KV加速推理
DeepSeek 第一个优化的点就是推理加速上, 这一点可能小模型上不见得是最重要的,不过当模型大到一定程度就成为模型的一个瓶颈性问题啦。 我们先来看看正常一个模型推理复杂度是怎样的。
推理复杂度

原始的每个token的计算量为 (P+1)+(P+2),..,(P+L)的等差数列, 这个累加以后就是P(L+P)。 这个就是生成token的计算量。 除了生成token以外,另一部分就是注意力机制的计算,对于自注意力的计算,复杂度一般是和序列长度L有关系, 我们一般会简单算成2L(L+1),所以最终的复杂度为
2L(L+1)+P(L+P)
那么计算复杂度已经是这么大啦, 如何能做到计算加速呢? 比较容易想到的思想缓存思想, 把计算过的内容留下来,复用一次就少计算一次。
缓存思想
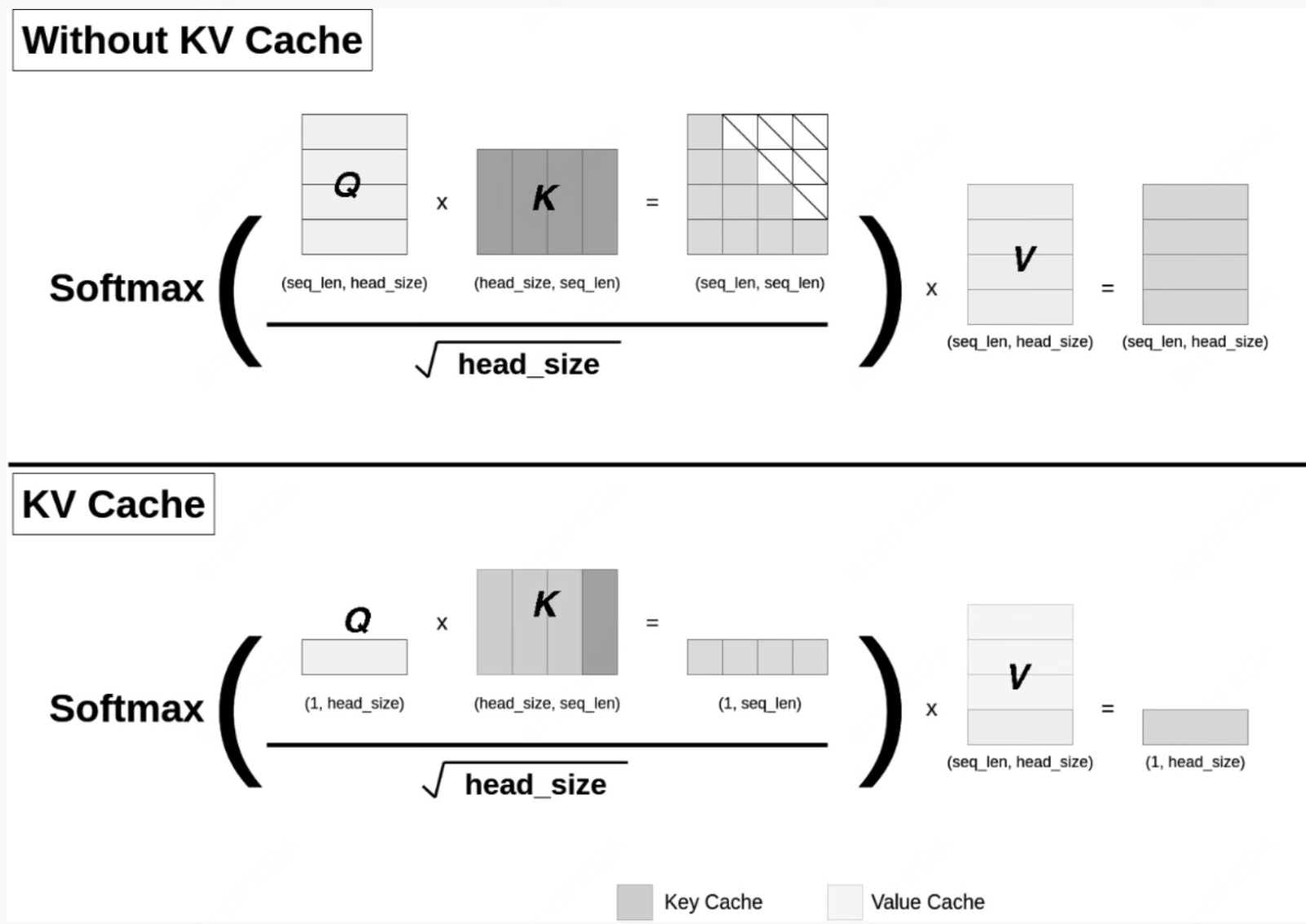
我们回顾原始的QKV模式, 能够发现, 虽然我们是自回归的模式,因为其独特的计算模式。 每一个字或者词的计算是可以服用的,用下图能够看得更加清晰一些。
