之前咱们介绍的都是单一模型的预训练方法,这里介绍一个特殊一点的思路,且不说应用程度怎么样,先看看这个模型的设计思路。
ELECTRA
ELECTRA是使用对抗网路的思路进行预训练的方式。
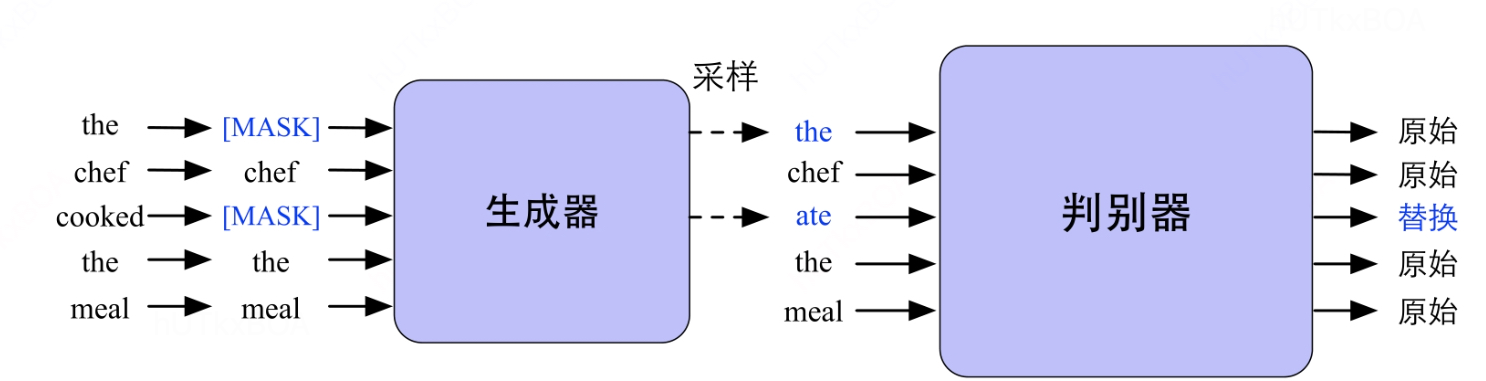
其中生成器,一个小的MLM,就是在[MASK]的位置预测原来的词。
判别器判断的是输入句子中的每个词是否被替换,需要注意的是这里没有下一句的预测任务。接下来我们来看每个模块。
生成器
对于生成器来说,其目的是将带有掩码的输入文本经过多层的Transformer学习到上下文的因变量H, 并还原掩码的位置中的MLM。这里只是预测经过掩码的词,对于某个掩码的位置t,生成器的输入对原文的xt的概率为PG∈R∣V∣,其中V是词表大小。PG(xt∣x)=Softmax(htGWe), 其中We∈R∣V∣×d, 表示词向量矩阵,h表示原文本对应的隐向量表示。这里可以举一个例子,对于原始的输入x=“the chef cooked the meal”。 输入模型为x‘=“[MASK] chef [MASK] the meal”,位置下标为1和3, 最后通过生成器改写后的句子不包含[MASK]的值,然后通过判别器进行判别。
判别器
收到MLM的准确率影响, 通过生成器的采样后句子与原始句子一定是有差别的,判别器就是从采样后的句子中识别那些单词和原始的单词是一致的,就是替换词检测问题,可以通过二分类实现。这里的句子是xs,经过Transformer模型得到对应的隐层hD, 随后,通过一个全连接层映射成一个概率分布,并产生损失梯度传播,从而学习一个很好的判别器。
温馨提示
因为生成器和判别器中间的部分涉及到一个采样,所以判别器并不会直接回传到生成器,因为采样是不可导的。另外,当训练结束后,只需要将判别器进行下游任务的精调,不会再用生成器。
长文本处理
以自注意力的核心Transformer模型进行各个预训练的组成部分,自注意力能够构建序列中各个元素之间的上下文关系,挖掘层次的语义信息,然后自注意力的时空复杂度是O(n2),就是时间和空间消耗会随着序列的增长层平方级别成长,这会导致预训练的处理长文本效率低下。传统的处理长文本一般是切分输入文本,其中每份大小设置为预训练模型单次处理的最大长度,最终进行拼接,这种方式显然也不能从根本性解决这个问题。接下来介绍一个模型解决这个问题。
Transformer中处理长文本的的方式是切分成固定的块,单独编码每一块,但是块与块之间没有信息交互。

容易看出训练阶段和测试阶段存在明显的不匹配的形式。为了优化对长文本的建模,Transformer-XL提出两种改进策略,分别是状态复用的块级别循环和相对位置编码的策略。
状态复用的块级别循环
假设连续的长度为n的块为sT,sT+1, 第T块的第l层Transformer隐层的输出为htl∈Rn×d,d为隐层的维度,计算第T+1块在第l层的Transformer隐层输出为ht+1l.。会有如下的推导过程。
ht+1l−1^=[SG(htl−1)∙ht+1l−1]qt+1l=ht+1l−1Wqkt+1l=ht+1l−1^Wkvt+1l=ht+1l−1^Wvht+1l=Transformer−Block(qt+1l,kt+1l,vt+1l)
其中SG表示停止梯度传播,∙表示长维度进行拼接,W表示权重,与传统的Transformer不同是键k和值v依赖拓展上下文的h,以及上一个块的缓存信息。这种状态复用的块级别循环应用于语料库中每个连续的片段,本质是隐层状态产生一个片段级别的循环。这种机制下Transformer利用有效的上下文信息可以超过两个块。ht+1l,ht+1l−1之间的训练依赖使得存在向下一层的计算依赖,这与传统的RNN中的同层训练机制是不同的,因此最大可能得依赖长度随块的长度n和层数l增长。通过这个方式就是实现了块之间的信息互通。
相对位置编码
虽然状态复用的块级别循环将不同的块之间的信息联系起来,实际应用中无法区分块的位置信息。为了解决这个问题,应用相对的位置编码后,第i个词和第j个词的注意力aij为。
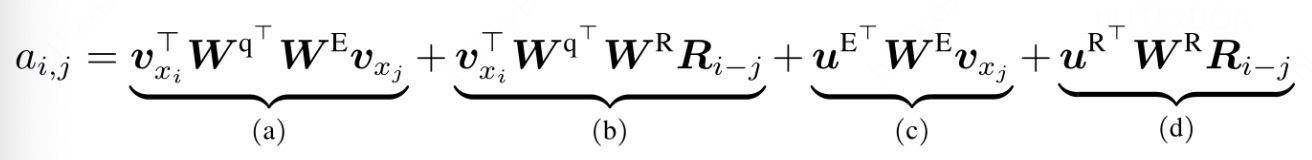
w表示权重,vxi表示xi对应的词向量,R表示相对位置矩阵,是衣蛾不可训练的正弦编码矩阵,其第i行表示相对位置间隔为i的位置向量。
- a计算xi和xj的内容之间的关联信息
- b计算查询xi和键xj的位置编码矩阵的关联信息,Ri−j表示两者的相对位置信息
- c计算xi的位置编码与键xj之间的关联矩阵
- 计算xi和键xj的位置编码之间的关联矩阵。
总而言之
还有很多根据Transformer-XL改进的变异模型都是为了解决长文本的问题,例如Reformer引入了哈希敏感和可逆的Transformer技术减少模型的内存占用。LongFormer等模型