MobileNet V2卷积神经网络
本篇论文是优化了MobileNet V1的版本的卷积神经网络,和resnet神经网络也有部分相似。

首先利用3×3的深度可分离卷积提取特征,然后利用1×1的卷积来扩张通道。用这样的block堆叠起来的MobileNetV1既能减少不小的参数量、计算量,提高网络运算速度,又能的得到一个接近于标准卷积的还不错的结果,看起来是很美好的。
问题
有人在实际使用的时候, 发现深度卷积部分的卷积核比较容易训废掉:训完之后发现深度卷积训出来的卷积核有不少是空的,如下图所示:
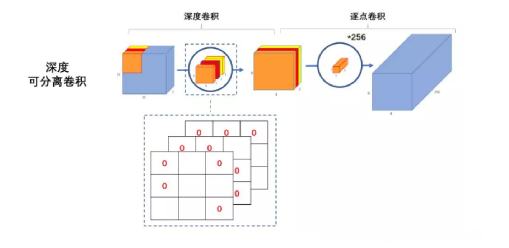
这是怎么回事呢?
作者认为这是ReLU的不起眼的激活函数的锅。
linear bottleneck
我们来看看Rule这个函数都干啥了?
这里我们来看一个实验,假设在2维空间有一组由m个点组成的螺旋线Xm数据(如input),利用随机矩阵T映射到n维空间上并进行ReLU运算.
y=ReLU(T∗Xm)(1.1)
其中,Xm被随机矩阵T映射到了n维空间:
再利用随机矩阵T的逆矩阵T−1,将y映射回2维空间当中:
Xm′=T−1(RuLU(T∗Xm))(1.2)
就是将Xm恢复回来,然后我们来看下面的图。

如上图所示,第一张图是元素图像,当dim=2的时候,我们发现丢失的信息还是比较多的,就剩下了41,但是随着dim增加,保留下来的形式是越来越多的。
这就解释了为什么深度卷积的卷积核有不少是空。发现了问题,我们就能更好地解决问题。针对这个问题,可以这样解决:既然是ReLU导致的信息损耗,将ReLU替换成线性激活函数。
这里还有个问题,我们能将所有的ReLu都替换成线性函数吗?当然不行,那么样不就回到了原来我们讨论的问题,为什么需要激活层。所以我们把最后的那个ReLU6换成Linear。
Expansion layer
现在还有个问题是,深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道。如果来的通道很少的话,DW深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要“扩张”通道。既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征,所以我们的卷积变成这个样子。

也就是说,不管输入通道数是多少,经过第一个PW逐点卷积升维之后,深度卷积都是在相对的更高6倍维度上进行工作。
这样我们的工作就圆满完成啦,利用一个PW进行升维,然后和MobileNet V1 使用DW和PW一起的效果进行神经网络的传递。
MobileNet V2 和 ResNet
这里我们还可以讨论一个问题,MobileNet V2 和 ResNet网络有什么异同点呢?
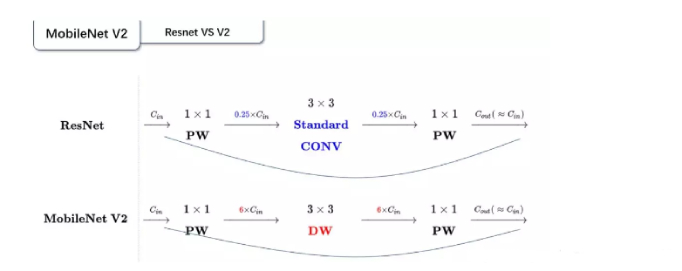
这张图是毕竟能够比较这个问题,我们发现以下
- Resnet是先降低维度,然后利用PW层进行升维度
- MobileNetV2 则是 先升维 (6倍)、卷积、再降维。
MobileNet V2