一直没有杀下心来看看机器学习中的优化方法,当然一般是相对比较成熟,确实也不需要我们关心,但是好奇心的驱使还是扫一扫吧。既然做了既要尽量做全套。
一阶方法
梯度下降
先来说咱们了解最大的梯度下降方法,大部分的论文中都是之前推导一顿猛如虎,最后梯度一笔带过,那么梯度下降到底是啥意思呢?
其实梯度下降是指我们在做优化的过程中,寻找梯度的方向(一般是最优值的方向),通过不断的迭代,最终达到最优值的过程。
下降方向d的最直观的选择是最快下降的方向。只要目标函数光滑、步长足够小,并且还没有到底梯度为0的点,那么沿着最速下降方向,函数一定会减小。
g(k)=▽f(x(k))(1.1)
其中x(k)是第k次下降的迭代的设计点。
梯度下降中,通常将最快下降的方向标准化。
d(k)=−∣∣g(k)∣∣g(k)(1.2)
如果选择能够使f在最大程度上减小的步长,会产生锯齿状的搜索路径,实际上下一个方向与当前方向正交。
例子
假如有f(x)=x1x22,梯度为▽f=[x22,2x1x2], 对于x(k)=[1,2],标准化的下降方向是d=[−4,4],标准化后d=[−21,−21]
对于步长就有如下的表达。
a(k)=arg minf(x(k)+αd(k))(1.3)
优化使得导数为0
