MOE结构
MOE结构是DeepSeek比较大的创新, 不管是从模型性能上,还是计算性能上, 都是非常好的设计。这一个部分其实替换掉传统的Transformer中的FFN的结构。
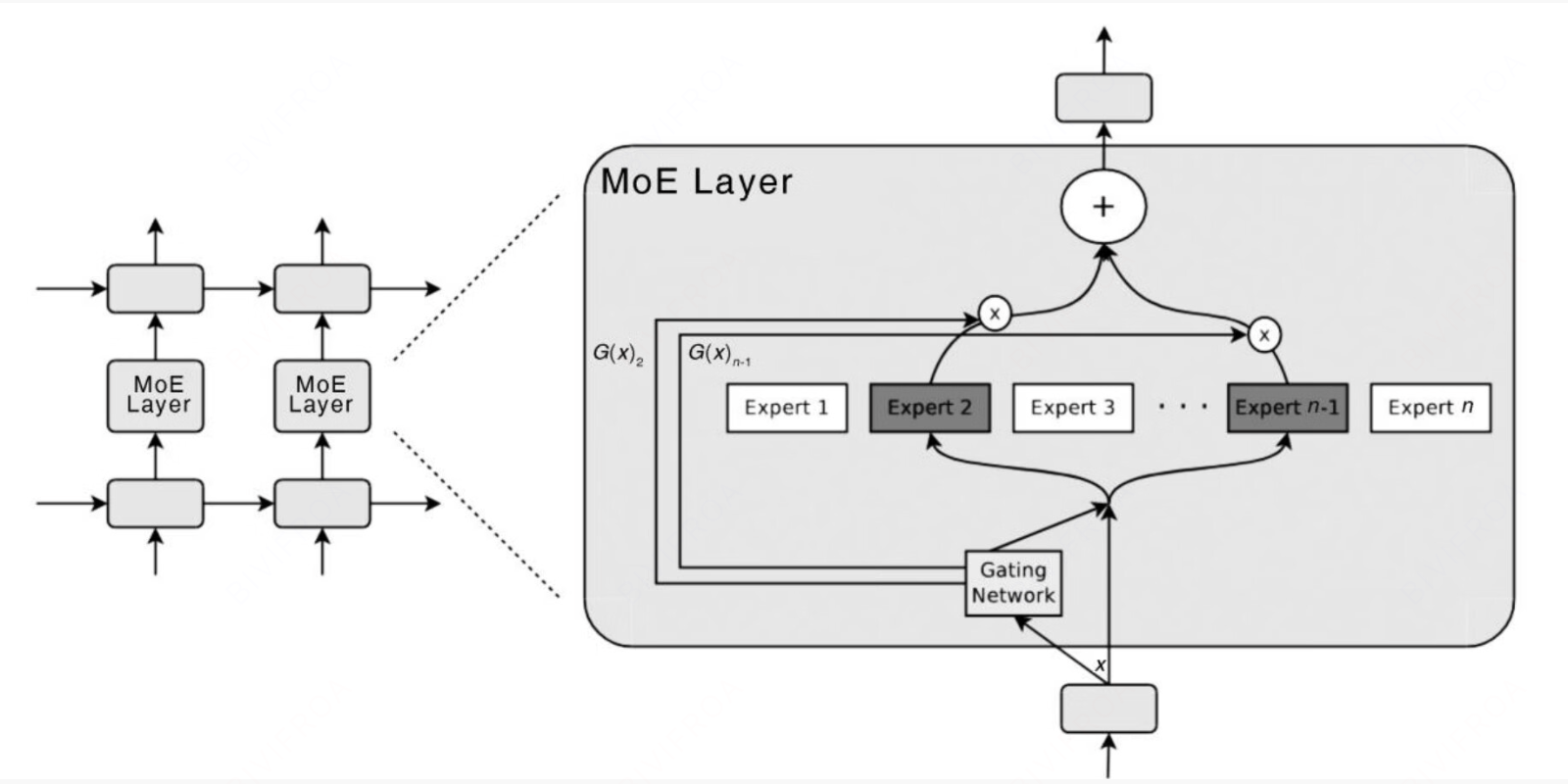
我们来分开看当前的网络结构
专家网络