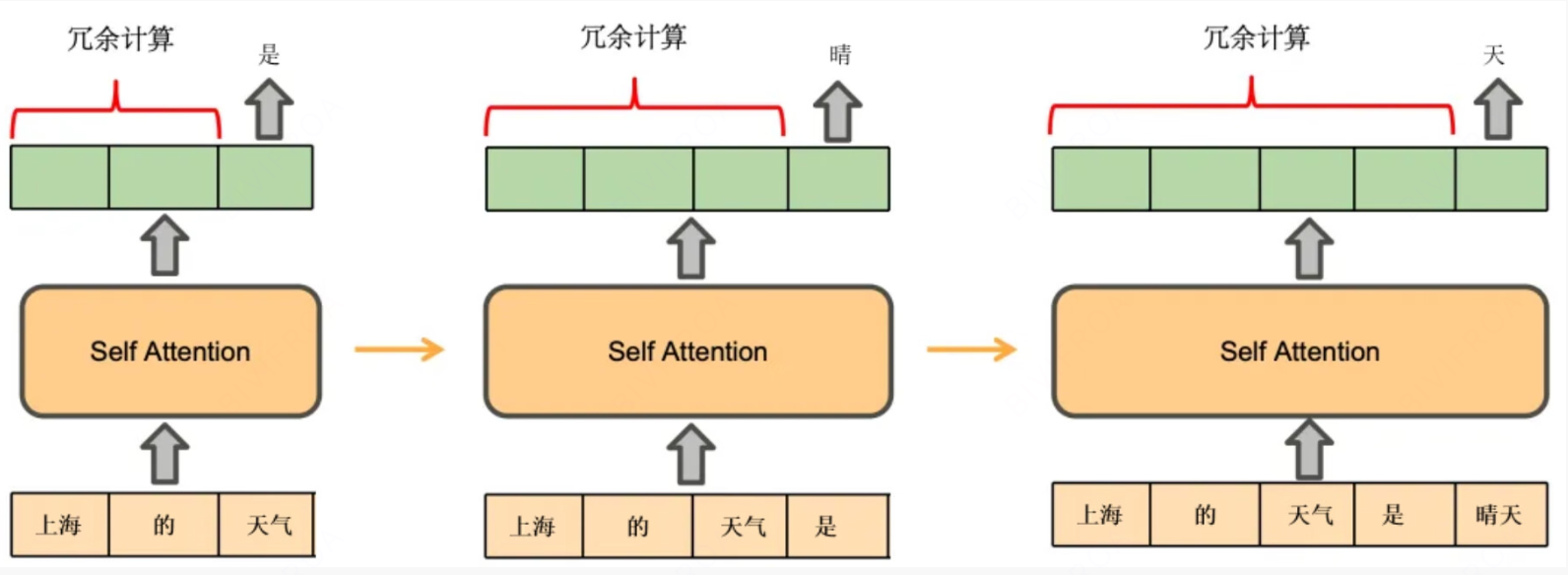
很朴素的思想就是我们每次都仅仅计算新的字或者词的向量,而不是把从句子初到当前位置全部计算,感官上其实每次都是走的查询逻辑, 真正形成新的向量的仅仅是最后一个字。
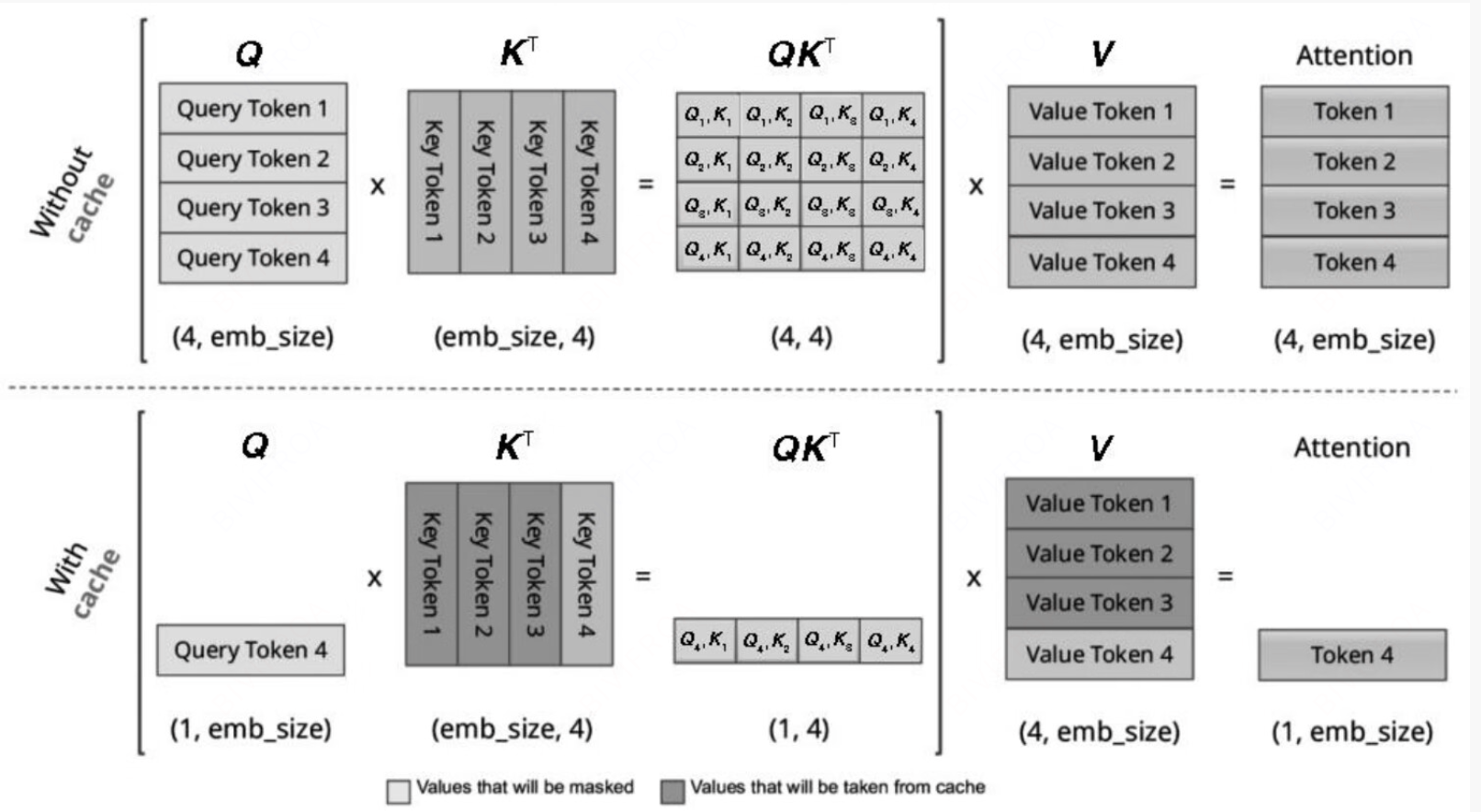
总而言之
那么这种模式在时序自回归上其实也是可以使用的, 是解决性能问题的一个杀手锏。