▽f(x(k)+αd(k))Td(k)=0▽f(x(k)+αd(k))T=d(k+1)(1.4)
所以很简单得出最优的搜索方向是两次搜索方向是正交的。
共轭梯度
上面的文章介绍了梯度下降的方法, 但是梯度下降的方法对于狭窄的凹地性能不是很好,所以引入了本文要讲的共轭梯度。
它的上文讲到的梯度下降其实十分相似。
xi+1=x1−αd(2.1)
共轭梯度并不是通过走梯度的方向,而是走了一个d的特定方向。
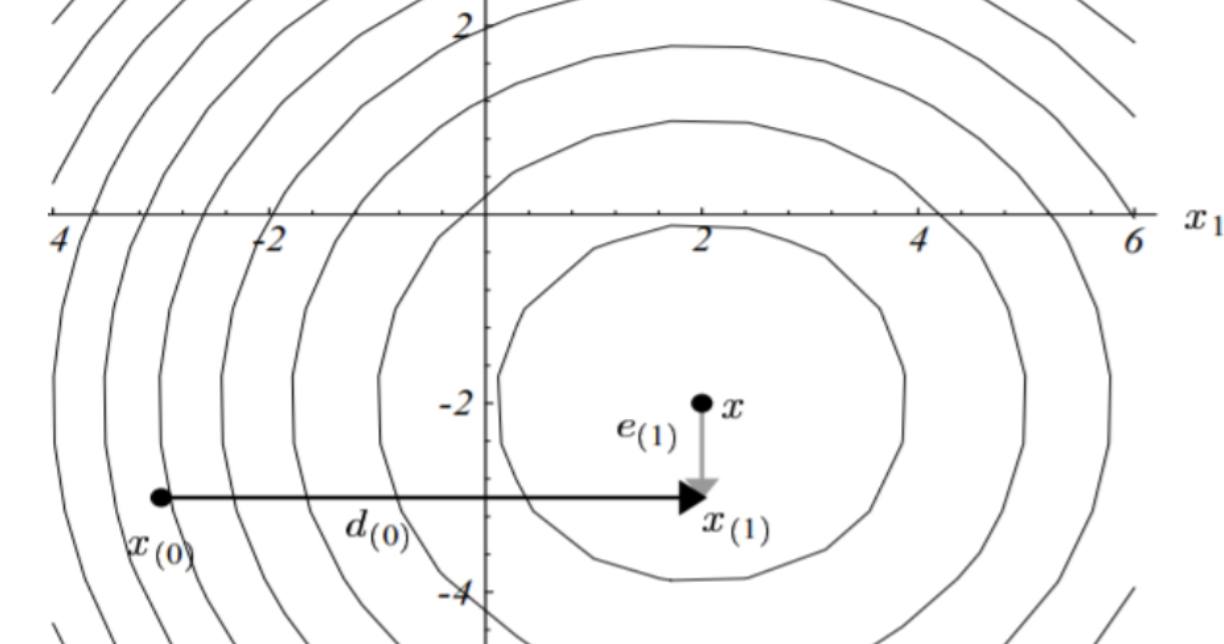
看上面这个图, x是我们要逼近的最优值,e是误差e=xi−x, 可是咱们开始的时候是不知道e的值的存在的,所以退而求其次是找到e的共轭向量,可以从图中看出e的共轭向量与e是正交的。 这里要介绍一下共轭向量的概念。
PiAPj=0(2.2)
其中A是一个对称正定矩阵。那么继续推导,我们想要找到如下的表达
dTAe=0(2.3)
这个表达式仍然有e,也不能求解,这里继续引入残差来代替误差。
残差与误差
e=xi−x
但是这种定义显然是没法直接用的,因为我们不知道精确解x.继续将就,当误差收敛到0的时候, 是不是Ax=b的时候(针对二次方程 f=21xTAx+bx+c的导数为0),ri=b−Ax,发现解决了误差不可知的问题。