本节继续来介绍新的网络结构
SENet网络
SENet的提出动机十分简单。传统的方法将网络的特征图的值直接传递到下一层,而SENet的核心是建模通道之间的依赖关系,通过网络的全局损失函数自适应的重新校正通道之间的特征的相应的强度。
SENet是由一系列的SE块组成,一个SE块包括压缩和激发两个步骤,其中压缩是通过特征图上执行全局平均池化得到当前特征图的全局压缩特征向量,特征图通过两层全连接得到特征图中每个通道的权重,并将加权后的特征图作为下一层网络的输入。从上面的分析可以看出,SE块是依赖当前一组特征图,因此可以容易嵌入几乎所有的CNN中。
SE块

网络的左部分包含一个传统的卷积变换。U是W×H×C特征图,W和H是图像尺寸,C是通道数。
经过fsq(⋅)压缩后,图像变成了一个1×1×C的特征向量,特征向量的值由U确定。经过f(⋅,w)后,特征向量维度不变,但是向量值变成了新的值。这些值会通过和U的fscale(⋅,⋅)得到加权后的X^,X^和U的维度是相同的。
压缩模块
压缩模块的作用是获取特征图U的每个通道的全局特征向量,在SE块中,这一步通过VGG中引入的全局平均池化实现。通过这种方式求每个通道c的特征图的平均值zc实现。
zc=fsq(uc)=W×H1i=1∑Wj=1∑Huc(i,j)
通过上面的方式虽然比较粗糙,但是也能获得一个全局的特征值。
激发模块
激发模块的作用是通过zc中学习c中每个通道的特征值。通道之间的关系是非互斥的,这样就能学习到特征能够激励重要的特征,抑制不重要的特征。SE块使用两层全连接构成的门机制,门控单元s的计算方法如下。
s=fex(z,W)=σ(g(z,W))=σ(W2RELU(W1)z)
其中σ是激活函数。得到门控s后,最后输出X^表示s和U的向量积,就是上图的fscale操作。
x^c=fscale(uc,sc)=sc∗uc
其中x^c是X^的一个特征通道的一个特征图。
- SE块学习了每个特征图的动态先验
- SE块可以看做特征图维度的自注意力,因为注意力机制的本质也是学习一组权重值。
更密: DenseNet
通过之前残差的学习,我们知道残差网络能够应用在特别深的网络中,一个重要的原因是无论正向传播还是反向梯度,信息都能毫无损失的从一层传递到下一层。基于这一思路,一个简单的思想是在网络的每个卷积操作中,都将低层的所有特征作为输入,也就是一个层数为L的网络中加入2L(L+1)个捷径。DenseNet中的一个密集快就如下图。
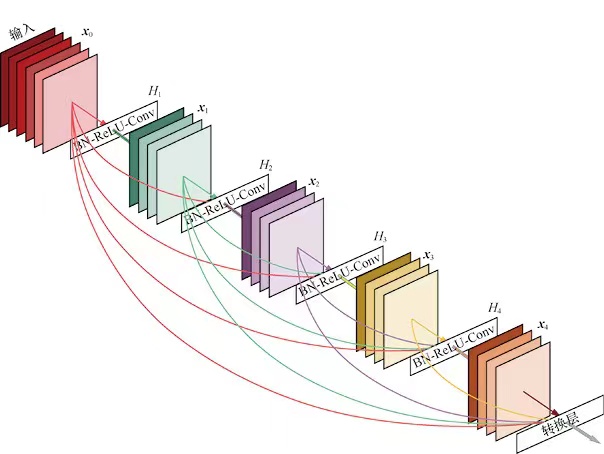
DenseNet是将不同的层的输入拼接在一起,而不是残差网络中的相加。
密集块
在密集块中,第l层的输入xl是这个块中前面所有层的输入拼接的结果。
xl=[y0,...,yl−1]yl=Hl(xl)
其中[]表示拼接操作。H表示合成函数。
一个完成的密集块应用如下。

合成函数
合成函数位于密集块的每一个节点中,其输入时拼接在一起的特征图,输出则是这些特征图经过BN→Relu→3×3卷积得到的结果,其中卷积的特征图的数量被定义成成长率k。 在DenseNet中k一般是比较小的整数,当然这个拼接起来的特征图一般是比较大的,所以也会先使用1×1卷积将输入的数据降维,再使用3×3卷积提取特征。
成长率
成长率是DenseNet中的一个超参数,反应的是密集块中每个节点输入数据的增长速度。在密集块中,每个节点的输入均是一个k维度的特征向量。
压缩块
密集块之间的结构叫做压缩块,压缩层有降维和降采样的两个作用。假设密集块的输出为m维的特征向量,那么下一个密集块的输入就是θm,其中θ是压缩因子,是一个用户的超参数,当θ=1的时候,密集块的输入和输出维度相同。
DenseNet网络的特点如下
- 信息流通更加顺畅
- 支持特征重用
- 网络更加窄
DPN
这里顺带介绍一下DPN网络,之前介绍了残差网络和DenSeNet网络,一个是通过相加的方式直接将输入加到输出上, DenseNet是通过特征拼接的方式。而DPN通过高阶的RNN将残差网络和DenseNet进行结合。当然主要的结论是,残差网络更侧重于特征的复用,而DenseNet侧重于特征的生成,组合起来就拥有两个模型的优点,当然这里就不展开介绍。