iGPT
最近ChatGPT突然间火了起来,其实图像领域也有类似的模型,叫做iGPT。不仅在图像识别还有在图像补全上都起到很好地作用。iGPT包括两个阶段,一个阶段是预训练阶段,一个是微调阶段。
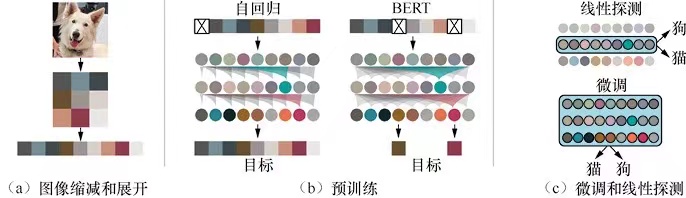
iGPT的核心内容可以通过上图进行概括。
这里需要注意的是NLP中处理的1维的数据,但是图像是一个矩阵数据,当矩阵数据降低维度到1维的时候,会发现Transformer的能力就有力不从心情况发生,所以会有图像的缩放过程,如上图的a过程,当然这里也会存在一个采样的过程。在得到了Transformer能够处理的缩小了分辨率的图像后,便要将图像展开成1维,iGPT采用的是光栅扫描顺序,或者叫做滑窗扫描顺序。
预训练
对于给定的n个无标签图像组成的批次样本x=x1,..,xn,对于其中任意一个图像,iGPT使用自回归模型对其概率密度进行建模。
P(x)=i=1∏np(xπi∣xπ1,...,xπn−1,θ)
其中图像顺序π是单位排列的,也就是按照上面说的光栅排列的,参数θ 是学习的参数。既然是BERT模型,在预训练中,目标是使用未被替换为掩码的像素预测被替换的像素。如上图的b所示。
网络结构
对于输入序列x1,...xn,首先将每个位置的标志变成嵌入向量。iGPT的解码器由L个块组成,对于第l+1个块,它的输入是n个d维嵌入向量h1l,...hnl,输出n个d维嵌入向量h1l+1,...,hnl+1, iGPT的解码块使用的是GPT-2的网络结构
nl=layernorm(hl)al=hl+multiheadattention(nl)hl+1=al+mlp(layernormal(al))
其中layernorm表示归一化,其作用是注意力部分。
在进行Transformer的自注意力的计算的时候,在原生的自注意力的基础上加入了三角掩码,原自注意力的方式为
self−attention(Q,K,V)=softmax(dkQKT)V
其中Q,K,V分别表示输入内容得到的3个不同的特征矩阵,加入上三角掩码的注意计算方式如下
self−attention(Q,K,V)=softmax(mask−attention(dkQKT))V
假设上三角矩阵为b,w=QKT,那么mask-attention计算方式如下
mask−attention(w,b)=wb−α(1−b)
其中α是一个非常小的浮点数。
微调
首先通过序列尺寸上平均池化将每个样本特征nl变成d维特征向量
fL=<niL>
然后将fL之上再添加一个全连接层的分类logits,微调的目的是最小化LCLF.
当同时优化生成损失函数LCLF和分类损失的时候,损失函数为
LGEN+LCLF
其中LGEN是BERT哪些生成过程产生的损失。
上文提到的方式都是将nlp中的方式引入到图像中,但是还有两个比较难的问题没有解决。
- 图像序列巨大,不适合使用Transformer
- 目前使用Transformer都是进行图像分类的任务,理论上利用其解决检测问题也应该是比较容易的,但是对于分割这种密集预测性任务,Transformer并不擅长。
Swin Transformer是为了解决这些问题。这里不展开讲述啦。