不知道大家注意了没有,因果推断的假设往往是通过样本去做因果推断,如果样本是随机抽抽取的,那么我们得出的结论也是准确的。而现实的生活中我们的样本往往是自行选择的,带来的影响是我们不能很好的估计它的平均处置效应。这里我可以举一个例子,我们想通过抽取样本来分析智商对大家成绩的影响,所以我们从上大学的样本中抽取了若干样本,但是我们发现有一些智商足够但是没有上大学的样本学校成绩是缺失的。那么这就给这个估计带来一定的影响。本章要解决的就是这样的问题,是不是恶心的要死。
Heckman
我们一般通过Heckman方法来解决此类问题,当然Heckman算法还有一些变种,本章就介绍最基本的Heckman算法,为大家提供解决这样问题的思路。
模型定义
首选模型分为选择方程和结果方程。
结果方程
Yi∗=α+Xiβ+e1i
选择方程
Di∗=Zi′r+e2i
\begin{equation}
\left\{
\begin{array}{ll}
D_{i}=1, if\ D_{i}^{*}>0 \\
D_{i}=0, if\ D_{i}^{*}<=0 \\
\end{array}\right.
\end{equation}
样本中观测结果为
\begin{equation}
\left\{
\begin{array}{ll}
Y_{i}=Y_{i}^{*}, if\ D_{i}=1 \\
Y_{i} 缺失, if\ D_{i}=0 \\
\end{array}\right.
\end{equation}
咱们开始解释变量含义啦,Xi是决定结果的解释变量,e1i表示结果方程的干扰项,e2i样本选择干扰项,Xi和Zi为外生变量,其中Zi包含Xi的所有变量并且至少一个变量不在Xi。
在算法选择模型中,直接假设二者是如下关系。
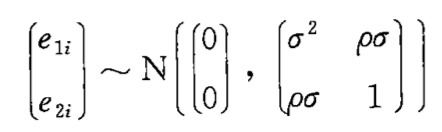
也就是说干扰项满足均值为0的二元正态分布,e1i方差为σ,e2i方差为1,二者相关系数为ρ.
说到这里你可能蒙了,你就给我看这个?太抽象了吧。是的,那咱们来举个例子吧。
对上咱们开头举得那个例子。
结果方程为
score=α+IQβ+e1i
表示IQ与分数的关系。
选择方程为
Utilityi=r0+r1IQi+r2Home+e2i
\begin{equation}
\left\{
\begin{array}{ll}
D_{i}=1, if\ Utility_{i}^{*}>0 \\
D_{i}=0, if\ Utility_{i}^{*}<=0 \\
\end{array}\right.
\end{equation}
上个方程中加入了Home表示家庭教育对是否上大学的影响因素。
这里你可能好奇的是Heckman是如何解决样本选择偏差的呢?感觉没啥关系呀。
那么咱们给给出一些数学推导的过程。
自选择样本观测数据结果的条件期望函数为
E(Yi∣样本,Xi)=E(Yi∣Di=1,Xi)=E(α+Xiβ+e1i∣Zir+e2i>0,Xi)=α+Xiβ+E(e1i∣e2i>−Zir,Xi)=α+Xiβ+E(e1i∣e2i>−Zir)
因为e1i和2i是相关的。所以E(e1i∣e2i>Zir)!=0.如果想要估计出β就要把E(e1i∣e2i>Zir)控制掉,那么就要加入一个新的干扰项。
Yi=α+Xiβ+E(e1i∣e2i>−Zir)+vi
vi就是新的干扰项,增加新的控制项的情况下,E[vi∣样本,Xi]=0.那么问题来啦,E(e1i∣e2i>Zir)是多少呢?其实我们也不必亲自观测到e1i、e2i,因为我之前给出一个假设,二者服从二元正态分布,会有如下关系。
E(e1i∣e2i>Zir)=ρσλ(Zir)=ρσ1−Φ[σ−Zir]ϕ[σ−Zir]
这里的λ称为逆米尔斯比例(IMR)。ϕ表示正态分布概率密度函数,Φ正态分布累积函数。
所以第一阶段,使用Probit模型估计样本选择方程
Pr(Di=1∣Zi)=Pr(e2i>−Zir∣Zi)=Φ(Zir)
这样就得到r的值,然后把r的值,然后把r带入IMR公式,为每个个体计算出IMR。
第二阶段使用样本数据将Yi对Xiβ和λi回归。
Yi=α+Xiβ+ρσλi+vi
从而我们得到了相对一致性的估计。本章我们又解决了因果推断的一个大问题,希望大家不要遇到这样的问题。