Stable Diffusion 的发布可以说 AI 图像生成发展过程中的一个重要里程碑,它不仅可以生成高质量的图像,根据提示词生成图像、修改图像,而且运行速度快,所用资源较少。
Stable Diffusion 模型的直观理解
朴素的 DDPM 每一步都在对图像进行加噪、去噪操作。而在 Stable Diffusion 模型中,可以理解为对图像进行编码后的图标记(image token)进行加噪、去噪。在去噪(生成)的过程中,加入了文本特征信息来引导图像生成。这部分功能很好理解,与 VAE 中的条件VAE 和 GAN 中的条件 GAN 原理是一样的,通过加入辅助信息,生成需要的图像。
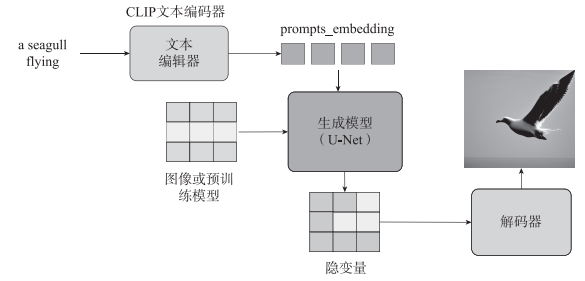
Stable Diffusion 模型要根据提示词画图,需要实现以下功能:
1)理解提示词。
2)根据提示词在预训练模型中找到匹配度高的图像。
3)生成这个匹配高的图像。
Stable Diffusion 模型的原理
在 Stable Diffusion 模型中,CLIP 的嵌入向量可以用于表示图像和文本的语义信息,
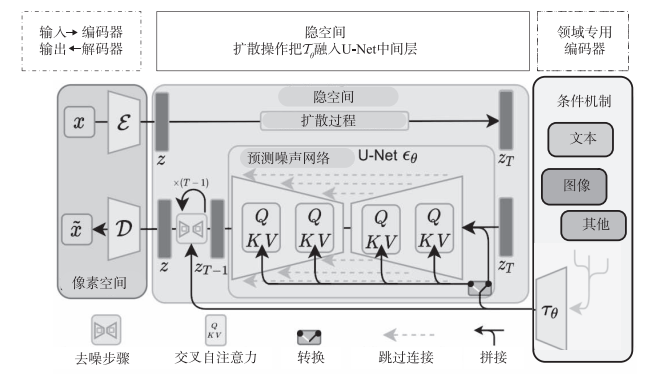
Stable Diffusion 的数据会在像素空间(Pixel Space)、隐空间(Latent Space)、条件机制(Conditioning Mechanism)三者之间流转,其算法逻辑大概分这几步:
1)图像编码器将图像从像素空间压缩到更小维度的隐空间,捕捉图像更本质的信息;
2)为隐空间中的图片添加噪声,进行扩散过程(Diffusion Process);
3)通过 CLIP 文本编码器将输入的描述转换为去噪过程的条件机制;
4)基于一些条件对图像进行去噪(Denoising)以获得生成图片的潜在表示,去噪步骤可以灵活地以文本、图像和其他形式为条件(以文本为条件即 text2img,以图像为条件即 img2img)
5)图像解码器通过将图像从隐空间转换回像素空间来生成最终图像。
首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器ϵ和一个解码器D),接着利用编码器对图片进行压缩,把压缩后的向量作为隐空间的输入 z,在隐表示空间上进行扩散操作,得到zT然后进入反向扩散过程,即去噪声过程。去噪声的关键是通过 U-Net预测噪声ϵθ可以进行无条件图片生成,也可以进行条件图片生成,这主要是通过拓展得到一个条件时序去噪自编码器(conditional denoising autoencoder)ϵθ(zt,t,y)来实现的,这样就可通过 y 来控制图像的合成过程。
上图中右边为领域专用编码器(Domain Specific Encoder)Tθ,它用来将 y 映射为一个中间表示Tθ(y)这样就可以很方便地引入各种形态的条件(如文本、类别、图像等等),进而从多个不同的模态预处理 y。最终模型就可以通过一个交叉自注意力层将控制信息融入U-Net 的中间层。交叉自注意力层的实现如下:
Attention(Q,K,V)=softmaxdQKTV
其中Q=WQiφt(zt),K=WKiTθ(y),V=WViTθ(y),φt(zt)是 U-Net 的一个中间表征。对应的目标函数为
Eϵ(x),y,ϵ∼N(0,1),t=∣ϵ−ϵθ(zt,t,Tθ(y))∣2
最后再用解码器将输出恢复到原始像素空间即可。常规的扩散模型是基于像素空间的生成模型,而 Stable Diffusion 是基于隐空间的生成模型,它先采用自编码器的编码器将图像压缩到隐空间,然后用扩散模型来生成图像的隐向量,最后送入自编码器的编码器模块生成图像。
Stable Diffusion 2.0
相较于 Stable Diffusion 1.0,Stable Diffusion 2.0 有以下更新:
1)采用了新的文本编码器 OpenCLIP,有助于提高生成的图像的质量。
2) 默 认 支 持 768×768 像 素 和 512×512 像 素 两 种 分 辨 率, 此 前 默 认 分 辨 率 仅 为
512×512 像素。
3)分辨率放大,Stable Diffusion 2.0 的放大扩散模型可以将图像分辨率提升至原来的16 倍.
4)利用深度信息生成图像。新增深度信息生成图像模块 depth2img,新增的一些特性带来了更多玩法,比如 depth2img 可以对输入图像的深度信息进行推理,然后,用文本和深度信息来共同生成新的图像。
5)图像修改功能增强。Stable Diffusion 2.0 进行了一些微调,使得修图更快速也更智能。
Stable Diffusion XL
比起Stable Diffusion 2.0,Stable Diffusion XL 做了很多优化,
1)对 Stable Diffusion 原先的 U-Net、VAE、CLIP Text Encoder 三大件都做了改进。
2)增加一个单独的基于 Latent 的 Refiner 模型,来提升图像的精细化程度。
3)设计了很多训练技巧,包括图像尺寸条件化策略、图像裁剪参数条件化以及多尺度训练等。
4)增加数据集和使用了 RLHF 技术。
5)架构上做了很多修改
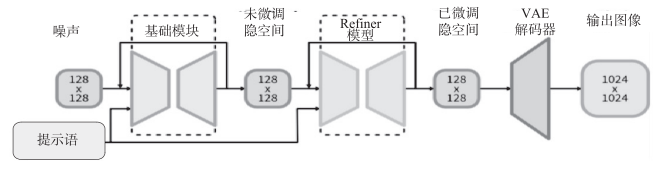
Stable Diffusion XL 的参数量增加到了 66 亿,其中 Base 模型 35 亿,Refiner 模型 31亿。Stable Diffusion XL 使用更多训练集和 RLHF 来优化生成图像的色彩、对比度、光线及阴影,使得生成的图像更加鲜明准确。