MOE结构中有多个专家网络,设计的预期是希望能够让多个专家能够各自负责不同领域的知识内容,完成任务的结构。
门控网路
门控专家是整个网路的一个路由,这个路由是要识别不同问题需要找那些专家。这个部分也是整个模型的精髓,这里门控网络输出的是一个概率分布, 一般会选择top去做激活, 让计算复杂度收敛到一定的区间上。
但是门控也会有带来一些问题。
- 专家热度过高的问题, 大部分问题都是几个专家回答的, 其他专家没有什么用。也叫做负载均衡问题
门控网路的计算过程如下。
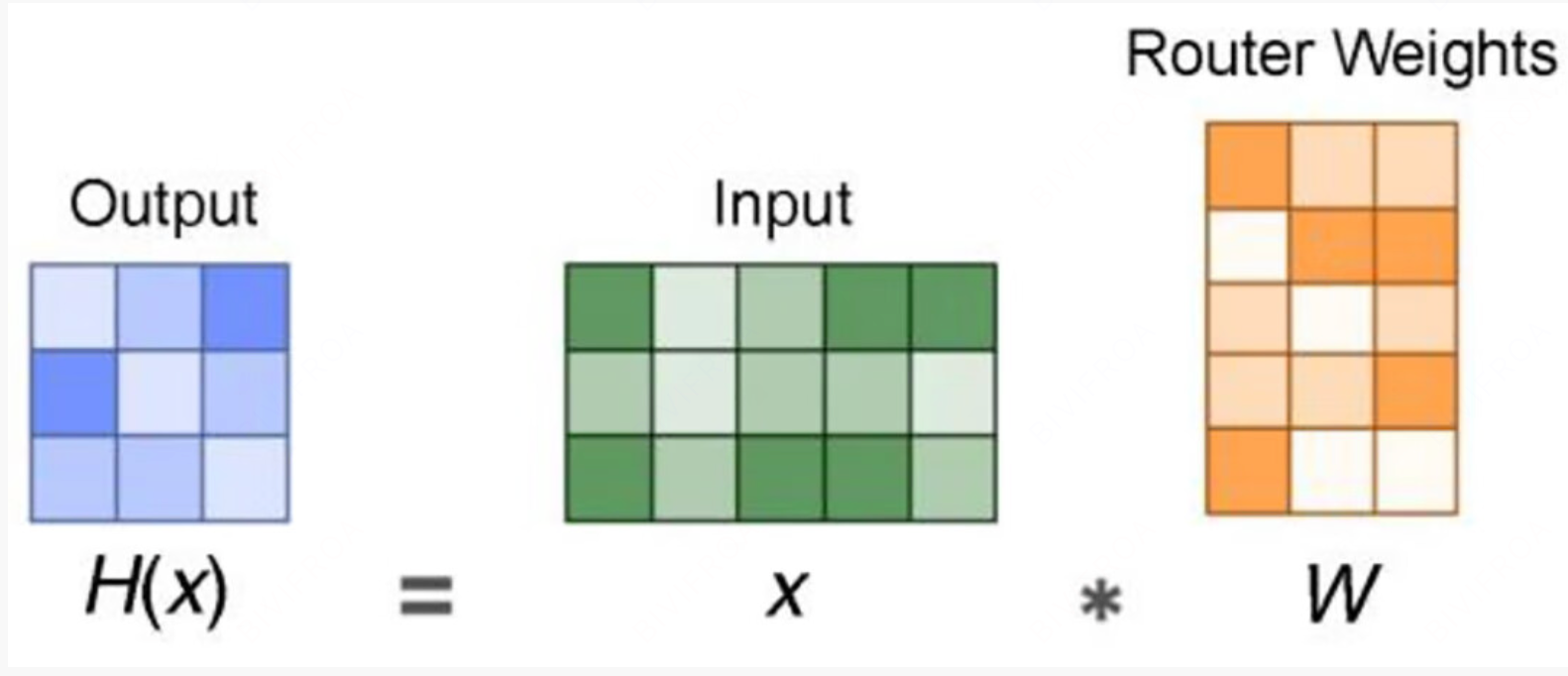
多个输出数据经过路由网络的重新加权,就能够得到最终的输出。
与传统的FNN的比较
相比于FNN, MOE结构中间增加了多个专家网络, 提升了整个模型的表达能力和对异质数据的拟合能力。
