xgboost是非常常用的机器学习框架,本章我们仅仅从应用角度来讲,xgboost到底能干什么,通过其他文章我们再了解它是怎么做的,这个也比较符合我们的认知过程,能干什么和怎么干。
二分类问题
逻辑回归是在线性回归的基础上通过sigmoid函数将预测值映射到0~1的区间来代表二分类结果的概率。和逻辑回归一样,XGBoost也是采用sigmoid函数来解决二分类问题,即先通过回归树对样本进行预测,得到每棵树的预测结果,然后将其进行累加求和,最后通过sigmoid函数将其映射到0~1的区间代表二分类结果的概率。另外,对于二分类问题,XGBoost的目标函数采用的是类似逻辑回归的logloss,而非最小二乘法。对于二分类的参数主要是以下几种
Objective
该参数用来指定目标函数,XGBoost可以根据该参数判断进行何种学习任务,binary:logistic和binary:logitraw都表示学习任务类型为二分类。binary:logistic输出为概率,binary:logitraw输出为逻辑转换前的输出分数。
eval_metric
该参数用来指定模型的评估函数,和二分类相关的评估函数有:error、logloss和auc。
error:是错误率,也就是预测错误的样本在整个样本中的占比,可以通过error@k的方式制定判断的阈值。
logloss:通过惩罚分类来量化模型的准确性,最大限度减少log loss,等同于最大化模型的准确率。
logloss=−(y∗log(p)+(1−y)∗log(1−p))
p表示模型预测为正样本的概率。
def logloss(true_label, predicted_prob):
if true_label == 1:
return -log(predicted_prob)
else:
return -log(1 - predicted_prob)
这里我们要介绍一下,当使用xgb的时候,我们一般不会对列命名,自动生成的列名就是f1,f2之类的名称。我们怎么给已有的模型添加上列名呢?
当我们dump一个模型的时候一般使用这样的方式;
1. # 输出文本格式的模型(未做特征名称转换)
2. dump_model = bst.dump_model("./dump.raw.txt")
3. # 输出文本格式的模型(完成特征名称转换)
4. dump_model = bst.dump_model("./dump.nice.txt", "./featmap.txt")
5. xgbM.dump_model("xx.model",fmap="xx")
6. plot_importance(xgbM, max_num_features=32, fmap="./featmap.txt")
这里的/featmap.txt就是我们要补充的特征列的名称以及类型。当然在我们绘图的时候也十分必要的添加上这样的属性文件。
接下来的问题就是,这个featmap.txt是什么样的格式呢?
<featureid> <featurename> <q or i or int>\n
中间的是\t分割,featureid是特征的索引号,从0开始,featurename就是你想要把这一列起一个什么样的名字,最后一列q表示连续值,i表示离散值。
多分类问题
XGBoost中解决多分类问题的主要参数如下。
1)num_class:说明在该分类任务的类别数量。
2)objective:该参数中的multi:softmax和multi:softprob均是指定学习任务为多分类。multi:softmax通过softmax函数解决多分类问题。multi:softprob和multi:softmax一样,主要区别在于其输出的是一个ndata*nclass向量,表示样本属于每个分类的预测概率。
3)eval_metric:与多分类相关的评估函数有merror和mlogloss。merror也称多分类错误率,通过判断样本所有分类预测值中预测值最大的分类和样本label是否一致来确定预测是否正确,其计算方式和error相似。mlogloss也是多分类问题中常用的评估指标
回归问题
用XGBoost解决回归问题是很顺理成章的事情,因为XGBoost本身采用的就是回归树,将每棵回归树对样本的预测值相加即为最终预测值。XGBoost支持多种回归模型,包括线性回归、泊松回归、伽马(gamma)回归等,不同的回归模型有不同的目标函数。以下是回归问题中用到的主要参数。
objective
1)reg:linear:线性回归,并非指线性模型(线性模型由booster参数指定),用于数据符合正态分布的回归问题,目标函数为最小二乘。默认采用RMSE
2)reg:logistic:逻辑回归,目标函数为logloss。
3)count:poisson:计数数据的泊松回归。
4)reg:gamma:对数连接函数下的伽马回归。
5)reg:tweedie:对数连接函数下的tweedie回归。
eval_metric
回归问题的评估指标主要有RMSE、MAE,另外还有一些如poisson-nloglikpoisson-nloglik、gamma-nloglik、gamma-deviance、tweedie-nloglik等用于特定回归的评估指标。其中RMSE(Root Mean Square Error,均方根误差),是回归模型中最常采用的评估指标之一,是预测值与真实值偏差的平方和与样本数比值的平方根。指标MAE(Mean Absolute Error,平均绝对误差),是回归模型中常用的评估指标,衡量的是预测值和真实值之间绝对差异的平均值。
排序问题
XGBoost的排序学习采用一种将Lambda-Rank和MART(Multiple Additive Regression Trees)结合的排序算法,即LambdaMART算法。其中MART模型的输出为一组回归树输出的线性组合,而LambdaRank则提供了一种梯度定义方法,针对不同问题可定义不同的梯度。LambdaMART算法将会在第5章详细介绍。XGBoost中排序问题的相关参数如下。
