社交类广告
接下来我们来讲社交广告的内容,对于社交广告常见的类型是Banner广告、信息流广告、视频广告、H5广告、开屏广告、插屏广告等。此外社交广告的定向方式也有也不同。
社交媒体中广告的定向方式主要分为两大类:一类是基于人的定向;另一类是基于内容的定向。基于人的定向,就是根据当前用户的属性来定向投放广告,例如,通过用户的性别、年龄、职业等用户画像数据定向投放广告,基于用户兴趣定向投放广告,或基于用户所在城市,地理位置定向投放广告等。社交媒体一般都会将内容分频道,不同的频道下是不同领域的内容,在某个领域的信息流中投放该领域的广告,更容易保护用户的阅读氛围,这就是基于内容的定向。例如,在军事频道投放洗面奶的广告和在汽车频道投放与汽车相关的广告,后者更可能不破坏用户的阅读氛围,但可惜并不是所有的广告都可以融入一个阅读氛围里。
社交网算法
社区划分算法
社交网络中,有时候从个体角度去分析用户的行为,相关数据会过于稀疏,如果对相似用户聚类,例如将喜欢同一个领域的所有用户作为一个整体来分析,就会有更多的数据可以利用。大型社交网络往往有几千万到上亿的用户数,除了传统的领域类别,还有更多关系密切的小圈子平时很难发现,但是对研究用户的行为却十分有用。社区分割算法就是根据网络的结构来对网络进行分割,最终将一个大网络分割成一些连接更加稠密的小网络。
Fast Unfoding(社区发现算法)是其中具有代表性的算法,主要的思路是通过把某一个节点i从当前社区中移除,添加到相邻的社区C中,然后对比调整前后的变化确定是否做这个调整,这个算法可以使用模块度的指标衡量
ΔQ=[2m∑in+2ki,in−(2m∑tot+ki)2]−[2m∑in−(2m∑tot)2−(2mki)2](1.1)
其中∑in表示社区C所有内部链接权重之和,∑tot表示是和C中所有节点相关的权重和,ki表示和i相关的所有链接权重和,ki,m表示和i相关的并且在C内部的链接权重和。m表示整个网络的所有链接权重之和。

下图是使用这个算法做社区划分的实例。
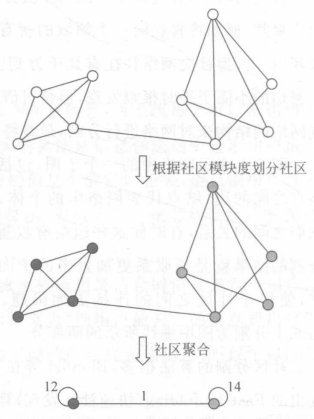
用Fast Unfolding算法对社交网络进行社区分割,一个用户只能属于其中一个社区,还有一些社区分割方法,同一个用户可以属于多个社区,下面的分割方法就是其中一种,主要分3个步骤。
第一步是将目标客户u的直接互动用户作为一个集合U1,然后找到所有的U1的最大团Ti,这里最大团的意思就是团中所有的节点都是强强联通的。
第二步对每个Ti进一步扩展,这次扩展对象是属于U1但是没有在Ti中用户,假设有一个用户u^被划入了Ti,新的集合Ti^,通过下面的公式进行判断u^是否可以划入。
U(Ti^)=∑outweight(Ti^)∑inweight(Ti^)
∑in为Ti^内部所有链接权重之和,∑out为Ti^外部所有连接权重之和。如果U(Ti^)>U(Ti),可以划入新的社区。
第三部就是对第二步进一步拓展。
主要是就是把一个圈子的核心小圈子找到,然后基于小圈子不断扩展。
社区内容扩散
假设用户与社交网络中的内容交互收到两个因素影响,一个是个人的喜好,一个是社交网中的他人的喜好,那么一个特定的用户集合中,通过什么样的顺序投放给他们同一个广告,最后可以使该广告互动效率最高。其实这个是一个社会影响最大化的问题。
视频类广告
比较经典的方式就是播放视频的过程中插播一个广告,让你不得不看的形式。下面我们就介绍视频类广告需要一些关键模块。
流量预估
在按流量售卖的广告系统中,很多订单都提前售卖,流量预估是必不可少的一个模块,系统需要在订单开始投放前预估有多少流量满足订单的定向条件,然后分配给广告主可以在约定时间内投放完的量。一般来说,流量是有规律的,例如,每天凌晨的流量比较少,晚上的流量相对较高;工作日的流量随时间波动比较明显,而周末的流量则是外一种曲线。这些流量波动规律和用户的行为规律息息相关,这为流量预估提供了可能。
