今天来讲一个有趣的话题, 如何训练一个好的模型呢?如果你训练一个模型, 效果不好, 你会从哪些方面入手优化呢? 下面我们就一个一个说,每个问题的天花板也是有高有低的。
特征丰富程度
这一层就是我们经常提到的特征工程。这部分其实是你对问题的定义和理解。做业务算法的同学可能深有体会,做一个很好的特征需要你对问题的定义足够清晰, 对业务的理解足够深刻。那么如果我们在特征丰富程度上有所欠缺,体现的结果是什么样子的呢?
如果是用数学的理解是你构造一个空间,这个空间能够稳定的映射到目标的决策空间。
模型在不同数据子集上表现差异较大
这种现象比较好理解, 模型在不同的数据集合上表现差异大, 如上图所示,我们没有看完整的环境,导致构建y的映射上就是时而是对的,时而是错的, 这个时候的对错不取决于模型,而是取决于数据。
再泛化一层现象, 就是有可能训练集合和测试集合的效果差异大。
低效的错误分析
这种情况是当你分析模型的错误时,可能会发现某些类型的错误总是重复出现,例如特定类型的样本始终预测错误。就是因为模型没有对全景数据看清楚, 总是在同一个类型的问题犯错,这种case可以进一步分析,找到关键维度缺失的问题。
模型稳定性低
这一点主要说的是正常的模型中,一些输入数据的微小变化,对于结果的影响应该是平滑的, 这个和物理世界是相似的, 如果特征缺失比较严重的情况下,就会出现很多输入数据的微小变化, 对结果影响十分巨大,其实类似于局部的过拟合。
泛化性差
这一点也比较好理解, 如果你特征全景不全, 没有学习到事件的本质, 当然不容易解决更多类型的问题。
特征偏见
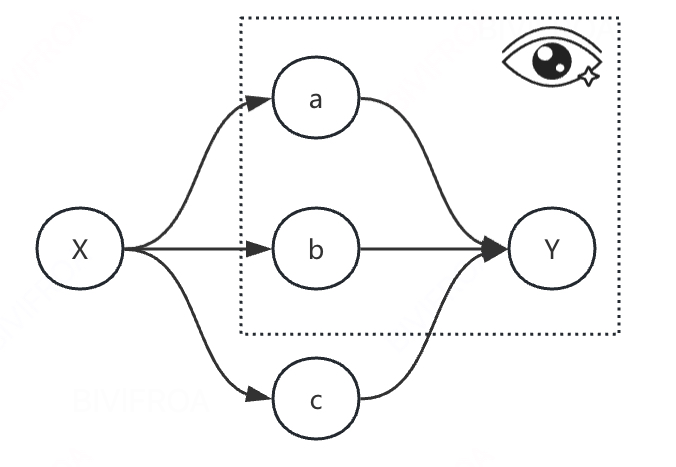
这里也衍生一种现象, 如上图的表示, 模型可能学到ab两个特征和Y关系较强,其他特征没有被使用,这种情况本质上也是特征缺失的表现。 当然这里的前提是学习效果不好的情况下。
特征利用率
特征利用率是一个比较好的视角, 其实特征利用率和模型拟合能力是有一点点重叠的。例如我们为什么在推荐系统中经常要引入FM等模型,其实是想提升特征交叉能力, 这本质上就是一种提升特征利用率的方法,其实类似的例子有很多, 引入GCN的网络模型就是提供邻居交叉的能力,进而提升特征利用率,多任务模型中, 经常将事件拆成顺承环节, 预测中间过程,也是提升特征利用率的方式。
那么特征利用率不足有哪些表现呢?
