LSTM神经网络
RNN的结构
开始为了我们能够对比出两种网络的异同,我们还是给出一个泛化的简图。

可以清楚看到整个网络虽然叠加多个神经元,但是每个神经元的处理逻辑单一,很容易将信息丢失。
LSTM
这个时候我们来进入LSTM的认识。
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
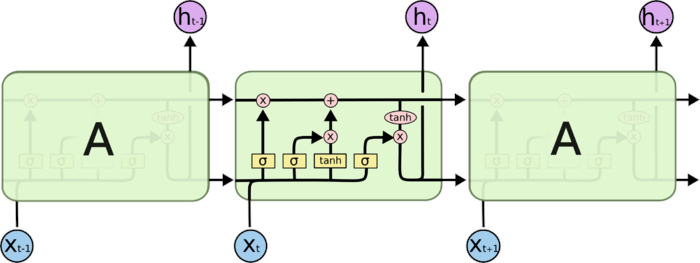
上面的图并不陌生,很多博客都能见得到,十分权威的一个图。
不必担心这里的细节。我们会一步一步地剖析 LSTM 解析图。现在,我们先来熟悉一下图中使用的各种元素的图标。

LSTM核心思想
LSTM的关键在于细胞的状态整个(绿色的图表示的是一个cell),和穿过细胞的那条水平线.
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
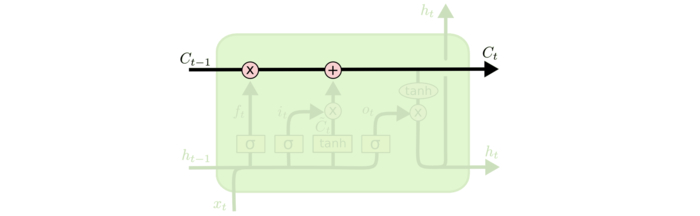
若只有上面的那条水平线是没办法实现添加或者删除信息的。而是通过一种叫做 门(gates) 的结构来实现的。这是保存有用信息的方式。这个就能理解为什么在RNN中一个简单的结构,信息只有一个去处,就很容易导致信息丢失和冗余。
门 可以实现选择性地让信息通过,主要是通过一个 sigmoid 的神经层 和一个逐点相乘的操作来实现的。
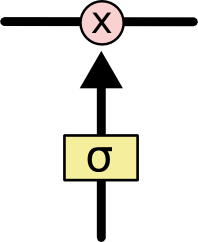
sigmoid 层输出(是一个向量)的每个元素都是一个在 0 和 1 之间的实数,表示让对应信息通过的权重(或者占比)。比如, 0 表示“不让任何信息通过”, 1 表示“让所有信息通过”。
"门"是出路
下面我那就要认识LSTM中的门的概念,当然门的作用就是让一些人进来,一些人不要进来。LSTM中的门也是同样的作用。
遗忘门
写过外包的都会了解,外包的核心就是增删改查,在神经网络中,遗忘门就是起到这个作用,就是想让我们忘记一些东西。 说白了就是 不让你记的东西,不要记 记了也不会考。
该门会读取h{t−1}和xt,输出一个在 0到 1之间的数值给每个在细胞状态C{t−1}中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
这里我们用自然语言处理的例子来举例比较容易明白。。
基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