从激活的视角, MOE架构中有门控的机制,能够决定使用多少专家,其实变相决定了参数量, 这样对性能上是有极大的帮助的。
从对计算资源的利用率上, MOE架构因为其专家网络的激活的稀疏性, 其硬件利用率相比FFN是相对低20%-30%。
MOE在图像分类中的应用
自注意力在图像中的使用
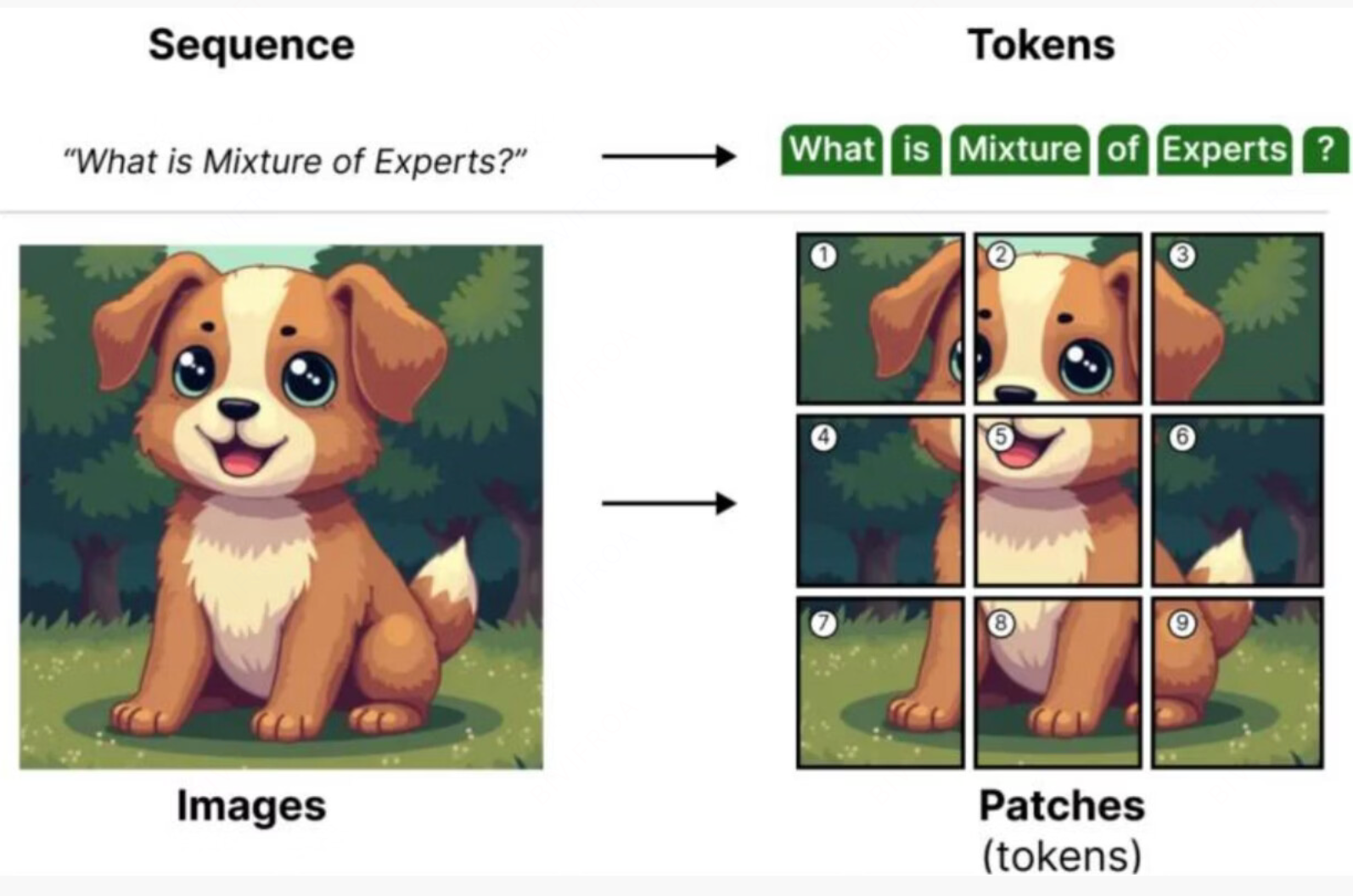