模型对特征不敏感
这种情况经常是我们加入了好多很重要的特征,但是模型效果提升不高,有的甚至还出现了下降的问题。相当于我们加入了有效的特征,但是因为没有被有效的利用,所以对模型效果提升有限。
高方差特征的存在
如果你观察到某些特征在数据中方差非常大,但模型却没有显著利用这些特征,可能是因为这些特征没有被有效地与其他特征结合或转换。
高方差特征通常包含更多的变化信息,如果模型没有有效利用这些信息,可能说明模型未能发现这些特征与目标变量之间的关系。
特征偏见
这里又要recall一下特征偏见的问题, 特征利用率的结果是预测仅仅来自于几个核心特征,其他特征被弱化掉。这也算是一个现象, 如果通过更新模型能够提升特征利用率,并优化模型,那就实锤了。
数据增强程度
这里的数据增强可以从图像中找到例子,例如图像任务中,我们经常对原始数据进行扭曲旋转等操作, 让模型更改在同一个标注上认识更多的类型, 这就是一种数据增强的方式。
泛化能力差
如果你的模型在特征完备的情况下, 泛化性出现问题, 那么就应该是数据增强没有做一些工作。
当然我们做业务策略的时候, 经常也会添加一些人造的数据,进行数据增强的操作。
模型拟合能力(记忆能力)
模型拟合能力这个应该在大家的工作中每天都能碰到, 也是大家经常想把xgb变成深度模型的动机。
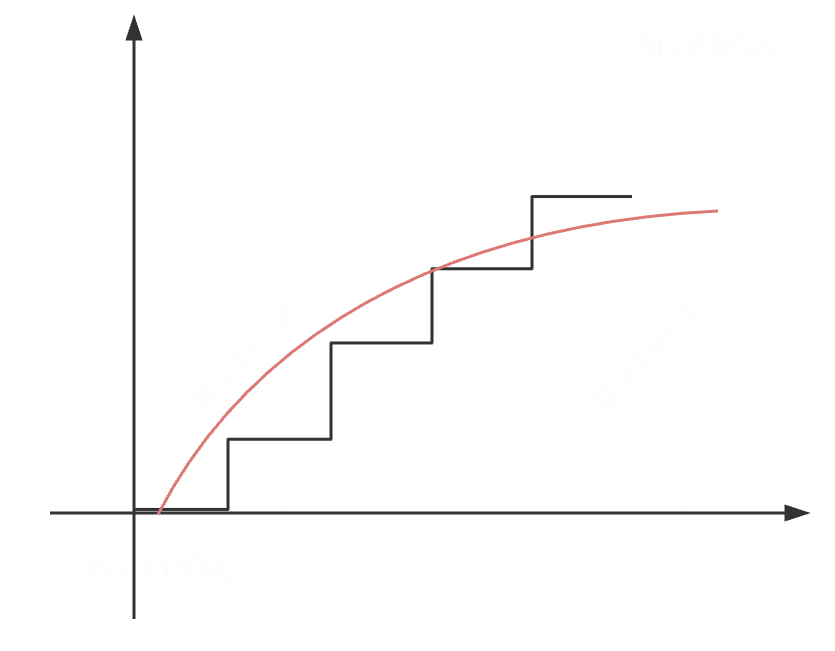
上面的图就是一个形象化的表达树模型和深度模型对物理世界的拟合方式。
拟合效果差
其实比较典型的就是,同等特征下, 不同模型之间拟合效果的差异,甚至有些训练样本中出现过的case,推理的时候都能被推理错, 这些都是说明模型容量不足而做出的取舍。究其原因就是对原始数据不合理的合并(因为拟合能力问题导致的拟合让步),最终导致误差的形成。
模型拟合成本
这里的成本可能会和我们通常理解的有一点儿不一样, 咱们所有的出发点都是提升模型效果,还没有聊到拟合的花费成本的问题呢。
这里可以通过举一个例子说明这个问题,当我们进行多任务(完全共享特征情况下)拟合的时候, 中间会有共享层, 如果我们单独为每个任务都训练一个模型,这样看单任务模型和多任务模型的拟合代价是不一样的。 共享层本身也成为任务之间拟合的成本, 想到与对在任务之间找到找到一个通用的特征表达(决策平面), 进而提升决策效果。 相比原来提升模型效果, 还需要找到一个决策平面,会有一些额外的成本支出。
但是当数据量稀疏的时候,多任务结果的共享表达是能避免过拟合的,这个其实也是你完全怼着目标优化, 过拟合的风险是会增大的。
欠拟合
其实通过上面的例子应该能够理解到, 因为任务之间有约束,会导致单个任务上欠拟合,或者是某些任务拟合好,但是其他任务拟合不好。甚至是任务冲突导致的整体拟合效果下降的问题。
模型训练方式
这个也是一个比较有意思的切入点, 这里举个例子, 例如多任务模型中, 一般我们使用多头加权损失函数进行梯度训练,这种方式无疑是比较简单的,当我我们关注模型整体性能的时候, 还有一种方法是先整体训练,然后冻结共享层以后逐个头进行训练, 这种方式能够一定程度上优化拟合结果。
- 解决了多任务之间的负迁移问题
- 头的拟合更加纯粹,减低拟合成本。
总而言之
大家可能会发现, 咋不同的问题,最终导致的现象是有重叠的呢? 哈哈, 是的,例如特征利用率不足, 是可以通过使用更加复杂的模型解决的。典型的就是一些模型不具备交叉能力,使用复杂模型能够增加这个交叉能力,进而提升模型效果的。 但是复杂模型不全是为了提升特征利用率准备的,例如模型还强在对非线性环境的捕捉上、数据的平滑能力等, 这就是为什么现象上会有重叠,原因上会上是有一些区别的。
最后还是想说一下, 目前的认知程度上, 能够抽象出来以上几个方面的问题, 期望这种结构化的思维,当我们遇到类似的问题能够有层次有方法的进行问题的优化,而不是杂乱无章的尝试。