今天我们来介绍大语言模型使用,Agent的构建和开发。
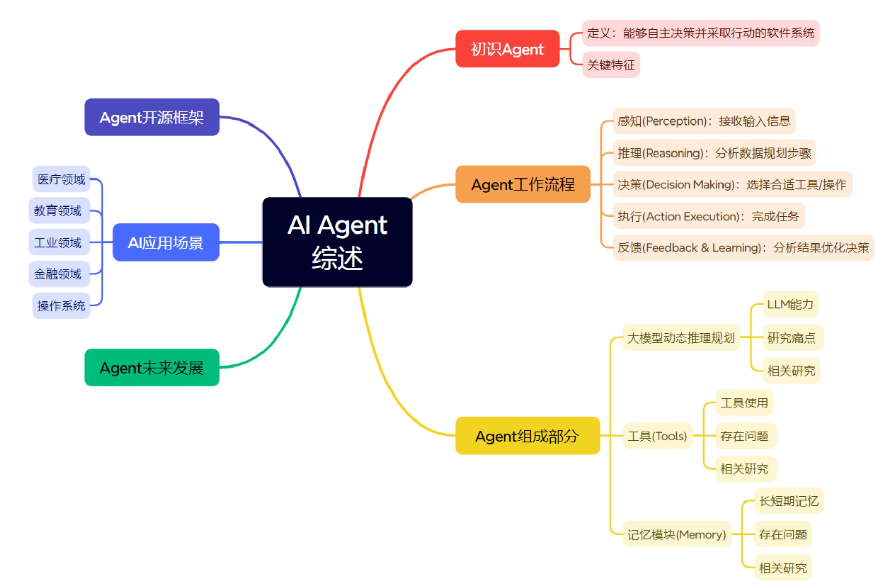
基础知识
Agent定义和核心机制
Agent是一种通过感知环境(传感器)并主动与环境交互(执行器)的智能实体。LLM Agent通过结合大语言模型(LLM)与外部工具、内存和规划能力,突破传统LLM的对话局限,实现复杂任务拆解与执行。其核心是通过工具调用(如API、代码)弥补LLM在数学计算、事实检索等方面的短板,形成“指令-目标-决定-执行”的闭环。
内存管理
- 短期记忆:利用LLM的上下文窗口(通常数千令牌)直接存储近期对话历史,或通过小模型实时摘要对话。
- 长期记忆:将历史交互嵌入向量数据库(如RAG),支持跨会话信息检索。需区分语义记忆(事实性知识)与工作记忆(当前任务上下文),避免信息过载。
工具调用和标准化
Agent通过生成JSON或代码调用工具(如计算器、搜索引擎等),关键挑战在于工具使用的稳定性。技术如Toolformer通过微调LLM学习工具调用格式,而MCP协议标准化API访问(如GitHub、天气服务),降低多工具集成复杂度。这里的重点是需要避免手动维护工具链,确保框架的可扩展性。
规划与决策:推理与行动循环
- 推理能力:通过Chain-of-Thought(思维链)或ReAct(行动―反思循环)引导LLM分解任务,例如将“订机票”拆解为“查航班―比价―支付”。
- 自主优化:Reflexion技术引入“Actor-Evaluator-Self-Reflection”三重角色,利用强化学习从失败中迭代策略,提升长期任务成功率。
多代理协作与动态交互
复杂任务通常需要多Agent协同,例如生成式代理(Generative Agent)通过配置文件定义角色(如专家Agent与协调Agent),共享内存并动态分配子任务。模块化框架(如AutoGen、CAMEL)支持角色间通信,但需要注意避免过度协调导致的效率下降。
一些工具
调用浏览器工具(GUI Agent)
python -m pip install --user pipx
python -m pipx ensurepath
pipx install uv
pip install browser-use
browser-use的核心功能是通过LLM的推理能力分析浏览器页面的HTML内容和文本信息,输出可执行的指令,交给浏览器自动化工具(Playwright)执行。
pip install playwright
playwright install
这时候Playwright会安装Chromium、Firefox和WebKit浏览器并配置一些驱动,我们不必关心中间配置的过程,Playwright会为我们配置好。安装完成之后,我们便可以使用Playwright启动Chromium或Firefox或WebKit浏览器来进行自动化操作了。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