图像想要和使用Transformer的机制一定还是讲图像处理成token的模式,如下图所示, 会现将图片进行分片,然后按照原始Transformer的形式进行信息提取和学习,中间引入图像的位置坐标作为位置编码。
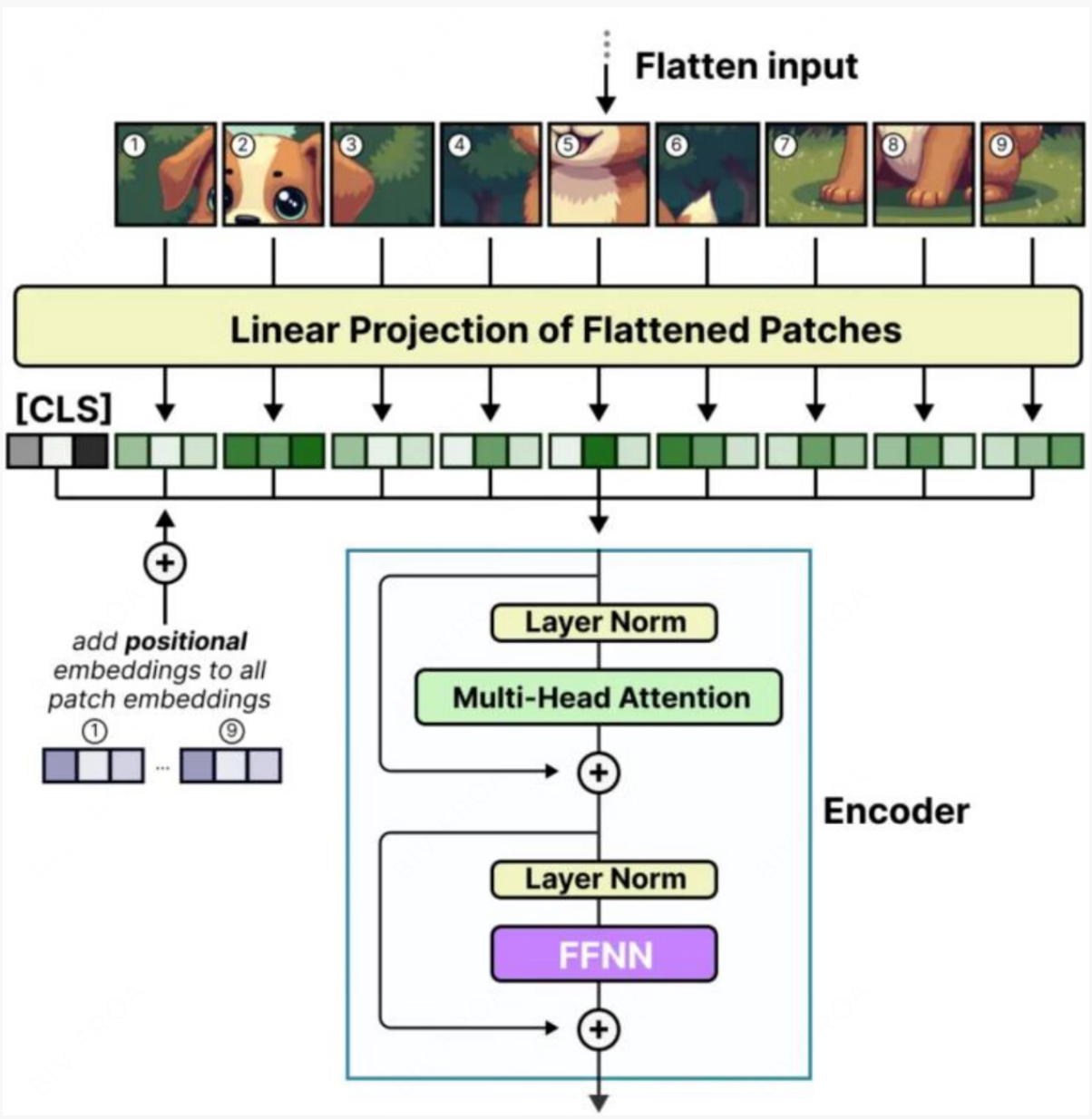