在实际的程序中,我们还常常定义相对残差,即上一步迭代和这一步迭代的残差的相对变化率。在实际的程序中,我们还常常定义相对残差,即上一步迭代和这一步迭代的残差的相对变化率
ri=b−A(ei+x)=b−Aei−Ax=−Aei
这个时候搜索的方向终于确定啦
dTAe=dTri=0(3.1)
接下来我们只需要构建一个与残差正交的向量就可以了。这部分内容是由施密特正交化来完成
完成的共轭梯度法
- 设定初始值
d0=r0=b−Ax0
- 计算系数α
αi=diTAdiri+1Tri+1
- 迭代一次
xi+1=x1−αdi
- 计算残差
ri+1=ri−αAdi
- 计算β
βi+1=ririri+1Tri+1
- 计算搜索方向
di+1=ri+1+βi+1di
最终搜索的过程如下图。
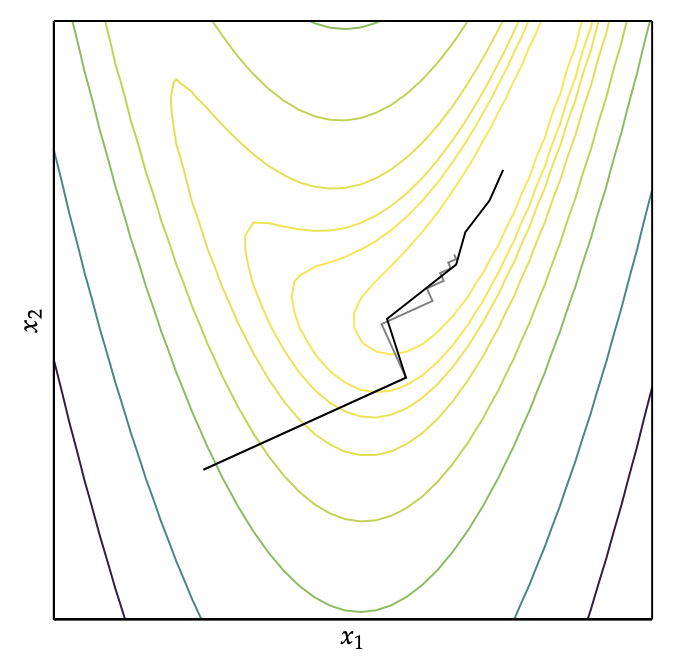
摒弃的梯度下降的正交搜索,更加快捷。
动量
采用梯度下降的方法,还存在一个问题是在平坦的区域上优化速度更慢,这个时候一般采用动量的方式优化,动量方程如下。
v(k+1)=βv(k)−αg(k)x(k+1)=x(k)+v(k+1)
Nesterov 动量
