本节咱们换个角度来讲Transformer模型,在上一个文章中,主要以计算的过程介绍模型的运行过程,本章中直接对着模型来进行进一步的讲解。
通过上文的介绍,知道Transformer模型架构主要分为了编码器和解码器,那么对于模型架构来讲,咱们还是以这两部分分开讲解。
编码器
在编码器部分主要有两部分组成,一个是多头注意力层,一个是前馈神经网络,并采用残差机制和层归一化的方式链接。
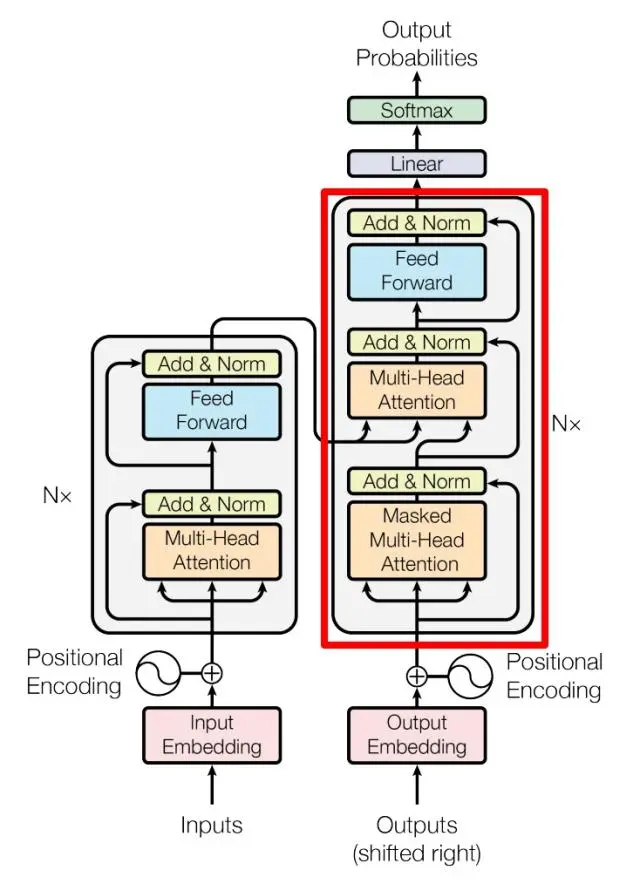
如上图的左侧部分。
下图是缩放点积注意力层,是多头注意力层的一个子模块。
有了上面这些经典的图,咱们开始介绍Transformer的模型。
对于编码器来讲,输入是一句话的word2vec的结果,经过一个位置编码模块,因为Transformer模型不能像LSTM这类循环神经网络一样,对位置信息是敏感的,所以为了让模型具有解决序列内容的学习能力,加入的一个改进。编码方式可以看自然语言处理之Transformer精讲(一)中的位置信息一节。
多头注意力层
顺着图“Transformer”继续往上看, 到了一个多头注意力神经元, 进入到下图中。
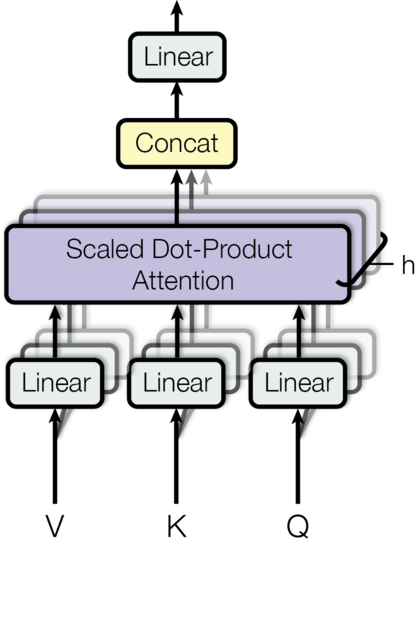
多头注意力层是所由多个缩放点积注意力层组成。这种注意力机制可以理解为将Q、K、V映射到高维空间。
MultiHead(Q,K,V)=concat(head1,head2,..,headn)W
缩放点积注意力层
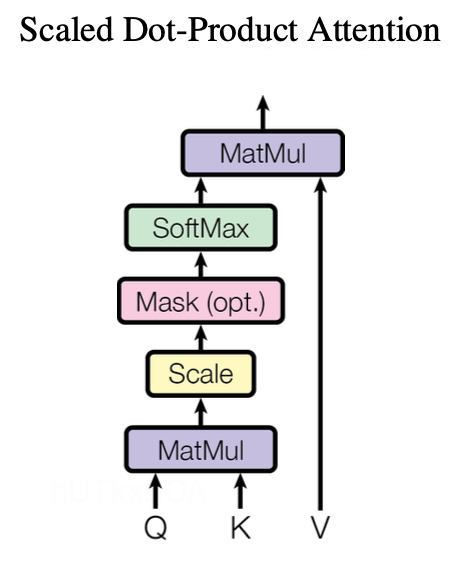
对于缩放点积注意力层来讲,将Q和K进行相乘,在进行大小为dk的缩放,其中dk表示Q和K的维度大小。在经过归一化后,再与V进行相乘获得最终的输出。
Attention(Q,K,V)=softmax(dkQKT)V
Q和K相乘运算得到的向量中,不同的值方差会变大,也就是值之间的大小差距会变大。如果直接进行归一化,会导致值更大,小的值更小,因此要进行参数缩放,使得间距更小,获得更好的训练效果。
这里可以进一步看一个问题, 这里为什么缩放的时候使用dk呢, 有两个原因,一个原因是避免相乘以后得结果过大或者过小,导致softmax的时候梯度消失或者爆炸, 进一步解释,假如Q和K都是均值为0,方差为1的分布,那么这个乘法以后的分布就变成了均值为0, 方差为dk的分布,这个dk就是维度的累积,如果dk很大,相乘的结果差异很大,经过softmax就变成类似独热编码的样式, 这样极小的值就接近于0,信息损失严重,如果dk很小,那么经过softmax以后就变成类似均匀分布的样子,容易导致Transformer最后一次的softmax的预测结果也是均匀的,进而导致梯度很大,造成梯度爆炸。所以会选择dk进行缩放。
