之前我们讲了很多xgboost的特性用法等等,接下来我们需要回答的一个问题是xgboost能够与其他模型融合吗?怎么融合?
xgboost与LR融合
一个训练样本在输人 GBDT 的某一子树后,会根据每个节点的规则最终落人 某一叶子节点,把该叶子节点置为 1,其他叶子节点置为 0, 所有叶子节点组成 的向量即形成了该棵树的特征向量,把 GBDT 所有子树的特征向量连接起来,即 形成了后续 LR 模型输人的离散型特征向量。
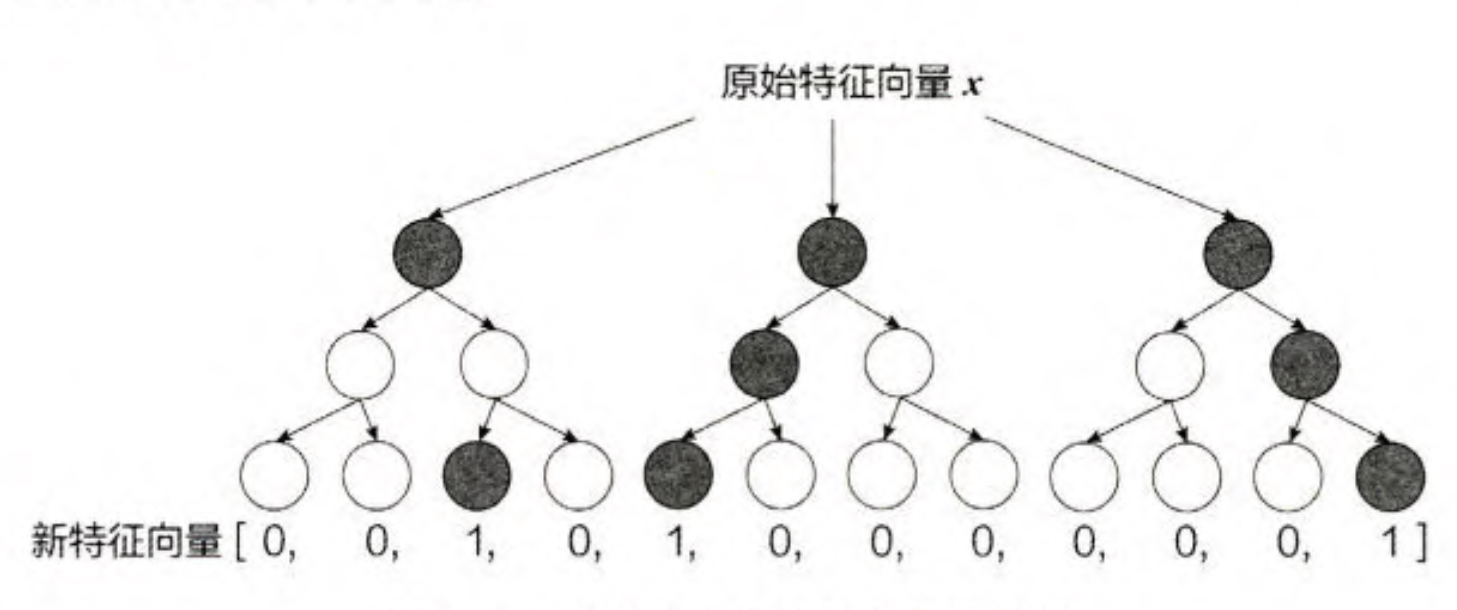
事实上,决策树的深度决定了特征交叉的阶数。如果决策树的深度为 4, 则 通过 3 次节点分裂,最终的叶节点实际上是进行三阶特征组合后的结果,如此强 的特征组合能力显然是FM系的模型不具备的。但GBDT容易产生过拟合,以及 GBDT 的特征转换方式实际上丢失了大量特征的数值信息,因此不能简单地说 GBDT 的特征交叉能力强,效果就比 FFM 好,在模型的选择和调试上,永远都 是多种因素综合作用的结果。
xgboost和DNN模型融合
当我们使用xgboost的时候经常会发现,很多场景下我们只用xgboost模型的效果就能够达到一个最佳的效果,使用深度神经网络反而没有xgboost的效果好,这个经常让我们十分头疼,我想做点更nb的东西逻辑就这么难吗? 其实个人认为xgboost效果的提升的答案可能不是深度学习网络,在我们做极致的特征工程的基础上,其实很难再组合更高阶的特征从而提升模型,反而一个有效的手段是通过融合的手段能够提升xgboost的效果,下面我就说下DNN和xgboost如何融合,以及融合后会能够学习到什么样的知识。
现在我们的任务是流量预测,至于什么流量就不需要管啦。看起来是一个典型的回归问题,对于经常做业务的小伙伴肯定第一时间想到的通过做各种同期特征,最后通过xgboost做一个回归模型。那么问题来啦,我们能够将这个问题做的更加精妙一些吗?