1)objective:该参数用来指定目标函数,rank:pairwise、rank:ndcg和rank:map均表示排序任务。rank:pairwise通过最小化pairwise损失完成排序任务,rank:ndcg是以最大化NDCG为目标实现list-wise排序,而rank:map则以最大化MAP为目标实现list-wise排序。
当目标函数采用rank:pairwise时,默认采用的评估指标为MAP。
2)eval_metric:该参数用来设置模型的评估指标,排序问题的评估指标有map、ndcg、auc
排序问题,后续我们会更加精进的讲解这一部分,这一部分我们想来了解最基本的参数。
其他“语法糖”
我们训练xgb的时候使用的是DMatrix数据结构,但是每次加载如果耗时更长,那么我们可以保存为二进制文件,这样每次加载时间会减少很多。
0. watchlist = [(xgb_train, 'train'), (xgb_test, 'test')]
1.# 存储为二进制文件
2.xgb_test.save_binary('dtest.buffer')
3.
4.# 重新加载数据
5.xgb_test2 = xgb.DMatrix('dtest.buffer')
6.
7.# 用新数据预测
8.preds2 = bst.predict(xgb_test2)
XGBoost支持将CSR、CSC格式的矩阵数据直接加载为DMatrix。
基于历史预测值继续训练
XGBoost支持在历史模型预测值的基础上继续训练,使模型快速达到较高的准确度,节省计算时间。此处的预测值为未进行转化的原始值。
1.import xgboost as xgb
2.import numpy as np
3.from sklearn import datasets
4.from sklearn.model_selection import train_test_split
5.
6.cancer = datasets.load_breast_cancer()
7.X = cancer.data
8.y = cancer.target
9.
10.X_train, X_test, y_train, y_test = train_test_split(X, y ,
test_size = 1/5.,random_state = 8)
11.
12.xgb_train = xgb.DMatrix(X_train, label=y_train)
13.xgb_test = xgb.DMatrix(X_test, label=y_test)
14.
15.
16.watchlist = [(xgb_test,'eval'), (xgb_train,'train')]
17.###
18.# 在初始预测值的基础上开始训练
19.#
20.# 指定训练参数
21.params = {
22. "objective": "binary:logistic",
23. "booster": "gbtree",
24. "eta": 0.1,
25. "max_depth": 5
26.}
27.
28.# 训练模型, 此处num_round设为10
29.bst = xgb.train(params, xgb_train, 10, watchlist )
30.
31.# 通过上述模型对数据集进行预测
32.# 此处output_margin参数设为True, 表示最终输出的预测值为未进行sigmoid转化的原始值
33.pred_train = bst.predict(xgb_train, output_margin=True)
34.pred_test = bst.predict(xgb_test, output_margin=True)
35.
36.# 设置预测值为初始值, 这里设置的初始值需是未转化前的原始值
37.xgb_train.set_base_margin(pred_train)
38.xgb_test.set_base_margin(pred_test)
39.
40.print ('以下是设置初始预测值后的运行结果:')
41.bst = xgb.train( params, xgb_train, 10, watchlist )
显然,设置历史预测值作为初始值训练模型时,模型很快达到了较高的准确度。
自定义目标函数和评估函数
需要注意的是,通过自定义目标函数得到的预测值是模型预测的原始值,不会进行任何转换(如sigmoid转换、softmax转换)。原因不难理解,自定义objective之后,模型并不知道该任务是什么类型的任务,因此也就不会再做转换。
自定义目标函数后,XGBoost内置的评估函数不一定适用。比如用户自定义了一个logloss的目标函数,得到的预测值是没有经过sigmoid转换的,而内置的评估函数默认是经过转换的,因此评估时就会出错。
1.###
2.# 自定义目标函数
3.#
4.import xgboost as xgb
5.import numpy as np
6.from sklearn import datasets
7.from sklearn.model_selection import train_test_split
8.
9.cancer = datasets.load_breast_cancer()
10.X = cancer.data
11.y = cancer.target
12.
13.X_train, X_test, y_train, y_test = train_test_split(X, y ,test_size =
1/5.,random_state = 8)
14.