下面一个问题解释一下,为什么均匀分布会导致梯度爆炸,我们来看下交叉熵的公式
L=−i=1∑Cyilog2zi
yi表示第i个类别的概率, zi是预测第i个类别的概率,C表示总类别,如果预测分布接近真实分布,那么zi=C1,损失函数就变成了
L=−i=1∑Cyilog2C1=log2C+i=1∑Cyi=log2C
可以看到,损失函数的值和类别C有关,如果C很大,损失函数就很大,这样就导致了梯度爆炸。
接下来说第二个原因是能让模型适应不同维度的输入,如果不除以dk,那么模型在训练的时候就会对输入的维度产生依赖性,如果测试阶段输入维度发生变化,那么模型可能会性能下降。所以这个维度dk能够保证模型输入的鲁棒性。
通过上面的网络结构可以看到使用了很多的LayerNorm进行归一化,原因是LayerNorm不受训练批次大小的影响,并且能很好的应用到时序数据中,不需要额外的空间。
加法和归一化操作是结合了残差连接和归一化的技术,这种方式能够防止网络退化。
AddNorm(X)=LayerNorm(X+Sublayer(X))
解码器
解码器是由6个部分组成,除了正常的多头感知层,还加入了三角掩码矩阵,防止模型训练的时候出现信息泄露的问题。
除此以外,在解码器没有更多的区别。
此外不管是编码器还是解码都加入了位置编码层,这一层的主要原因是因为注意力机制的网络如CNN一样,对位置是不敏感的,无法表示时序性,所以特意增加了位置的编码进行区分位置的信息。
通过完整的模型示意图也能够看的出来,不同的多头注意力层的Q、K、V来源是不一样的,例如输入和输出的Q、K、V都是通过全连接学习而来的,但是解码器的第二个多头注意力层Q、K、V的Q是由输入经过全连接变换得来的,K、V是编码器的输出。
通过上图不知道大家是否能明白, 一个编码和解码结构,怎么解码器还有多个输入,其实解码器的输入包含两个部分,一部分是目标序列,就是编码器的输出,例如翻译 I am a student , 编码器先把这个语句进行编码,获得编码矩阵C,然后这个矩阵C进入解码器,解码器开始一个单词一个单词的解码,解码器的目标序列是,带着矩阵C预测I的概率。然后目标序列变成了 I,预测am的概率。
需要进一步说明的是从上图能够看到,编码器的输出C会进入到解码器的多头注意力网络, 这个过程并不是直接进入,而是通过中间的W,将C转换成K和V的形式和上层网络进行多头注意力学习。
当然Transformer也不是完美的,例如Transformer的自注意力层的计算量为O(L2),L是序列长度,复杂的极大。
另一方因为Transformer获取内容位置信息的方式全部来源于位置信息编码,Transformer的参数量巨大,在不依赖预训练的情况下,小规模数据效果不一定有LSTM效果好,后续也会介绍一些Transformer的变种网络。