for browser_type in [p.chromium]:
browser = browser_type.launch(headless=False)
page = browser.new_page()
page.goto('https://www.baidu.com')
page.screenshot(path=f"yrdy.png")
print(page.title())
browser.close()
Function Calling
大模型的工具调用(Function Calling)功能,作为人工智能领域的一项关键技术,赋予了大模型与外部世界进行交互和协作的能力。在这一领域,DeepSeek所实现的工具调用机制,以其高效、灵活的特点,成为众多开发者和研究者关注的焦点。它不仅能够让模型根据需求精准地调用各类外部工具,还极大地拓展了模型的应用场景并增加了其实用价值。这里我们介绍DeepSeek自带的Function Calling功能。
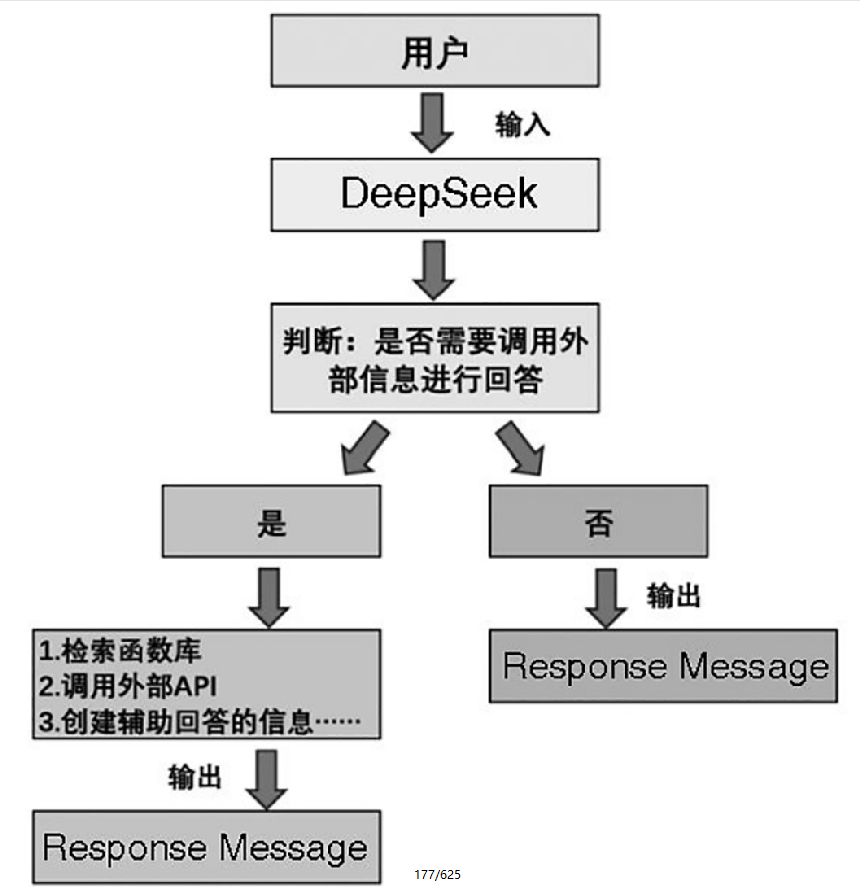
我们这里给一个简单的例子
# Please install OpenAI SDK first: `pip3 install openai`
import json
from openai import OpenAI
client = OpenAI(
api_key='sk-xxxx',
base_url="https://api.deepseek.com")
def get_weather(params):
return f"{params[0]}是晴朗"
# 定义工具类
tools = [
{
"type":"function",
"function":{
"name":"get_weather",
"description":"获取城市天气信息",
"parameters":{
"type":"object",
"properties": {
"location":{
"type":"string",
"description":"城市名称。例如上海",
}
},
"required":["location"],
},
},
}
]
# 调用函数
def send_message_tools(messages):
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools,
tool_choice="auto",
)
return response.choices[0].message
system_prompt="""
你是一个智能助手,能够通过思考和工具调用和响应处理用户问题。
思考阶段:分析用户需求,判断是否通过调用工具获取
工具调用阶段:根据思考的结果,选择合适的工具生成调用请求,调用方式符合定义
响应阶段:根据工具调用的结果生成用户最终答案
示例:
用户问题天津天气怎么样?