patch Embedding and position Embedding
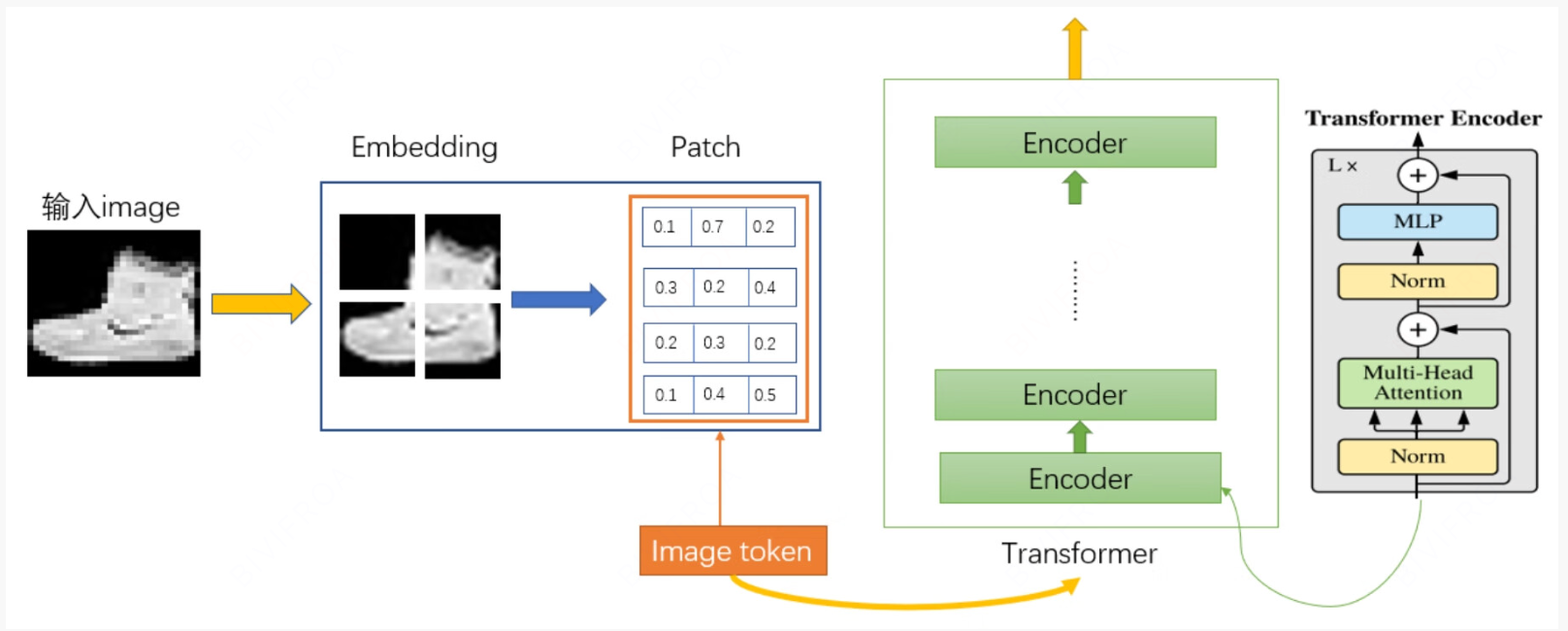
上图是一个切分过程, 每个切块会打成一个序列,这里我们给一下切分的实例, 对于一个28 x 28的图像, patch大小是4 x 4 ,每个图就有49个patch,这个49可以作为最终映射的序列长度,所有最后的经过网络的处理会形成 49 x 14的token。