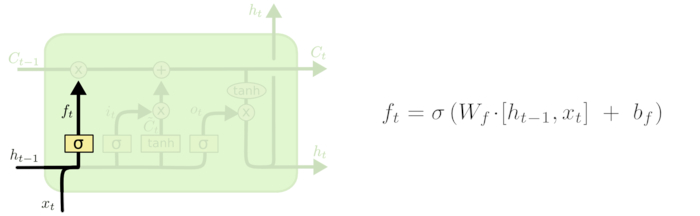
其中ht−1表示的是上一个cell的输出,xt表示的是当前细胞的输入。σ表示sigmod函数
输入门
下一步是决定让多少新的信息加入到 cell 状态 中来。实现这个需要包括两个 步骤:首先,一个叫做“input gate layer ”的 sigmoid 层决定哪些信息需要更新;一个 tanh 层生成一个向量,也就是备选的用来更新的内容,C^t 。在下一步,我们把这两部分联合起来,对 cell 的状态进行一个更新。
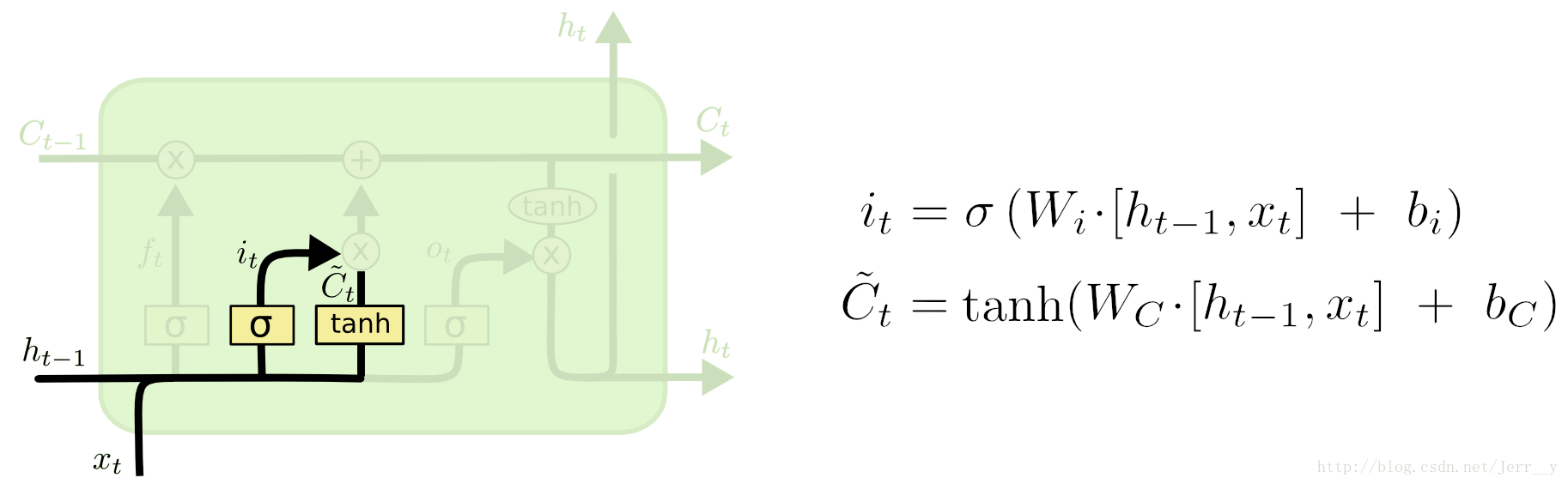
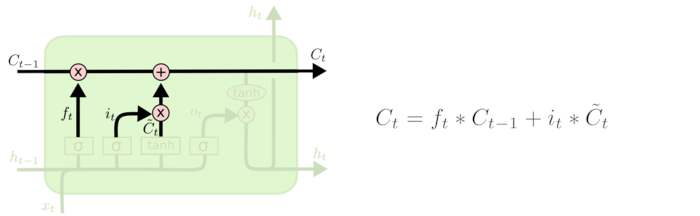
现在是更新旧细胞状态的时间了,Ct−1更新为Ct。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
我们把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it∗C~t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。
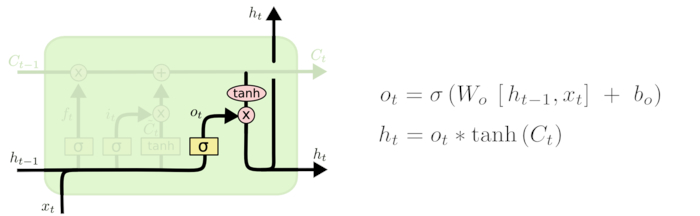
输出门
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
GRU
LSTM比较有名的变体就是GRU了,我们也来简单看看这个网络长成什么样子。。
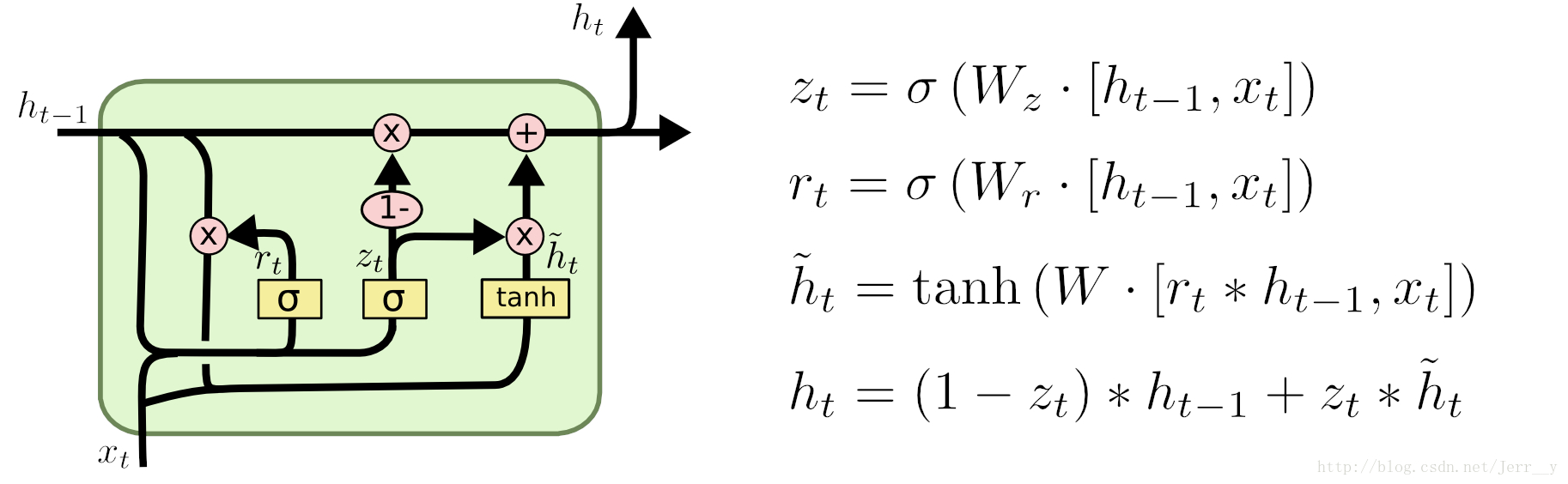
其中, rt表示重置门,zt表示更新门。重置门决定是否将之前的状态忘记。(作用相当于合并了 LSTM 中的遗忘门和传入门)当rt趋于0的时候,前一个时刻的状态信息h{t−1}会被忘掉,隐藏状态ht会被重置为当前输入的信息。更新门决定是否要将隐藏状态更新为新的状态ht(作用相当于 LSTM 中的输出门) 。
这里将整个过程进行一次比较详细的讲解,首先我们将公式中的一些符号做一些解释,[]表示连接两个变量,δ代表sigmod函数。
首先,我们先通过上一个传输下来的状态ht−1和当前的状态xt计算门控信息,也就是公式中的zt 和 rt.得到门控信号之后,首先使用重置门控来得到“重置”之后的数据也就是公式中的ht,在将ht和ht−1,重新合并成ht,这样我们就完成了一次GRU的操作,生产了一个输出一个隐状态。