我们尝试通过以下的模型架构实现这个预测问题。
- 首先我们需要做大量的特征工程,得到x1,x2...这样的特征。
- 原来我们的思路是将特征直接灌倒xgb模型中,现在新的做法是,我们先通过DNN预测接下来的流量概率分布。[0.1,0.3,0.5,0.1],代表流量落到[1,5]之间的概率,以及[6,10]之间的概率等等。通过DNN就学习到了一个先验的流量分布,当然这里带来了另一个好处,这个概率分布如果满足一定要求是可以独立在业务中使用,丰富业务逻辑的。
- 将学习到的特征分布与原始的特征做融合重新灌入到xgb中,来预测结果。
这个时候你可能会有一个问题,为什么这样的操作能够提升模型的精度呢?这里我从感性的角度讲一下这个问题。
通过DNN我们能够学习到这个流量的一个概率分布,这其实是一个先验的知识,当然这个分布可能准确率不高(但是一定比蒙的要准)。通过这样先验分布,其实为我们继续做这个流量的任务提供了更多的特征。而且通过xgboost对残差敏感的特性,我们是可以学出来诸如这样的结论。例如在DNN模型预测的流量[1,5]之间的值,最后的真值往往在[6,10]之间。从某一个方面我们是通过原始特征来修正了错误的分布,从而比我们直接使用原始特征来预测的效果会好一些。
通过上面的讲解,我们是不是将我们手头的项目做了一定的包装,同时在某些特殊业务场景下还没有失去可解释性。
xgboost融合LR
后续我们在来介绍为什么这里融合DNN不太好。
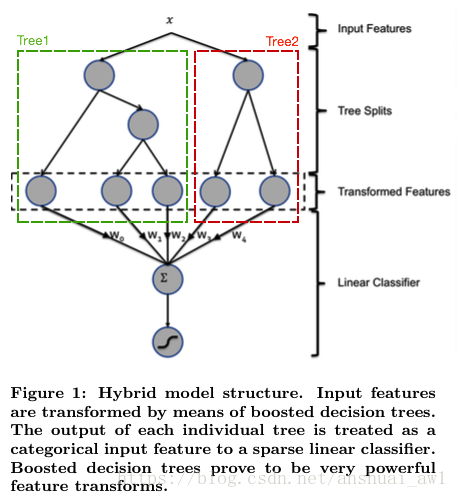
这里我们要参考一个论文,Facebook 在 2014年的论文ractical Lessons from Predicting Clicks on Ads at Facebook。这篇论文中讲解了如何通过xgb和LR的融合最终提升的3%的效果。
- 先通过xgboot在现有的原始特征中学习,这里很多人就迷糊啦,难道我们要通过xgboot输出概率分布,然后输入的DNN(你开窍啦),然而并不是这样,这样的模型可解释性就瞬间丢失啦。
- 大家都知道我们通过xgboost学到的是怎么样知识呢? 以我的理解是在原始特征中找到各种各样的逻辑关系的交叉,但是这种交叉怎么以数据的形式灌输到LR模型中。
- 论文中提到的是使用xgb树结构的特点,每个样本在每棵树的叶子节点的编号做onehot,然后合并原始特征放到LR做训练。
这里你会问,我靠,这能学习到啥特征?感觉完全是在扯淡吧? 确实是这样,我的第一感觉也是这样的,但是后来我想了一下,其实最后叶子节点的索引值其实是xgb某种逻辑关系组合后的结果,这似乎就是某种非线性转换。所以这就也想明白啦,为什么将这些特征直接放到LR中,其实是我们在前面对数据做了非线性的转换,以及线性特征,最终直接放到LR做拟合就好啦。LR其实就是一个没有非线性变换的神经网络嘛。这样就既保留了可解释性也提升了模型的精准度。
总而言之
最后做个总结,我们发现我们的模型之间其实是可以做这样那样的融合的,在我们充分了解模型的特性后,就可以把他们按照业务形态的要求,做各种层面的结合,例如可解释性的业务,我们就尽量用可解释模型收底,让不可解释的变换以特征的形式灌入到模型中。当然对于某些完全不要求可解释性的业务,那就是大模型直接上,就是干。。。。