图像下的MOE详解
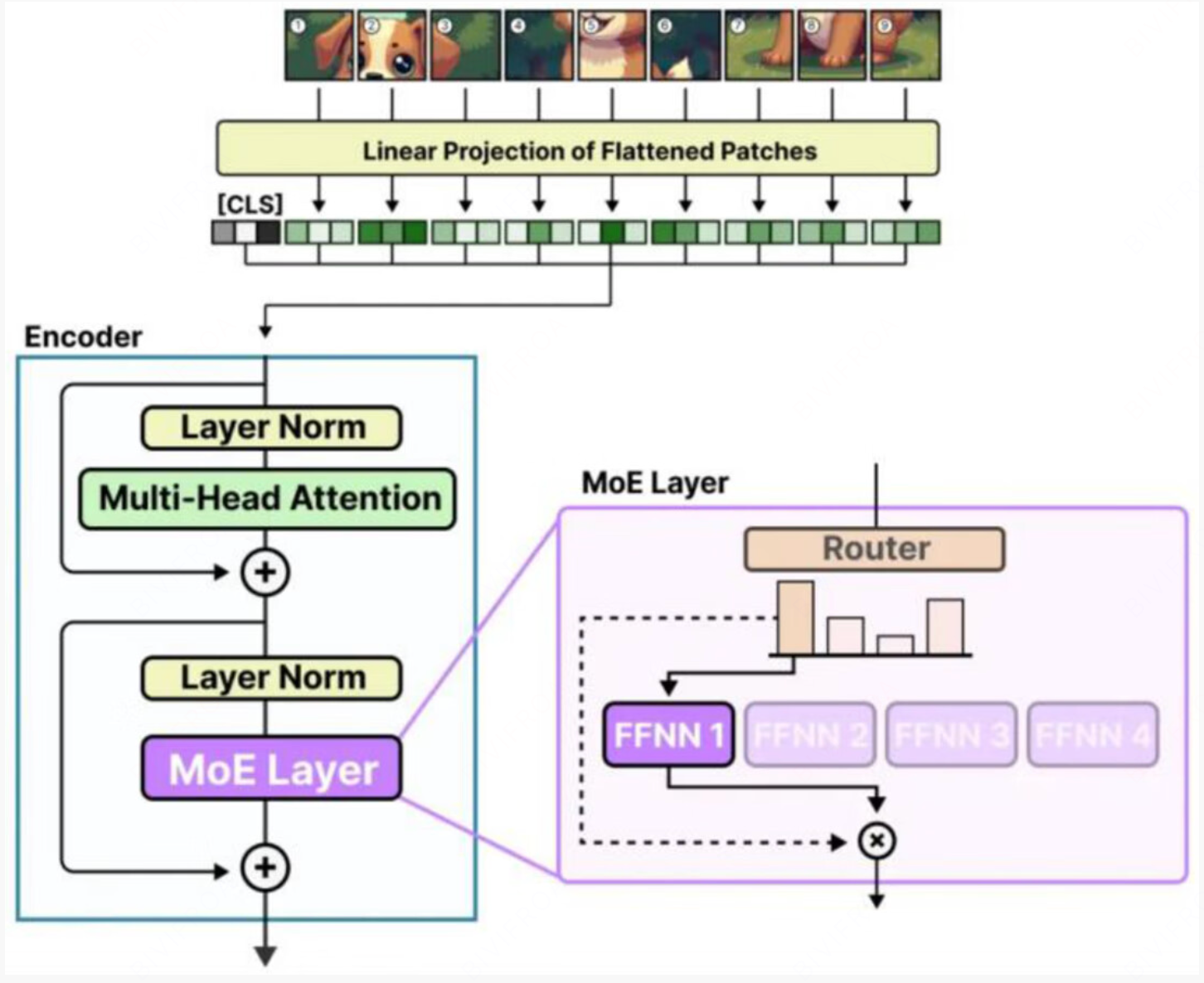
类似的我们也是将原有的FFN替换成Moe结构在路由选择的时候, 会把不同的token 放到不同的专家模型里进行学习。
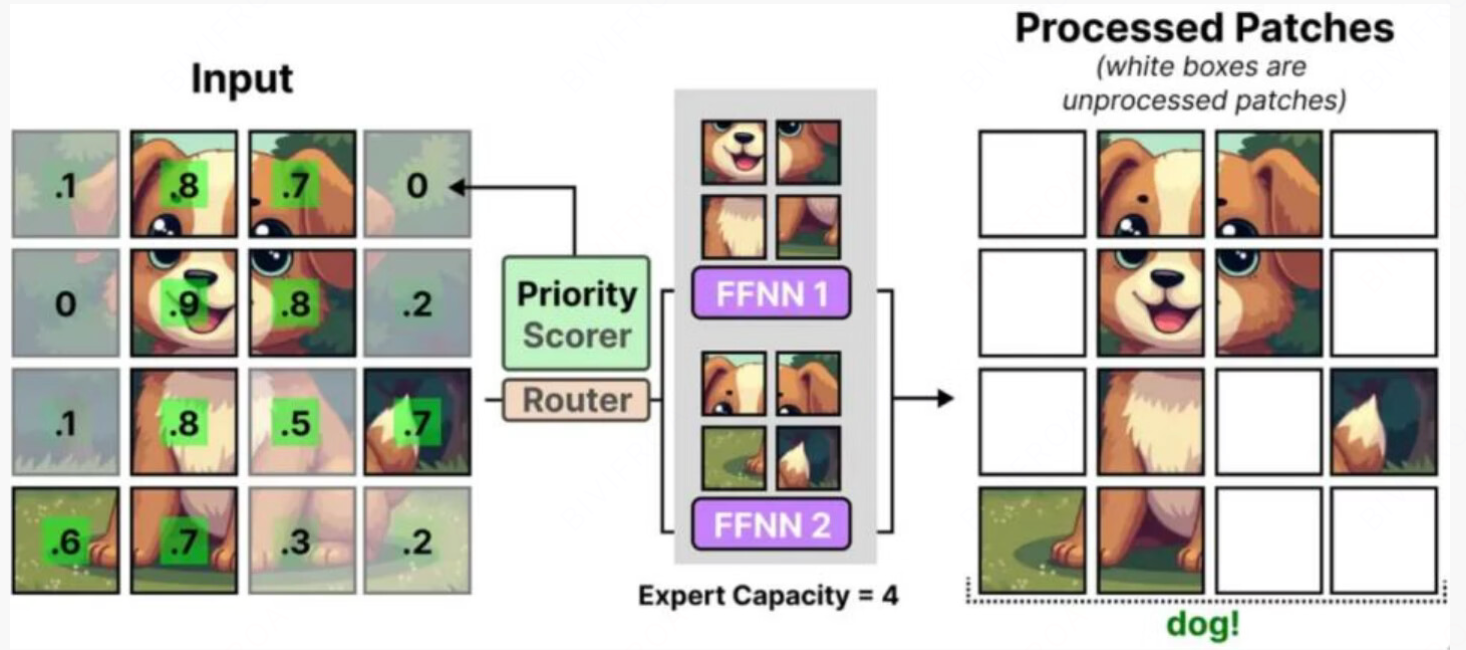