15.xgb_train = xgb.DMatrix(X_train, label=y_train)
16.xgb_test = xgb.DMatrix(X_test, label=y_test)
17.
18.
19.# 因为要自定义目标函数, 此处objective不再指定
20.
21.params = {
22. "booster": "gbtree",
23. "eta": 0.1,
24. "max_depth": 5
25.}
26.num_round = 50
27.
28.
29.# 自定义目标函数logloss, 给定预测值, 返回一阶、二阶梯度
30.def logregobj(preds, dtrain):
31. labels = dtrain.get_label()
32. preds = 1.0 / (1.0 + np.exp(-preds))
33. grad = preds - labels
34. hess = preds * (1.0-preds)
35. return grad, hess
36.
37.
38.# 用户自定义评估函数, 返回指标名称和结果
39.def evalerror(preds, dtrain):
40. labels = dtrain.get_label()
41. # 因为是未进行sigmoid转换的, 因此以0作为分类阈值
42. return 'error', float(sum(labels != (preds > 0.0))) / len(labels)
43.
44.# 通过自定义目标函数进行训练
45.bst = xgb.train(params, xgb_train, num_round, watchlist, obj=logregobj,
feval=evalerror)
因为模型产出的预测值preds为原始值,所以在自定义目标函数内部对preds进行了sigmoid转换,转换之后再计算一阶、二阶梯度.
xgboost 外存版本
xgboost是优先将内存加载到内存的,但是如果内存不够怎么办呢?xgb会将数据存储在外存中。
XGBoost的外存版本和内存版本在使用上没什么不同,唯一的区别是在文件名称的格式上。外存版本采用下面的格式:
filename#cacheprefix
filename表示需要加载的LibSVM格式的文件名称(目前外存版本只支持LibSVM文件格式),cacheprefix是外存缓存文件的路径。代码如下:
xgb_train = xgb.DMatrix('./train.data#dtrain.cache')
外存模式也可以用于分布式版本,只需将数据路径设置为如下格式:
data = "hdfs://path-to-data/#dtrain.cache"
XGBoost会将数据缓存到本地的临时文件夹,因此可以直接使用dtrain.cache缓存到当前目录
通过前n棵树进行预测
默认情况下,XGBoost会使用模型中所有决策树进行预测。在某些应用场景下,可以通过指定参数ntree_limit实现只使用前n棵树(非整个模型)进行预测,如下:
1.xgb_train = xgb.DMatrix(X_train, label=y_train)
2.xgb_test = xgb.DMatrix(X_test, label=y_test)
3.
4.params = {
5. "objective": "binary:logistic",
6. "booster": "gbtree",
7. "eta": 0.1,
8. "max_depth": 5
9.}
10.num_round = 50
11.
12.
13.watchlist = [(xgb_test,'eval'), (xgb_train,'train')]
14.
15.bst = xgb.train(params, xgb_train, num_round, watchlist)
16.
17.print ('通过前n棵树进行预测')
18.# 使用前10棵树进行预测
19.label = xgb_test.get_label()
20.pred1 = bst.predict(xgb_test, ntree_limit=10)
21.# 默认情况使用所有决策树预测
22.pred2 = bst.predict(xgb_test)
23.print ('前10棵树预测值AUC为:%f' % roc_auc_score(y_test,pred1))
24.print ('所有树预测值AUC为:%f' % roc_auc_score(y_test,pred2))
个性化归因
在实际应用场景中,除了需要评估特征对模型的重要性之外,有时还需要评估特征对于单个样本的贡献值,即特征对于样本预测值的影响有多大。例如,银行对用户借贷是否逾期进行预测,除了希望得到预测结果外,分析师可能更想知道模型是如何判定一个样本会有逾期风险的。在0.81及以上版本的XGBoost中,提供了两种单样本的模型归因方法:SHAP和Saabas,这两种方法的实现原理会在第5章中介绍。本节主要聚焦于如何应用该归因方法。
和特征重要性类似,首先需要训练一个模型。模型训练好之后,即可通过归因方法计算预测样本的特征贡献度。以SHAP方法为例,其调用方法非常简单,只需在执行predict函数时将参数pred_contribs设置为True即可,代码如下:
1.# SHAP
2.pred_contribs = bst.predict(xgb_test, pred_contribs=True)
此时predict函数的返回值不再是数据集的预测值,而是每个样本的各个特征对该样本的贡献值。返回矩阵的行数为数据集的样本数量,列数则比特征总数量多一列。其中前m(特征数量)列为各个特征对该样本的贡献值,最后一列为偏置项(Bias)。偏置项可以理解为在没有任何特征的情况下每个预测样本的基础分,一般为所有样本真实值的均值。
XGBoost还支持SHAP方法对任意两两交叉特征贡献值的评估,只需将参数pred_interactions置为True即可.