思考:调用工具查询天气状况
工具调用
{"function_name":"get_weather",
"function_params":{"location":"天津"}
}
工具调用结果:天津天气晴朗,
最终回答:天津天气晴朗
"""
question="上海天气怎么样"
# question="今天股票大盘怎么样?"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": question},
]
message = send_message_tools(messages)
tool_call = message.tool_calls[0]
function_name = tool_call.function.name
function_params=json.loads(tool_call.function.arguments)
print(function_name, function_params)
if function_name == "get_weather":
result=get_weather([function_params["location"]])
else:
result="未知工具"
print(result)
MCP
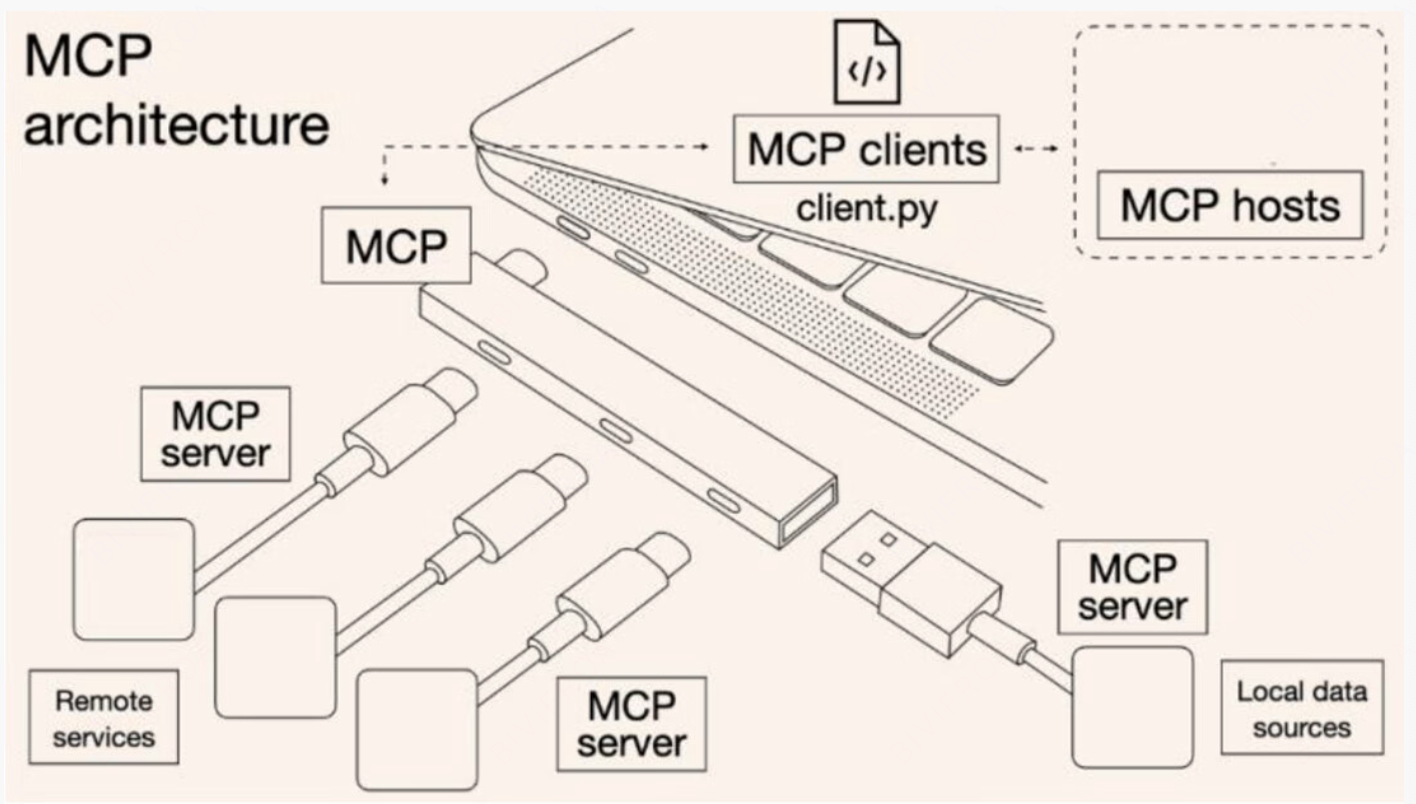
MCP(Model Context Protocol,模型上下文协议),作为一种具有开创性的开放协议,其核心目标在于标准化人工智能模型与外部数据源、工具之间的交互方式。在当今复杂多变的人工智能应用环境中,模型需要与各种不同类型的数据源和工具进行交互,以实现更加智能、高效的任务处理。MCP通过定义一套统一的通信规范,成功打破了模型与外部系统之间的壁垒,使得大语言模型(LLM)能够轻松、无缝地连接本地文件、数据库、API以及各类专业工具。这一协议的出现,为人工智能模型的集成和应用提供了更加便捷、高效的解决方案。
MCP由Host, Client以及Server三大部分组成,相比Function Call 碎片化的特点, 不同的AI应用采用不同的调用方式,需要工作人员不断重新学习和适应,极大的提升了开发成本。
MCP HOST: 作为发起请求的AI应用,它是整个交流流程的指挥官。如果DeepSeek等。
MCP Client : 它是运行在Host之中的, 当Host发起请求的时候,MCP会将请求统一格式化。
MCP Server: 作为轻量级的中间件, 是链接本地和远程资源的桥梁。
MCP具有动态发现机制, 这一特性具有类似即插即用的硬件生态优势,能够自动识别新接入的服务器功能, 无需修改模型代码就可以扩展功能和可能性。
MCP SERVER
from mcp.server import FastMCP
mcp = FastMCP("demo server")
@mcp.tool()
def add_numbers(a:int, b:int)->int:
"""
两个参数的之和
Args:
a(int):第一个整数,例如 3
b(int):第二个整数,例如 5
Returns
int: 两数之和 例如8
"""
return a+b
@mcp.tool()
def multiply_numbers(a:int, b:int)->int:
"""
两个数字乘积
Args:
a(int):第一个整数
b(int):第二个整数
Returns
int: 两数之乘积
"""
return a*b
if __name__ == '__main__':
mcp.run(transport="stdio") # 使用标准输入输出
MCP Client
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
import sys, os, json
import asyncio
from openai import OpenAI
def transform_json(tools):
s = "MCP服务器提供以下工具:\n"
for tool in tools:
s = s + f"""
工具名称: {tool.name}
工具描述: {tool.description}
参数定义: {json.dumps(tool.inputSchema, ensure_ascii=False, indent=2)}
"""
return s
def ask_llm_query(question, tools_description):
"""让LLM决定调用哪个工具"""
system_prompt = f"""你是一个工具调用助手。
{tools_description}
根据用户的问题,选择最合适的工具并生成调用参数。
请严格按照以下JSON格式输出,不要添加任何其他文字:
{{"tool_name": "工具名称", "tool_input": {{"参数名": 参数值}}}}
注意:
1. tool_name必须是上面列出的工具名称之一
2. tool_input中的参数名必须与工具定义中的参数名完全一致
3. 只输出JSON,不要包含其他说明文字