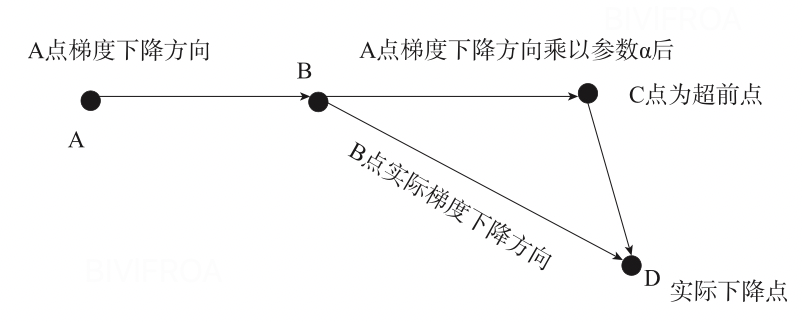
动量的一个问题是,梯度在山谷底部减速不够,往往会超过谷底。Nesterov 动量修改了动量算法,以使用预测未来位置的梯度:
v(k+1)=βv(k)−α∇f(x(k)+βv(k))x(k+1)=x(k)+v(k+1)
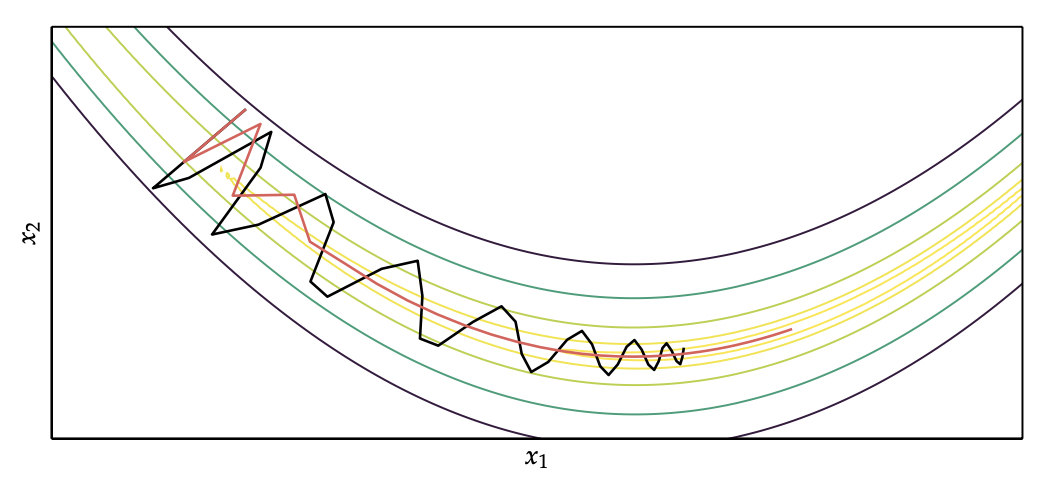
Adagrad
动量和Nesterov动量的一个问题是更新每个x都使用同样的学习率,而Adagrad可以自适应的调整学习率使用每个x的维度。
传统梯度下降算法对学习率这个超参数的敏感性以及对参数空间的某些方向的处理不足,使其在深度学习中显得力不从心。尤其是深度学习中存在高维空间、多层神经网络等因素,导致经常出现平坦、鞍点、悬崖等问题。
AdaGrad 算法是一种通过调整参数来设定合适的学习率λ 的方法。该算法能独立地自动调整模型参数的学习率,对稀疏参数进行大幅更新和对频繁参数进行小幅更新,AdaGrad 算法非常适合处理稀疏数据。在某些深度学习模型上,AdaGrad 算法也有不错的表现。但还存在一些不足,可能因其累积梯度平方而导致学习率过早或过量的减少。
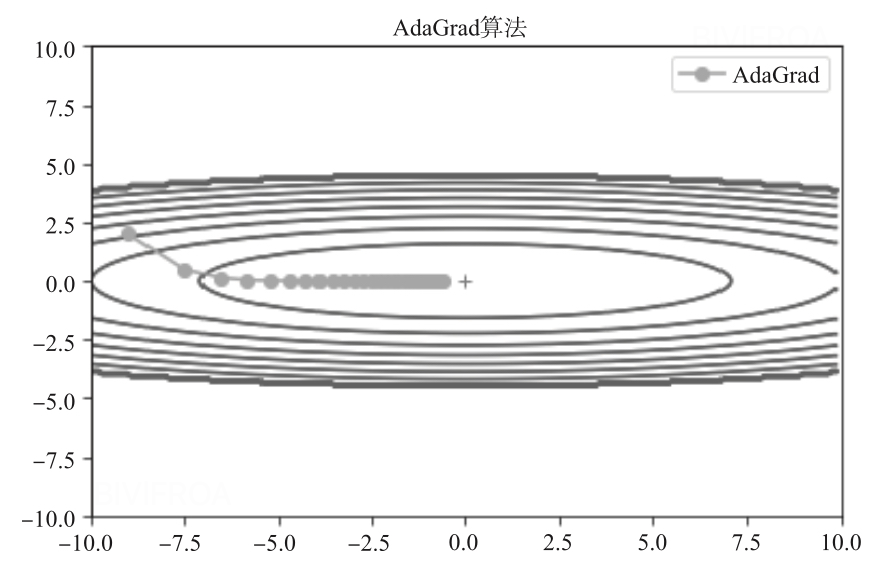
