今天我们来介绍一种比较特殊的网络,孪生神经网络。这也是实现元学习的一种常见的方式。我们先来抛出一个问题,目前市面上人脸识别的应用十分多,那么它们是怎么做到的呢?如果让你来做一个人脸识别的应用,你怎么来实现这个算法呢?第一时间你的的想法是不是老子搞它每个人N多的数据集,然后弄个M分类,这样每次就变成一个图片识别的任务,easy。想想其实也是可以的,但是似乎不太符合实际,哪里弄来这么多的人的样本呢?话说如果新用户注册你要人家上传多少照片呢?所以这个思路是不适合做人脸识别的任务的。这章我们就介绍使用孪生神经网络做人脸识别的案例。
孪生神经网络
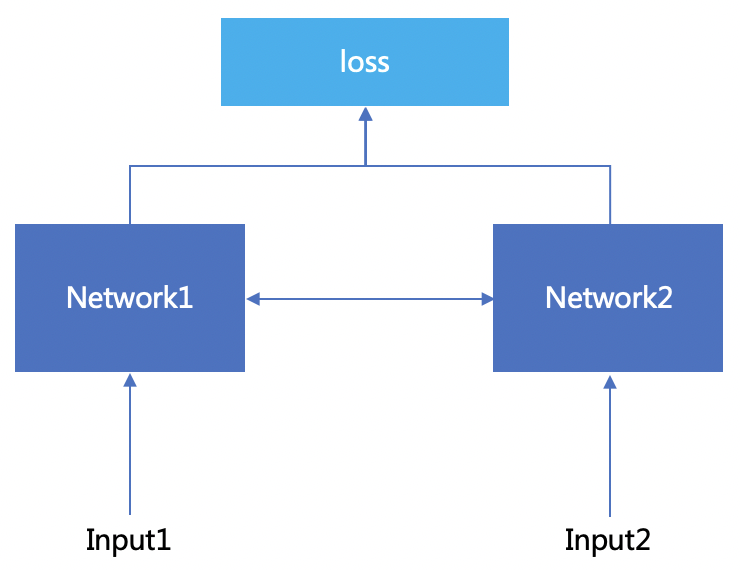
上图是一个伪孪生神经网路的架构图,所谓的“伪”只是这两个network使用的是一个套参数和结构,甚至就用一个神经网络。这个input1和input2就是我们要对比的对象1和对象2.结果就是这两个对象是否是一个对象。
Contrastive Loss
这里我们需要好好介绍一个孪生神经网使用的损失函数,我们来看下面的两个公式。
L(W)=i=1∑PL(W,(Y,X1,X2)i)L(W,(Y,X1,X2)i)=(1−Y)LG(Ew(X1,X2)i)+YLI(Ew(X1,X2)i)
- 其中Y是标签,同类为0,不同类为1
- P为总样本数,i表示当前样本的下标
- LG表示两个样本为同类时的损失函数,LI表示两个样本为不同类时的损失函数
使用Contrastive Loss的任务主要是设计合适的LG和LI的损失函数,当为同类时,使得LG尽可能小;当不同类时,使得LI尽可能大。这里所谓的损失函数实际上使用一种距离的度量就能达到我们的要求,这样我们就通过采集用户几张照片就能够有一个网络对比是否是本的逻辑啦。网络实现如下,下文的实现方式是使用了同一个网络实现孪生的。
class SiameseNetwork(nn.Module):
def __init__(self):
super(SiameseNetwork, self).__init__()
self.cnn1 = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(1, 4, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(4),
nn.ReflectionPad2d(1),
nn.Conv2d(4, 8, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
nn.ReflectionPad2d(1),
nn.Conv2d(8, 8, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
)
self.fc1 = nn.Sequential(
nn.Linear(8*100*100, 500),
nn.ReLU(inplace=True),
nn.Linear(500, 500),
nn.ReLU(inplace=True),
nn.Linear(500, 5))
def forward_once(self, x):
output = self.cnn1(x)
output = output.view(output.size()[0], -1)
output = self.fc1(output)
return output
def forward(self, input1, input2):
output1 = self.forward_once(input1)
output2 = self.forward_once(input2)
return output1, output2
损失函数可以使用pytorch自带的api计算
class ContrastiveLoss(torch.nn.Module):
"""
Contrastive loss function.
"""
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2, keepdim = True)
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +
(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
对于非伪孪生网络只是使用了两个独立的两个网络结构而已。是不是会有人好奇能不能实现三胞胎的网络呢,毕竟国家都提倡三胎了吗。当然是可以的, 所谓的孪生网络一般是使用三个输入,一个正例和两个负例,或者一个负例和两个正例,训练的目标就是让同类距离最小,不同类距离较大就好啦。
总而言之
不知道你读完以后是不是有这样一个想法,这是不是一种度量学习呢? 是的,这其实就是一种度量学习的实现手段,所以我将它放到元学习的领域。通过网络结构的创新实现一种业务场景也是对深度学习的一个提升。
Learning a Similarity Metric Discriminatively, with Application to Face Verification