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": question},
]
client = OpenAI(
api_key='sk-xxxxx',
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
max_tokens=1024,
temperature=0.1, # 降低温度,让输出更确定
)
generate_text = response.choices[0].message.content
return generate_text, client
def llm_deepseek(question, client):
"""调用LLM生成最终回答"""
response = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": question}],
max_tokens=1024,
temperature=0.7,
)
generate_text = response.choices[0].message.content
return generate_text
async def run(question="你是谁"):
server_script_path = os.path.join(os.path.dirname(__file__), "MCP_Server.py")
server_params = StdioServerParameters(
command="python3",
args=[server_script_path],
env=None
)
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
# 获取工具列表
tools = await session.list_tools()
print("可用工具:", [tool.name for tool in tools.tools])
# 构建工具描述
tools_description = transform_json(tools.tools)
# 让LLM决定调用哪个工具
response_text, client = ask_llm_query(question, tools_description)
print("LLM返回的JSON:", response_text)
# 解析JSON
try:
# 清理可能的多余字符
response_text = response_text.strip()
# 移除可能的markdown代码块标记
if response_text.startswith("```json"):
response_text = response_text[7:]
if response_text.startswith("```"):
response_text = response_text[3:]
if response_text.endswith("```"):
response_text = response_text[:-3]
tool_call = json.loads(response_text)
tool_name = tool_call['tool_name']
tool_input = tool_call['tool_input']
print(f"调用工具: {tool_name}, 参数: {tool_input}")
# 调用工具
result = await session.call_tool(tool_name, tool_input)
print("工具返回结果:", result.content)
# 处理工具返回结果
if result.content:
tool_result = result.content[0].text
# 构建最终回答
final_question = f"""用户问题: {question}
工具执行结果: {tool_result}
请根据工具执行结果回答用户的问题。"""
final_answer = llm_deepseek(final_question, client)
print("\n最终回答:", final_answer)
return final_answer
else:
print("工具执行失败")
return "工具执行失败"
except json.JSONDecodeError as e:
print(f"JSON解析失败: {e}")
print(f"原始返回: {response_text}")
return f"工具调用解析失败: {response_text}"
except Exception as e:
print(f"执行失败: {e}")
return f"执行失败: {e}"
if __name__ == '__main__':
questions = ["计算一下356+124是多少", "如何计算乘法"]
for question in questions:
asyncio.run(run(question))