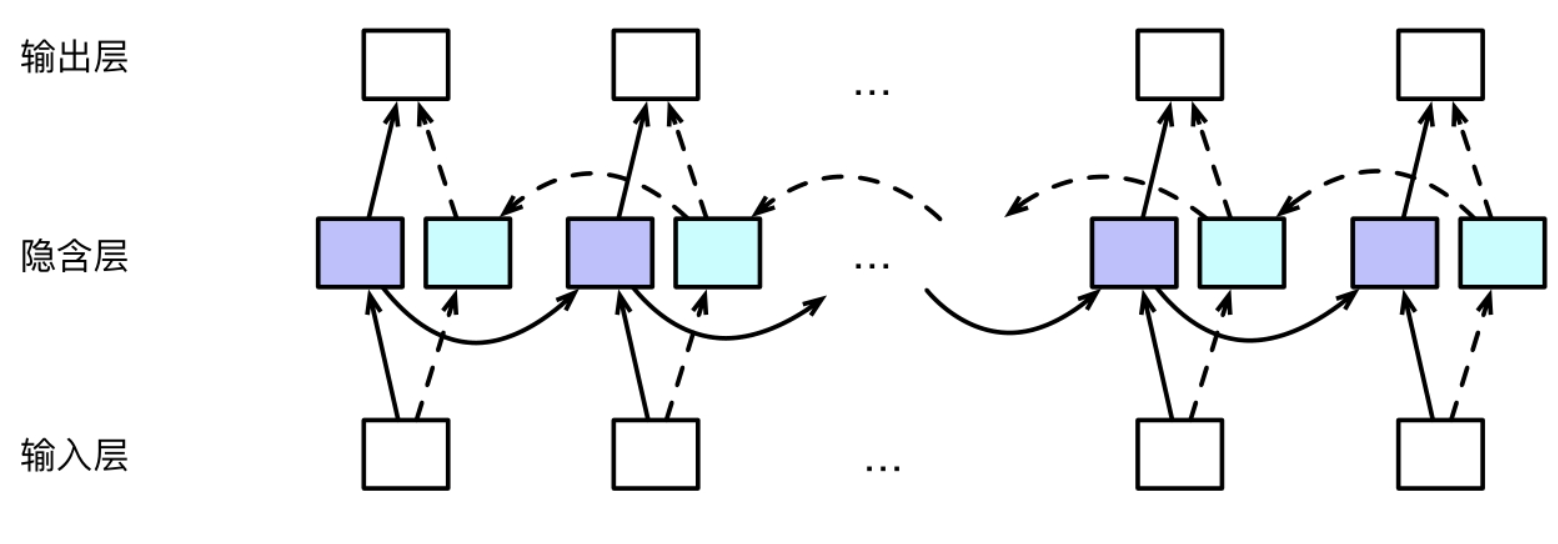
无论是传统的循环神经网络还是LSTM信息流动都是单向的,这样是在一些应用中是不合适的,如词性标注任务,一个词的词性不仅取决于前面的词也取决于后面的词,但是传统的神经网络不能利用某一个时刻后面的信息。这个时候就引入了双向循环神经网络的概念。
其核心的思想是将同一个输入的序列分别接入向前和向后的两个循环神经网络中,然后将两个循环神经网络的隐藏层拼接起来,公共进入输出层进行预测。
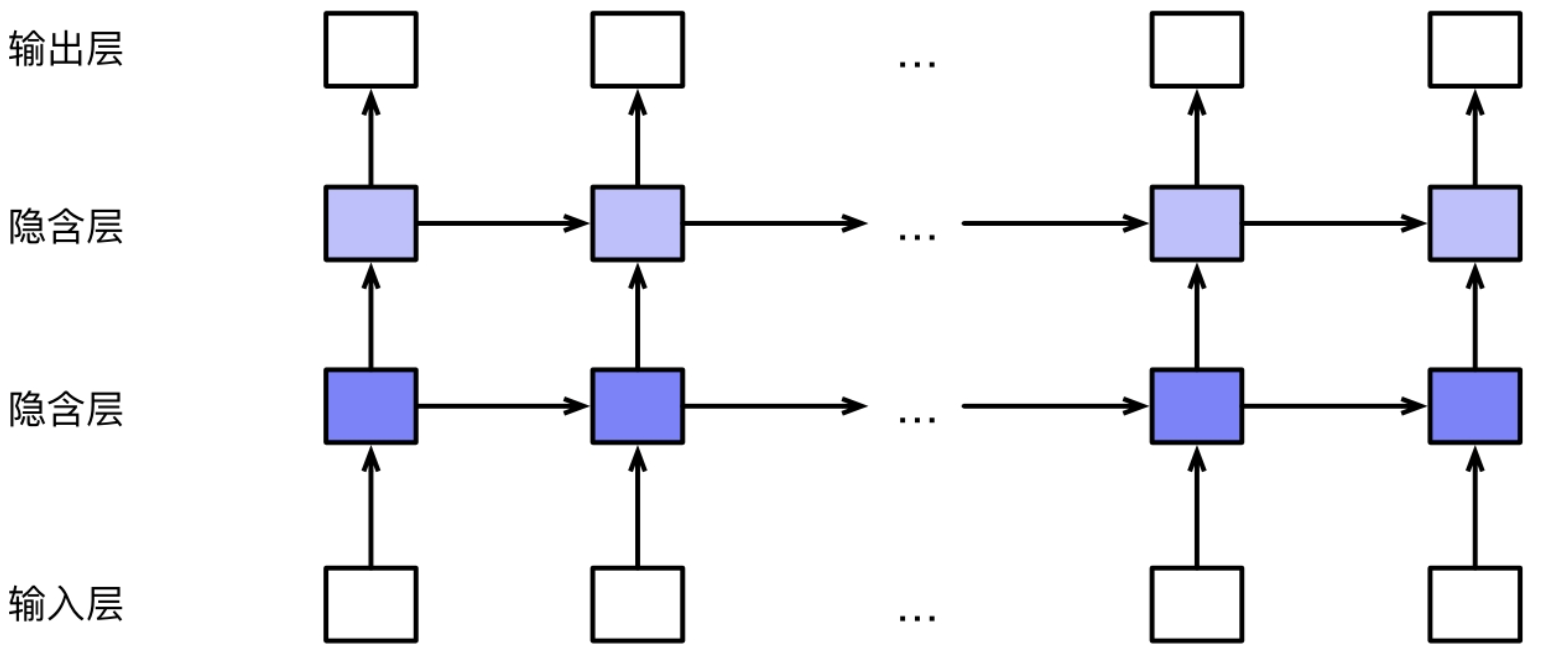
另一类对循环神经网络的改进方式是将多个网络堆叠起来,形成堆叠循环神经网络。
总而言之
今天通过呈现了循环神经网的演变过程,逐渐了解了整个技术的演进脉络,其实仅仅局限于使用倒是也没有什么帮助,但是了解一个东西的演进过程,能够给我们在其他的方面的演进提供线索。