下图是一个经过Moe选择的图像
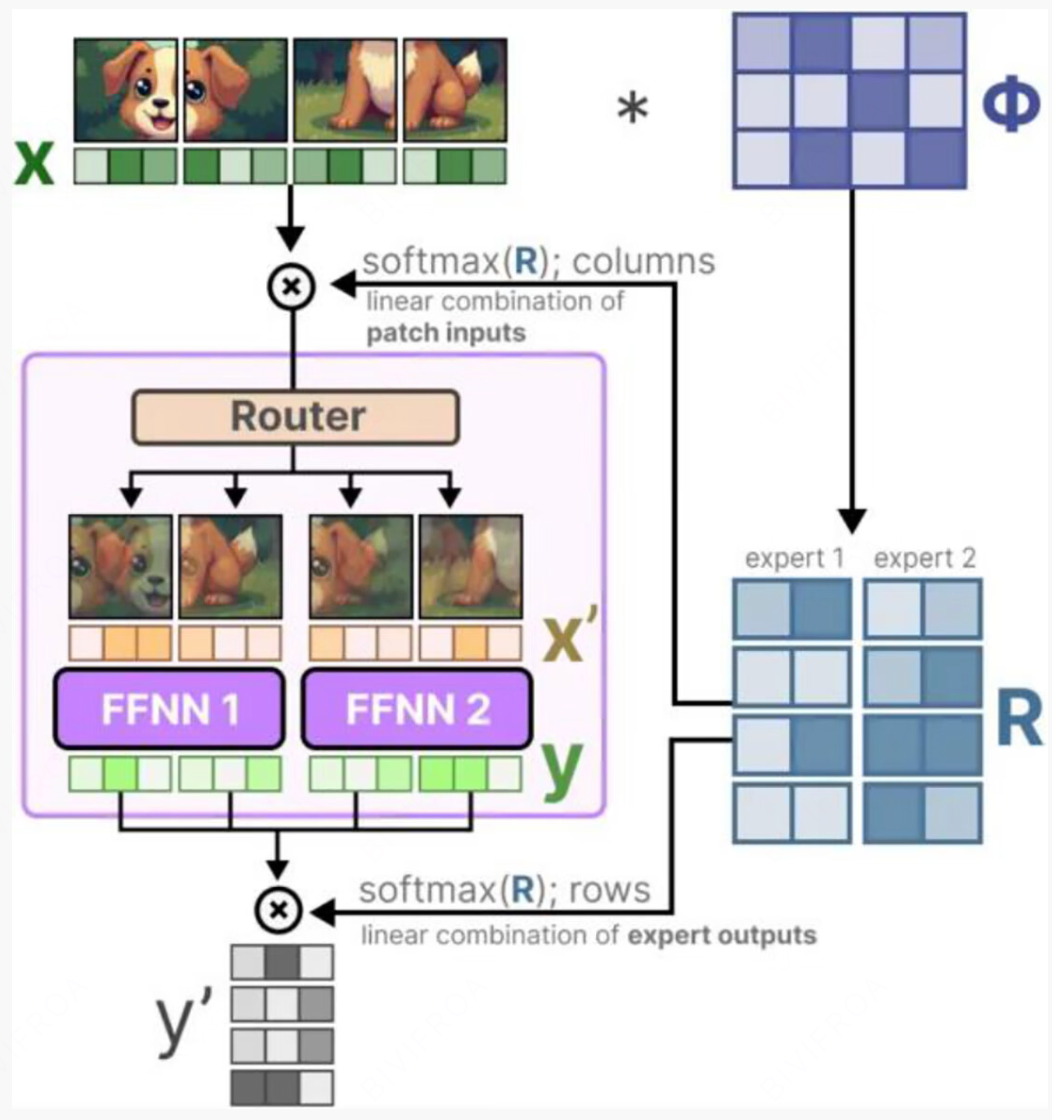
总而言之
其实Moe结构的可迁移性还是挺好的,只要能通过Transformer结构处理的,都可以通过Moe结构尝试, 而且我绝大大家可以把Moe架构理解成一个压缩机制, 将部分信息通过Router进行存储, 在结合专家就能得到比较好的结果。