本章节继续结合一些常见的业务问题介绍一些多任务模型。
问题起点
负迁移(egative transfer):推荐系统中的任务通常是低相关甚至是相互冲突的,联合训练可能导致性能下降,称之为负迁移。简单点说负迁移是指多任务学习的效果不如单独训练各个任务的效果,共同训练模型导致任务的效果下降。
跷跷板现象:任务相关性复杂且依赖于样本时,现有的MTL模型往往会以牺牲其他任务的性能为代价来改进某些任务。下图为文中的实验结果,除PLE外,其余MTL模型往往只能在某个任务上优于单任务模型。
多任务模型对比
知道了多任务模型经常会遇到这样的问题, 那么现在有的一些模型架构都具有什么样的特点呢?我们来看下面这个图
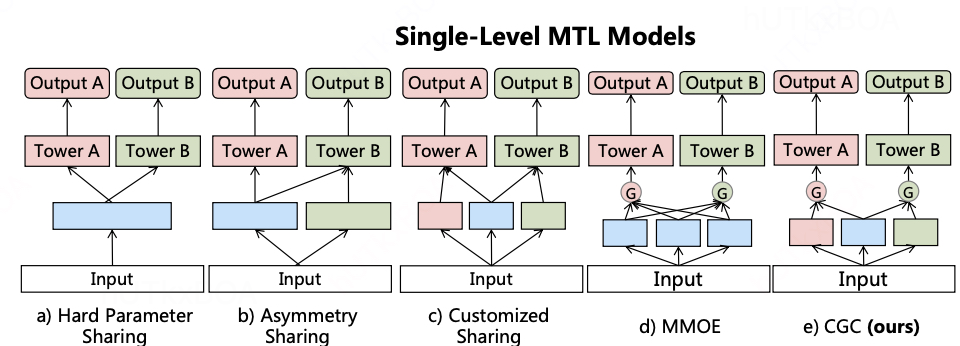
上图描述了各种各样的任务模型架构,每个都有自己的特点。
Hard Parameter Sharing
Hard Parameter Sharing:最常见的MTL模型,不同任务底层的模块是共享的,然后共享层的输出分别输入到不同任务的独有模块中,得到各自的输出。当任务相关性较高时,用这种结构往往可以取得不错的效果,但任务相关性不高时,会存在负迁移现象,导致效果不理想。
Asymmetry Sharing(不对称共享)
用于捕捉任务之间的不对称关系。底层在任务之间不对称共享,共享哪个任务的表示取决于任务之间的关系。常见的融合操作,如拼接、求和池化和平均池化,可以用于组合不同任务底层的输出。
Customized Sharing(自定义共享)
明确地将共享参数和任务特定参数分开,以避免固有的冲突和负面转移。与单一任务模型相比,自定义共享增加了共享底层来提取共享信息,并将共享底层和任务特定层的级联提供给相应任务的塔层。
MMoE
底层包含多个共享专家模块,然后基于门控机制,不同任务会对不同专家模块的输出进行加权。
所以说MMoE是一种模型框架,而这个框架的关键点是门控设计,也就是如何选取合适的专家参与计算,以下介绍一些门控策略的设计和使用。