pred_interactions = bst.predict(xgb_test, pred_interactions=True)
此时的返回结果中,每个样本由一个二维矩阵解释,矩阵的行数和列数均为31,矩阵中的值Matrix[i][j]表示第i个特征和第j个特征交叉对该样本的贡献值。矩阵中所有值的和即为样本未转换前的预测值。
除了SHAP方法外,XGBoost还支持另外一种单样本归因方法Sabbas。相比SHAP方法,Sabbas实现简单、容易理解,但其弊端也是不可忽视的,即容易产生不一致的问题.
approx_contribs = bst.predict(xgb_test, pred_contribs=True, approx_contribs=True)
模型可视化
xgboost.plot_tree(booster, fmap='', num_trees=0, rankdir='UT', ax=None, **kwargs)
booster为训练好的模型,可以是Booster或XGBModel实例,fmap是特征索引与特征名称的映射文件,num_trees是目标树的序号。rankdir是通过graph_attr传给graphiz的参数,用于设置图形布局的方向,例如rankdir=‘LR’,表示图形自左至右排列;rankdir=‘RL’,表示图形自右至左排列;默认情况下为’UT’,即图形从上到下排列。ax表示目标axes实例,如果ax为None,则会创建新的figure和axes。kwargs为传给to_graphviz的其他参数。
单调性约束
这一节比较有意思, 这里主要解决的问题是,某些场景下,我真实的知道某些特征和预测值是单调递增或者递减的,这个时候想让模型保证这个约束进行学习,这个时候应该怎么办呢?
params_constrained = params.copy()
params_constrained['monotone_constraints'] = (1,-1)
model_with_constraints = xgb.train(params_constrained, dtrain,
num_boost_round = 1000, evals = evallist,
early_stopping_rounds = 10)
这里的monotone_constraints表达的是第一个特征与预测值成正相关,第二个特征与预测值成负相关。
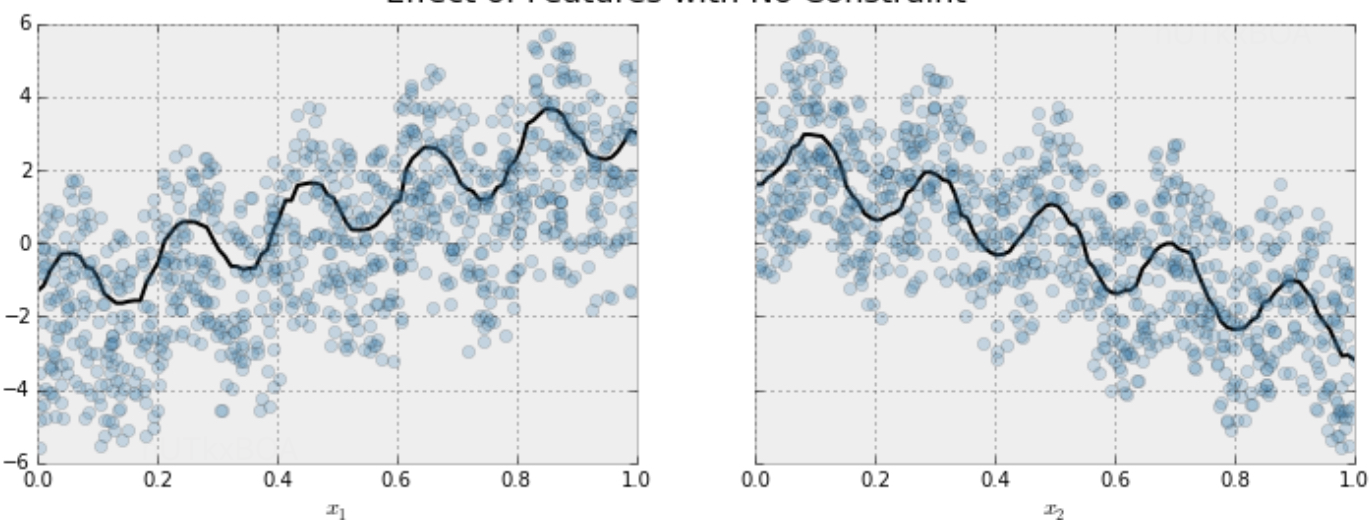

如何实现
这个时候你可能会有一点疑问,这个厉害的功能是如何实现的呢? 其实实现起来是十分简单的,就是分裂子树的时候需要考虑左边的指定的特征要小于右边的,并且左边的预测值要小于右边的预测值,这样就实现了单调性的要求。