RMSProp
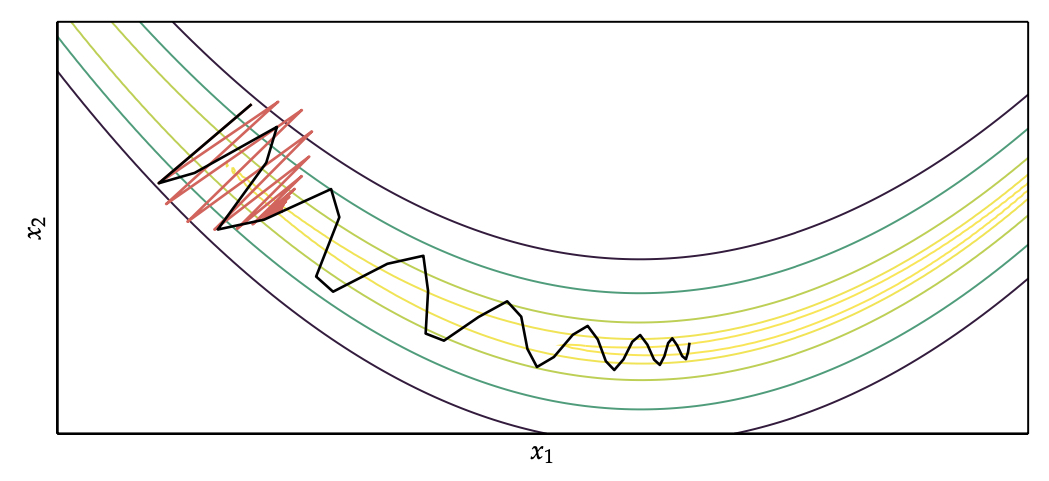
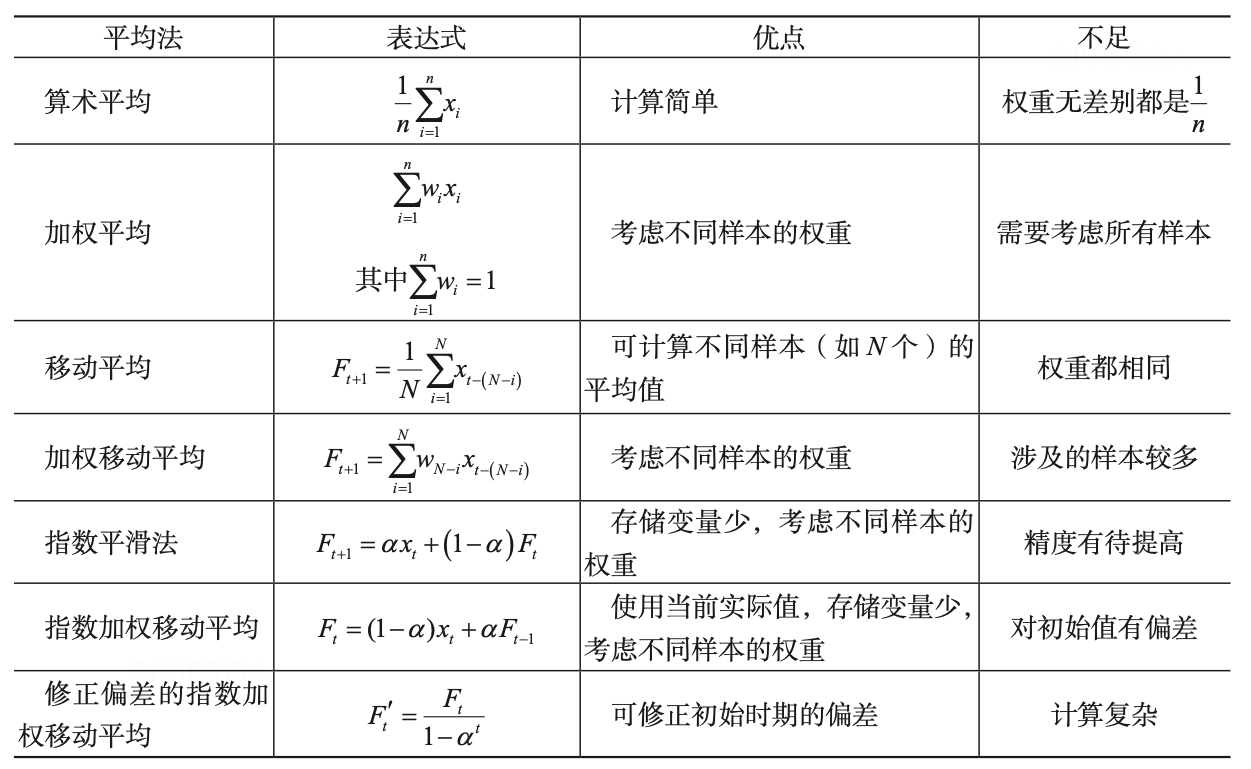
为了改善AdaGrad 在非凸函数下的表现,RMSProp 算法进行了修改。在凸函数中,算法可能振幅较大,如图2-64 所示。为了解决梯度平方和累计越来越大的问题,RMSProp 使用指数加权的移动平均代替梯度平方和,通过引入一个新的超参数ρ,用来控制移动平均的长度范围。常用的平均法的比较如下表
进而看下RMSProp的收敛过程。
总而言之
讲了这么多优化算法,下面这个图给一下各个算法之间的关系。
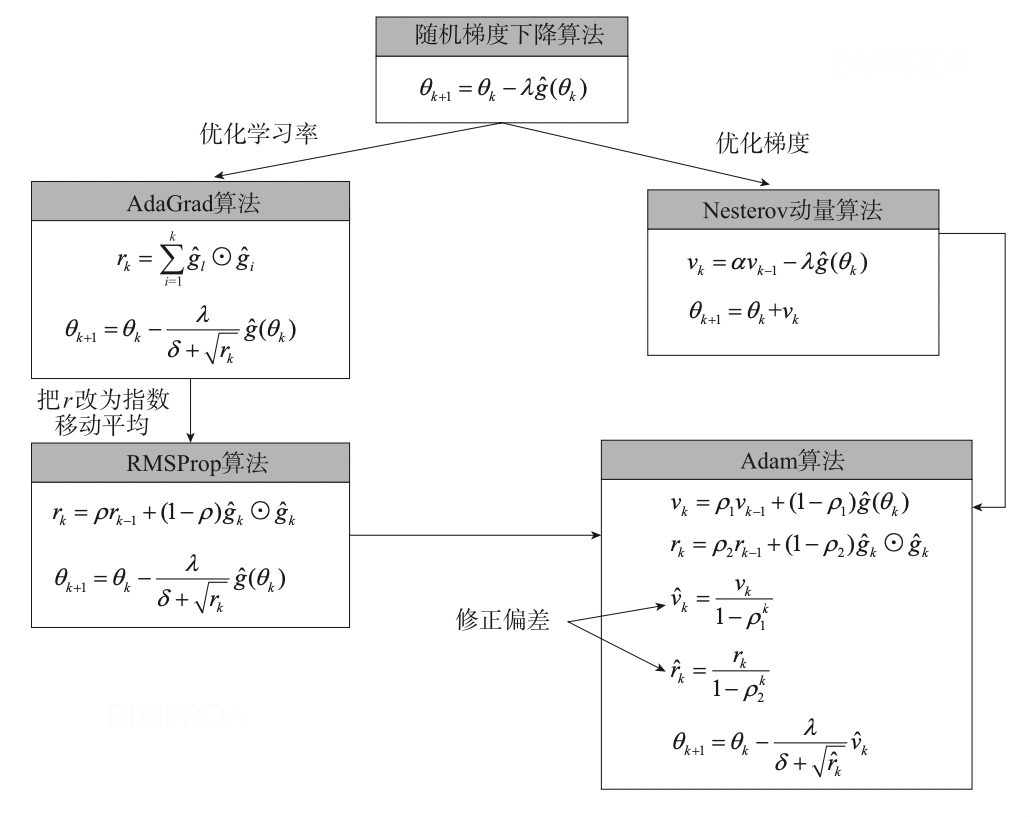
有时候,我们可以考虑综合使用这些优化算法,例如先使用Adam,然后使用随机梯度下降的优化方法。这种优化方法有时能达到不错的效果。实际上,由于在训练的早期阶段随机梯度下降算法对参数调整和初始化非常敏感,因此可以通过先使用Adam 优化算法进行训练,这将大大节省训练时间,且不必担心初始化和参数调整,一旦用Adam 训练获得较好的参数后,我们就可以切换到随机梯度下降+ 动量优化,以达到最佳性能。