流量预估的目标是
mind,t∑loss(h(Xd,t;θ),Yd,t)(2.1)
D表示训练集合,T=24h,Yd,t表示第d天的第t个时间段的流量,Xd,t表示该时间段对应的量化特征,h表示预估函数,loss表示均分误差,其实这是一个模型的损失函数。
库存分配问题
很多网友经常都会光顾腾讯视频、优酷、爱奇艺等大型视频网站,常常碰到各种类型的广告,对视频类广告并不陌生,那么,这些广告如何投放呢?本节将讲解视频广告的一个核心问题:库存分配。下面通过两个问题了解库存分配需要解决的问题。
视频类广告可分为GD(Guaranteed Delivery,保量交付)广告和 NGD(Non-GuaranteedDelivery,不保量交付)广告两种类型。GD广告是广告主提前和视频媒体签订协议,媒体需要在指定的时间内投放约定数量的广告,如果在合同生效期间没有完成投放任务,就需要按照合同赔付广告主,这种订单可以提前几个月售卖。NGD广告是媒体不需要保证投放量的广告,一般通过实时竞价的方式售卖,出价最高的广告获得展现,类似搜索引擎的竞广告。这样,当一个流量抵达的时候,在投放条件满足的况下,既可以出GD广告也可以出NGD广告。于是出现了第一个问题:广告系统如何分配流量库存给GD广告和NGD广告,才既能保证GD广告可以顺利投完约定量又能使整个广告系统收益最大化?
另外,不同的广告主投放广告的目的不一样,品牌广告主(Brand Advertisers)的主要目的是让广告触达尽可能多的目标人群,提升品牌知晓度,有些广告主(PerformanceAdvertisers)则更关心广告的点击率和转化率,也有一些广告主(Performance-BrandAdvertisers)的诉求介于二者之间,既有提升品牌知晓度的需求又对广告的短期互动率很关心。另外,不同类型的广告主可能会选择不同的付费方式,例如以提升品牌效应为主的广告主可能会选择CPM方式来结算,而只看中效果的广告主更多会选择CPC或CPA(Cost Per Action)的方式,诉求介于两者之间的广告主,这些付费方式都有可能选择。于是就有了第二个问题:广告系统如何分配流量库存给追求不同目标的广告主和采用不同付费方式的广告主,并能使得他们的目标都能达成?
库存分配问题可以理解成一个匹配的问题。当广告请求到达的时候,系统判断该请求的用户信息满足哪些广告计划的定向条件,然后选择其中一个广告展现给用户,做出一次分配。例如示例中的浏览用户信息就满足示例中广告活动的定向条件,这时称这个用户是这个广告活动的合法用户。由于NGD广告通过竞价方式售卖,所以对于NGD广告,分配的目标应该是让广告系统的收益最大化,尽可能赚到更多的钱。而GD广告首先需要保量,保障在合同期间将广告投放完约定的数量,但是有些GD广告主也非常关心短期的广告效果,系统还需要优化广告效果。
所以库存分配的目标应该包括3部分:NGD广告的收益最大化、GD广告保量、广告效果最大化。
库存分配算法
下图分别来自3个不同的广告主,他们都有不同的定向条件,包括性别、城市和年龄,且每个合约都有自己的约定投放量。Supply表示到达系统的用户,他们都有自己的属性和预估流量。图7.8中的连线表示
用户满足合约的定向条件,可以投放这个合约的广告给该用户。可以发现,满足右侧合约2的用户只有左侧的第3个和第4个用户,而这两个用户的流量总和是200KB,合约2需求量也是200KB,因此必须将用户3和用户4的所有流量都分配给合约2才能保证所有合约都能完成,那么算法如何实现?