定制门控网络 (Customized Gate Control, CGC)
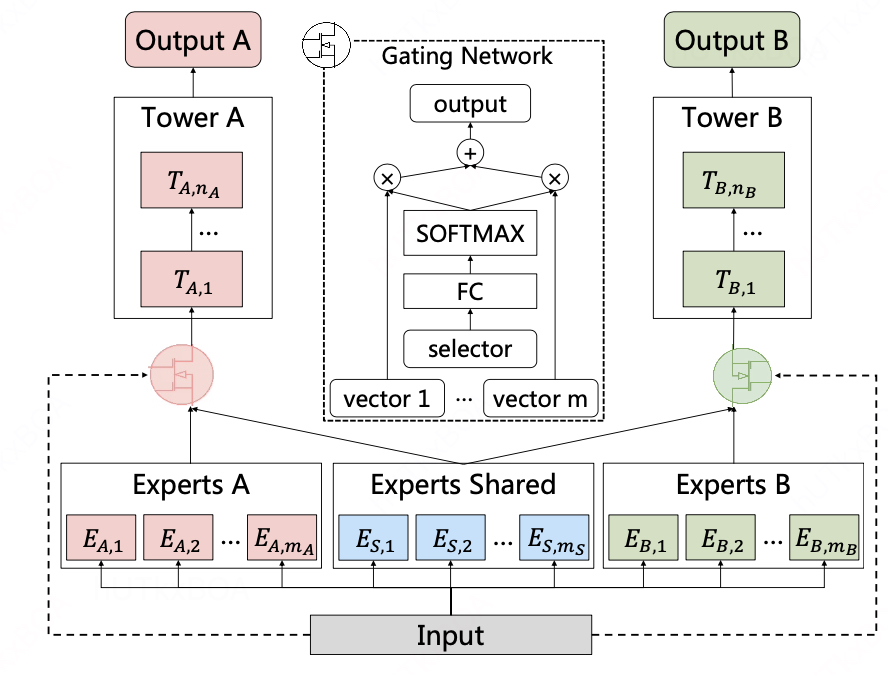
上图是一个CGC模型结构,咱们来看其中一些细节模块。
底层网络:包含一些 expert 模块, 每个expert 模块由若干子网络(sub-networks)构成,这些子网络称作 experts,每个模块包含多少个 expert 是可调节的超参。其中 shared experts 负责学习 shared patterns,task-specific experts负责学习task-specific patterns。
上层网络:一些 task-specific 塔 ,网络的宽度和深度都是可调节的超参。每个塔同时从 shared experts 和各自的task-specific experts 中学习知识。
门控网络:Shared experts 和 task-specific experts 的信息通过门控网络进行融合。门控网络的结构为单层的前向网络,激活函数为softmax 函数。
对比 MMoE,CGC 去掉了子任务塔和其他 task-specific experts 的连接,这就使得不同类型 experts 可以专注于更高效地学习不同的知识且避免不必要的交互。另外,得益于门控网络动态地融合输入,CGC可以更灵活地在不同子任务之间找到平衡且更好地处理任务之间的冲突和样本相关性问题
PLE是CGC的一个多层拓展,还利用了一个新颖的 progressive seperation routing 机制。
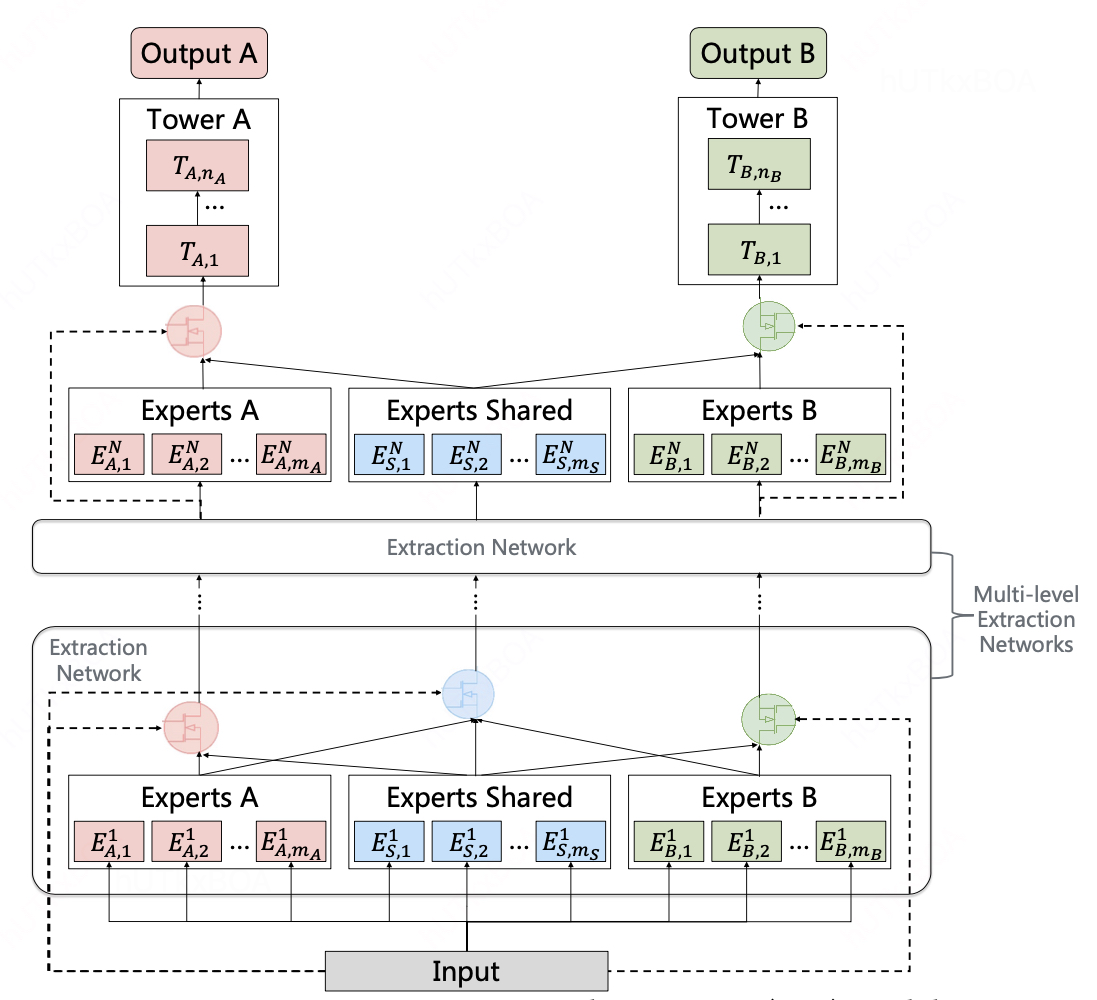
这里有个一个很有意思的点,对于多层CGC的一个堆叠,我们可以设想成当我们学习一个东西的时候, 开始是不知道学习什么的,随着事情进展的更加深入,我们开始对special和common有了新的认知,从而完善我们的学习关系。这就是PLE的设想,所以进行了多层CGC的堆叠。