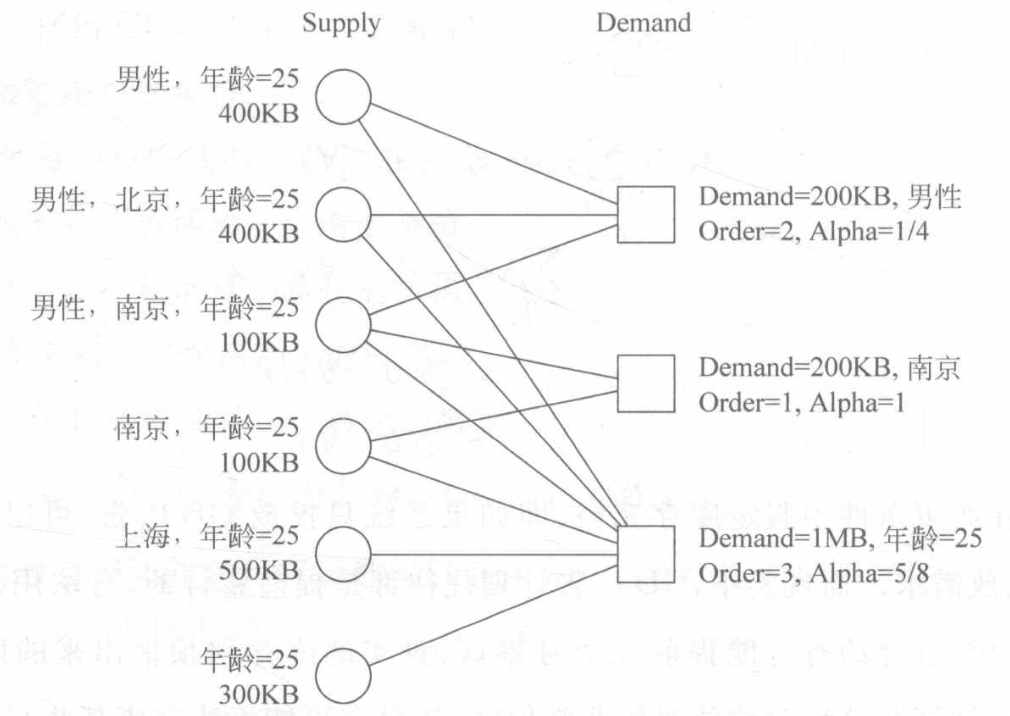
HWM算法
广告类算法一般分为离线部分和在线部分, 下面介绍算法的时候也按照换个框架介绍这些内容。
离线部分
每个合约订单orderj依赖Sj(表示满足合约j的所有用户流量的总和)大小来排序,Sj越小,排序越靠前。
为每个合约j计算分配概率aj
- 初始化每一个用户i的剩余流量ri=si,si表示为第i个用户的预估流量总量。
- 按照orderi的顺序,对每一个合约,计算满足下面公式aj
i∈T(j)∑min[ri,siaj]=dj
- T(j)是满足合约 j定向条件的所有的用户集, dj表示合约j的约定投放量,然后更新ri
ri=ri−min[ri,siaj]
在线部分
- 当任一个用户i到达的时候,获得满足定向条件的合约集合J,以分配顺序排序。
- 如果∑j=1∣J∣aj>1, 令l满足∑j=1l<=1, 的最大值, 然后分 配顺序中第l+1的分配概率就是0 ,或者是一个1−∑j=1l的值。
- 线上服务器根据分配顺序队列中各合约的分配概率决定是否出该广告,其中第j∈[0,l]的合约分配的概率aj.
根据这个过程,我们来计算一下上图那个匹配过程。
S1=400+400+100=900S2=100+100=200S1=400+400+100+100+500+300=1800
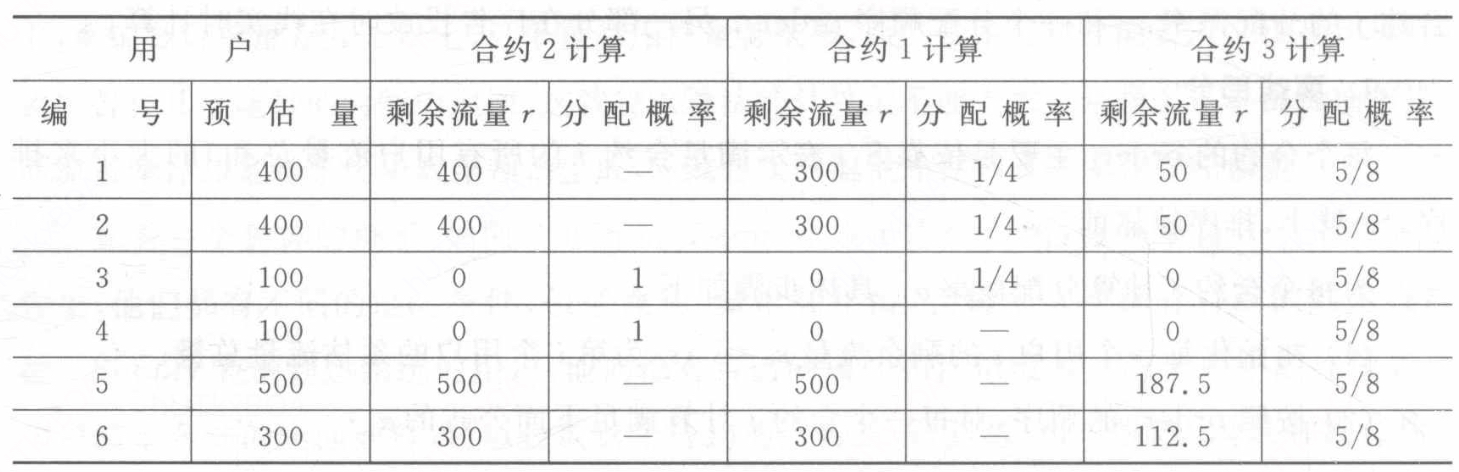
如果{南京,年龄=25}的用户线上到达的时候,可以得到l=1,那么合约2的广告必出。如果{男性,年龄=25〉的用户到达的时候,可以出合约1和合约3的广告,概率分别为1/4和5/8,可以发现还有1/8的概率不出合约广告,这种流量可用来投放NGD广告。
SHALE
HWM执行效率很高,是一种实际应用率较高的算法,但它是一种贪梦的分配方式,往往不是最优的分配方案。下面介绍一个SHALE的算法。
优化目标为
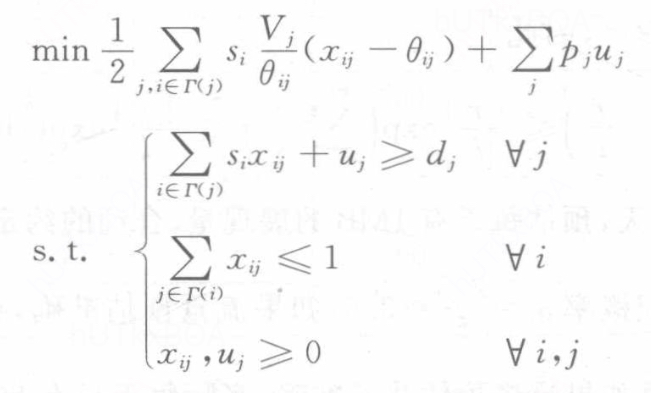
si表示某一个用户的库存
Vj表示合约j的重要度。
θij=Sjdj表示si中应攻分配给广告活动j的理想分配比例,Sj=∑isi。为满足合j的定向条件的所有可分配流量。T(j)是满足合约i 定向条件的所有的用户集合,dj是每个合约的预定投放量。
xij对应的算法分配量,是需要计算的值.
pj每一个合约的惩罚变量,表示对流量投递不足的惩罚。
uj,合约j当前投递不足的流量。
SHALE的主要思想是离线计算并保存与合约相关的优化参数,然后在线阶段通过这些 参数还原最优解,这样就不需要保持每一个xij,它所取得的分配方案多数情况下会比HWM好,但是时间复杂度也会更高。